CART算法和回归树
回归树的构建
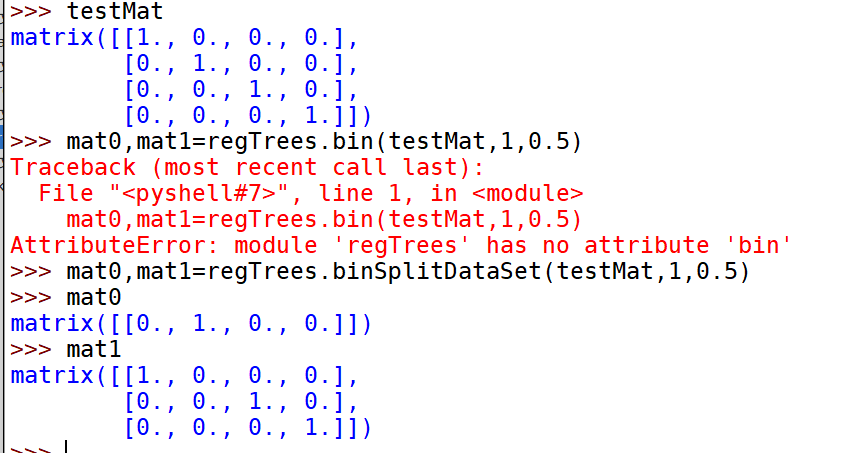
from numpy import *def loadDataSet(fileName): #general function to parse tab -delimited floatsdataMat = [] #assume last column is target valuefr = open(fileName)for line in fr.readlines():curLine = line.strip().split('\t')fltLine = list(map(float,curLine)) #map all elements to float()dataMat.append(fltLine)return dataMatdef binSplitDataSet(dataSet, feature, value):mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:]mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:]return mat0,mat1def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#assume dataSet is NumPy Mat so we can array filteringfeat, val = chooseBestSplit(dataSet, leafType, errType, ops)#choose the best splitif feat == None: return val #if the splitting hit a stop condition return valretTree = {}retTree['spInd'] = featretTree['spVal'] = vallSet, rSet = binSplitDataSet(dataSet, feat, val)retTree['left'] = createTree(lSet, leafType, errType, ops)retTree['right'] = createTree(rSet, leafType, errType, ops)return retTree
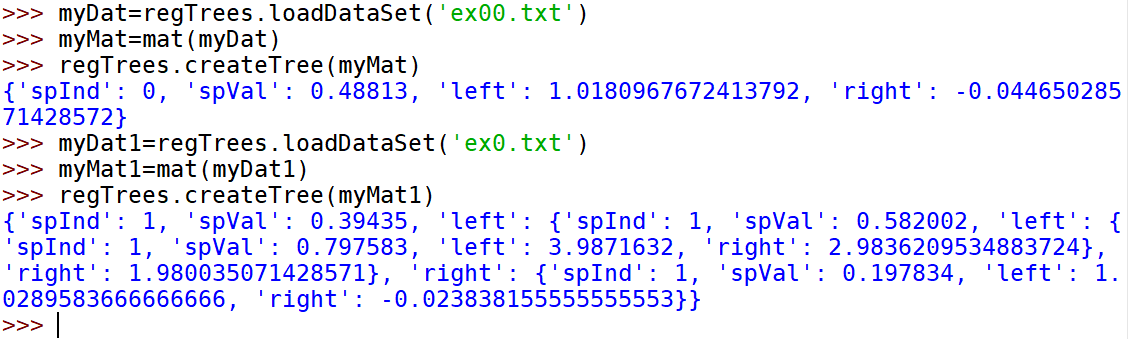
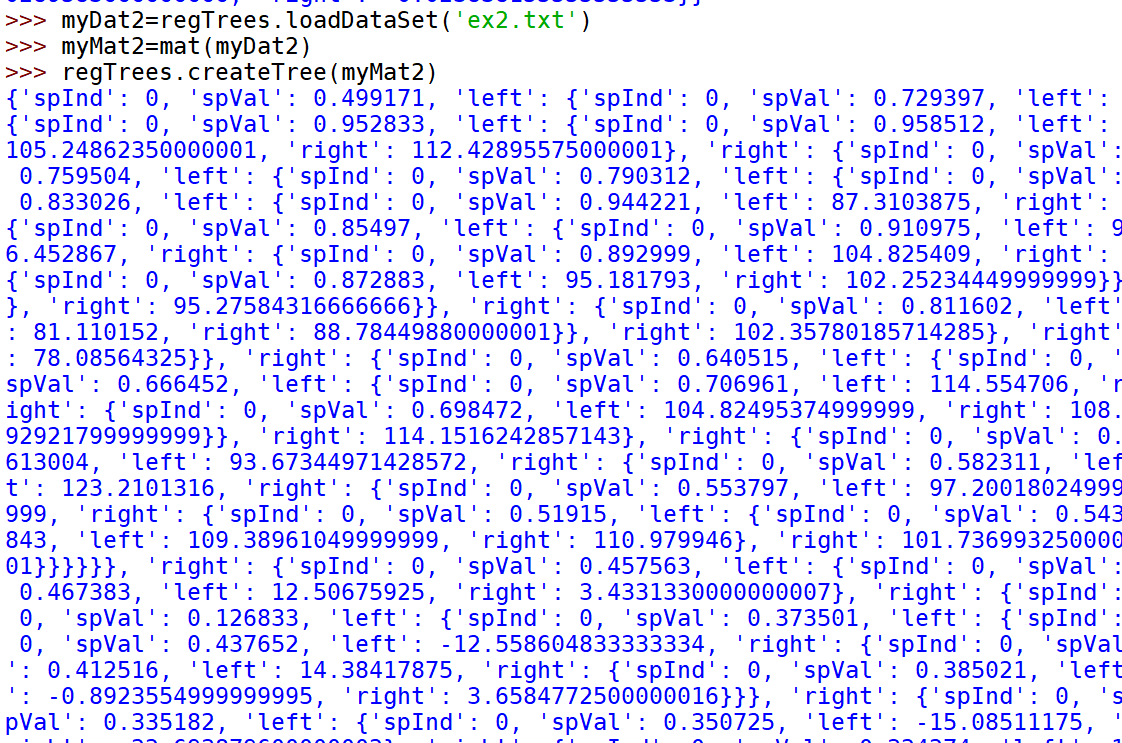
def regLeaf(dataSet):#returns the value used for each leafreturn mean(dataSet[:,-1])def regErr(dataSet):return var(dataSet[:,-1]) * shape(dataSet)[0]def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):tolS = ops[0]; tolN = ops[1]#if all the target variables are the same value: quit and return valueif len(set(dataSet[:,-1].T.tolist()[0])) == 1: #exit cond 1return None, leafType(dataSet)m,n = shape(dataSet)#the choice of the best feature is driven by Reduction in RSS error from meanS = errType(dataSet)bestS = inf; bestIndex = 0; bestValue = 0for featIndex in range(n-1):for splitVal in set(dataSet[:,featIndex].T.tolist()[0]):mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continuenewS = errType(mat0) + errType(mat1)if newS < bestS:bestIndex = featIndexbestValue = splitValbestS = newS#if the decrease (S-bestS) is less than a threshold don't do the splitif (S - bestS) < tolS:return None, leafType(dataSet) #exit cond 2mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): #exit cond 3return None, leafType(dataSet)return bestIndex,bestValue#returns the best feature to split on#and the value used for that split
已完成对回归树的构建,下面将进行树剪枝以达到更好的预测结果(尽量避免“过拟合”)
树剪枝
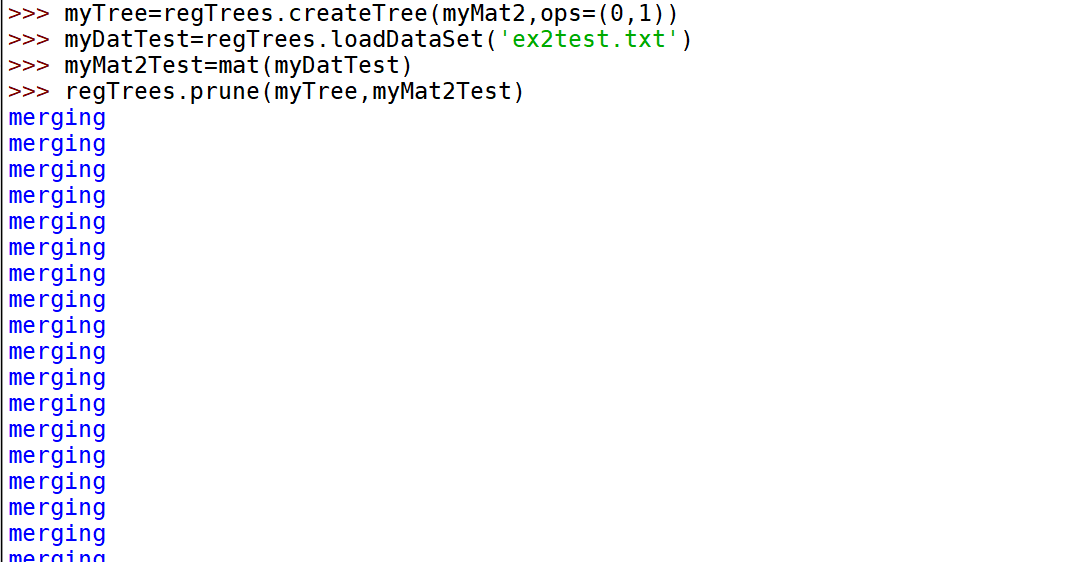
以上的例子说明tols对误差条件很敏感。产生了过多的叶节点。
def isTree(obj):return (type(obj).__name__=='dict')def getMean(tree):if isTree(tree['right']): tree['right'] = getMean(tree['right'])if isTree(tree['left']): tree['left'] = getMean(tree['left'])return (tree['left']+tree['right'])/2.0def prune(tree, testData):if shape(testData)[0] == 0: return getMean(tree) #if we have no test data collapse the treeif (isTree(tree['right']) or isTree(tree['left'])):#if the branches are not trees try to prune themlSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])if isTree(tree['left']): tree['left'] = prune(tree['left'], lSet)if isTree(tree['right']): tree['right'] = prune(tree['right'], rSet)#if they are now both leafs, see if we can merge themif not isTree(tree['left']) and not isTree(tree['right']):lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) +\sum(power(rSet[:,-1] - tree['right'],2))treeMean = (tree['left']+tree['right'])/2.0errorMerge = sum(power(testData[:,-1] - treeMean,2))if errorMerge < errorNoMerge:print("merging")return treeMeanelse: return treeelse: return tree
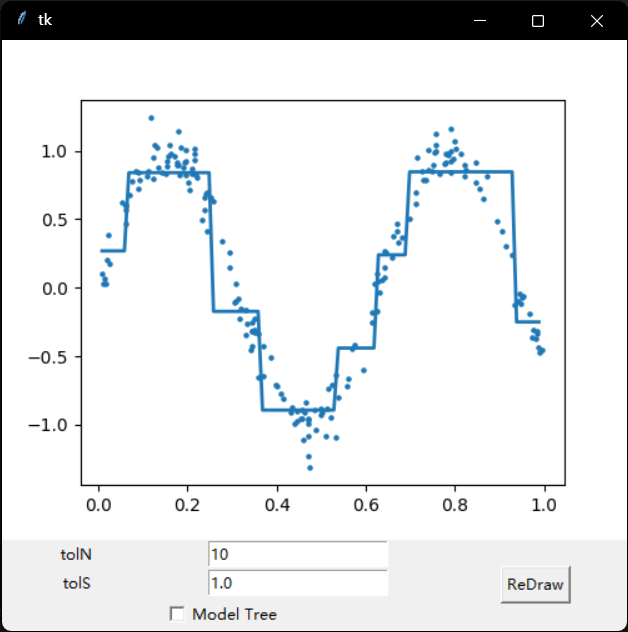
模型树
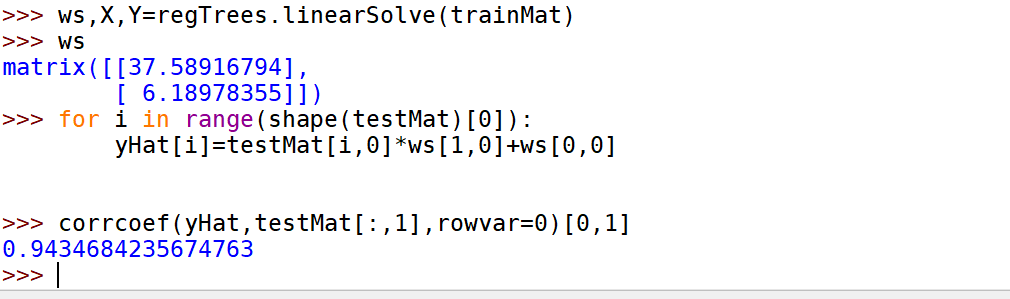
def linearSolve(dataSet): #helper function used in two placesm,n = shape(dataSet)X = mat(ones((m,n))); Y = mat(ones((m,1)))#create a copy of data with 1 in 0th postionX[:,1:n] = dataSet[:,0:n-1]; Y = dataSet[:,-1]#and strip out YxTx = X.T*Xif linalg.det(xTx) == 0.0:raise NameError('This matrix is singular, cannot do inverse,\n\try increasing the second value of ops')ws = xTx.I * (X.T * Y)return ws,X,Ydef modelLeaf(dataSet):#create linear model and return coeficientsws,X,Y = linearSolve(dataSet)return wsdef modelErr(dataSet):ws,X,Y = linearSolve(dataSet)yHat = X * wsreturn sum(power(Y - yHat,2))

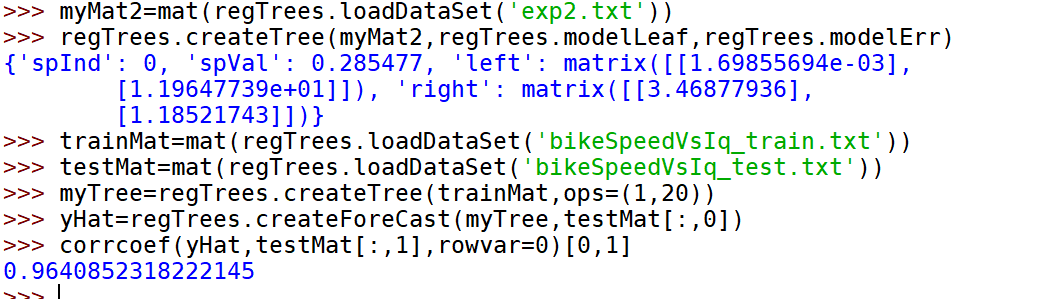
示例:树回归与标准回归的比较
def regTreeEval(model, inDat):return float(model)def modelTreeEval(model, inDat):n = shape(inDat)[1]X = mat(ones((1,n+1)))X[:,1:n+1]=inDatreturn float(X*model)def treeForeCast(tree, inData, modelEval=regTreeEval):if not isTree(tree): return modelEval(tree, inData)if inData[tree['spInd']] > tree['spVal']:if isTree(tree['left']): return treeForeCast(tree['left'], inData, modelEval)else: return modelEval(tree['left'], inData)else:if isTree(tree['right']): return treeForeCast(tree['right'], inData, modelEval)else: return modelEval(tree['right'], inData)def createForeCast(tree, testData, modelEval=regTreeEval):m=len(testData)yHat = mat(zeros((m,1)))for i in range(m):yHat[i,0] = treeForeCast(tree, mat(testData[i]), modelEval)return yHat


若有收获,就点个赞吧
0 人点赞
