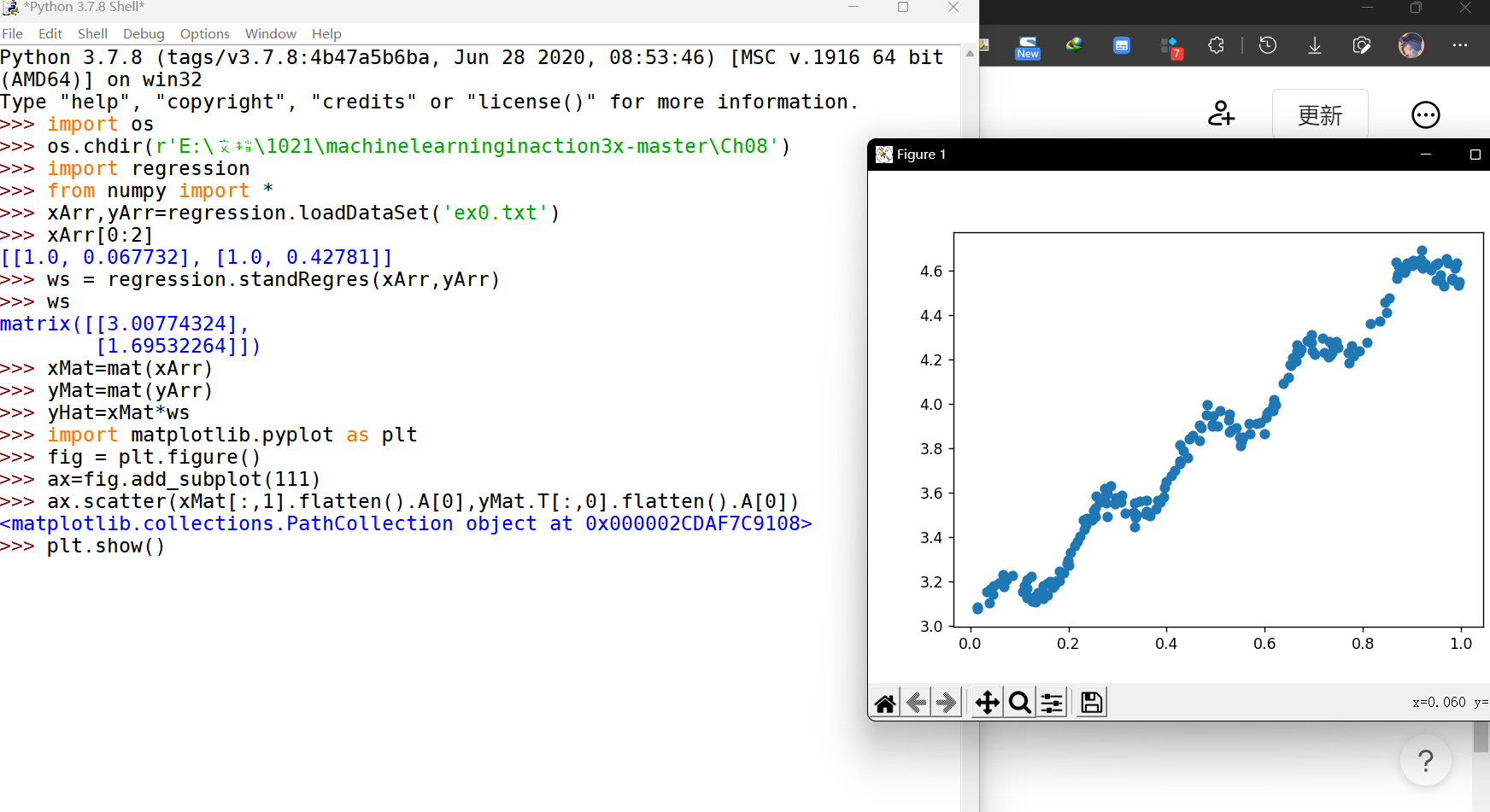
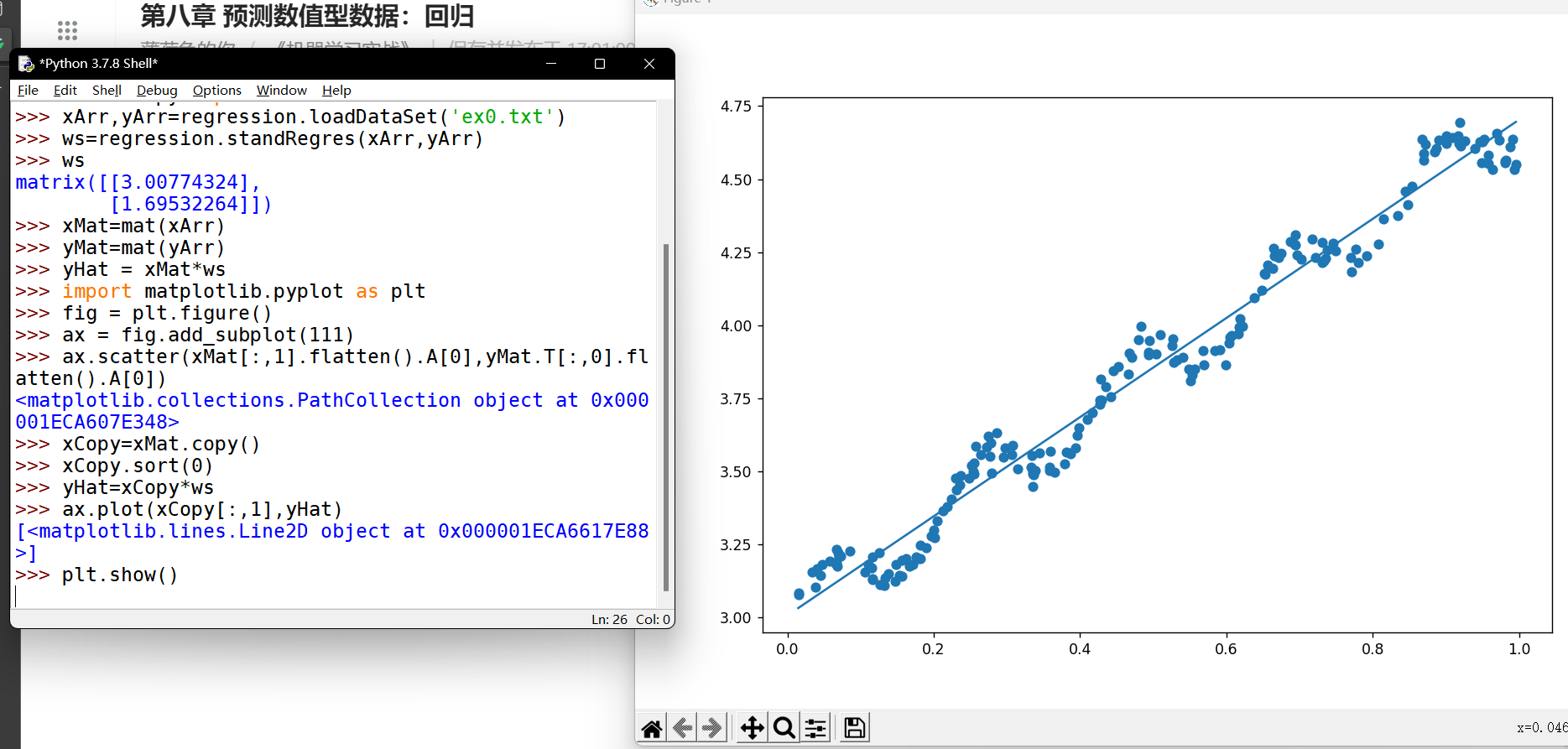
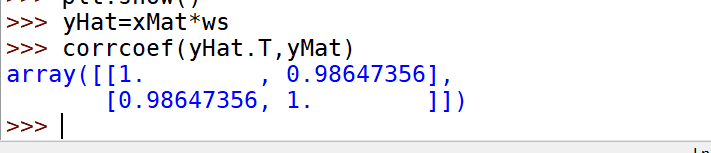
from numpy import *def loadDataSet(fileName): #general function to parse tab -delimited floatsnumFeat = len(open(fileName).readline().split('\t')) - 1 #get number of fieldsdataMat = []; labelMat = []fr = open(fileName)for line in fr.readlines():lineArr =[]curLine = line.strip().split('\t')for i in range(numFeat):lineArr.append(float(curLine[i]))dataMat.append(lineArr)labelMat.append(float(curLine[-1]))return dataMat,labelMatdef standRegres(xArr,yArr):xMat = mat(xArr); yMat = mat(yArr).TxTx = xMat.T*xMatif linalg.det(xTx) == 0.0:print("This matrix is singular, cannot do inverse")returnws = xTx.I * (xMat.T*yMat)return ws
局部加权线性回归
(根据数据来局部调整预测)
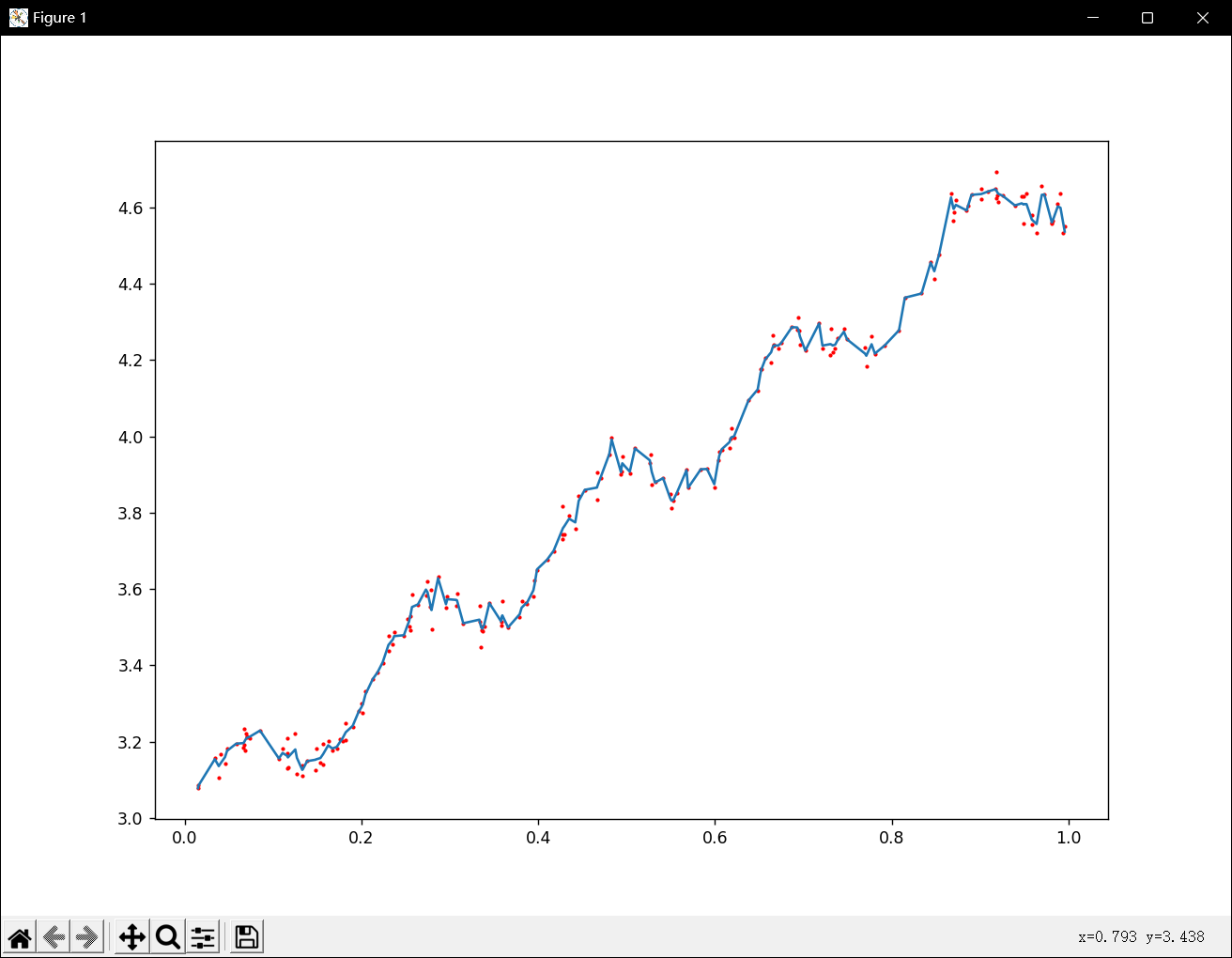
def lwlr(testPoint,xArr,yArr,k=1.0):xMat = mat(xArr); yMat = mat(yArr).Tm = shape(xMat)[0]weights = mat(eye((m)))for j in range(m): #next 2 lines create weights matrixdiffMat = testPoint - xMat[j,:] #weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2))xTx = xMat.T * (weights * xMat)if linalg.det(xTx) == 0.0:print("This matrix is singular, cannot do inverse")returnws = xTx.I * (xMat.T * (weights * yMat))return testPoint * wsdef lwlrTest(testArr,xArr,yArr,k=1.0): #loops over all the data points and applies lwlr to each onem = shape(testArr)[0]yHat = zeros(m)for i in range(m):yHat[i] = lwlr(testArr[i],xArr,yArr,k)return yHat
缩减系数来理解数据
当特征大于样本数量,则无法再计算,因为此时矩阵为非满秩矩阵,计算逆会出现问题
岭回归
通过加入对角线为1其余为0的单位矩阵的系数倍数使得矩阵非奇异。
能够减少不重要的参数。
def ridgeRegres(xMat,yMat,lam=0.2):xTx = xMat.T*xMatdenom = xTx + eye(shape(xMat)[1])*lamif linalg.det(denom) == 0.0:print("This matrix is singular, cannot do inverse")returnws = denom.I * (xMat.T*yMat)return wsdef ridgeTest(xArr,yArr):xMat = mat(xArr); yMat=mat(yArr).TyMean = mean(yMat,0)yMat = yMat - yMean #to eliminate X0 take mean off of Y#regularize X'sxMeans = mean(xMat,0) #calc mean then subtract it offxVar = var(xMat,0) #calc variance of Xi then divide by itxMat = (xMat - xMeans)/xVarnumTestPts = 30wMat = zeros((numTestPts,shape(xMat)[1]))for i in range(numTestPts):ws = ridgeRegres(xMat,yMat,exp(i-10))wMat[i,:]=ws.Treturn wMat
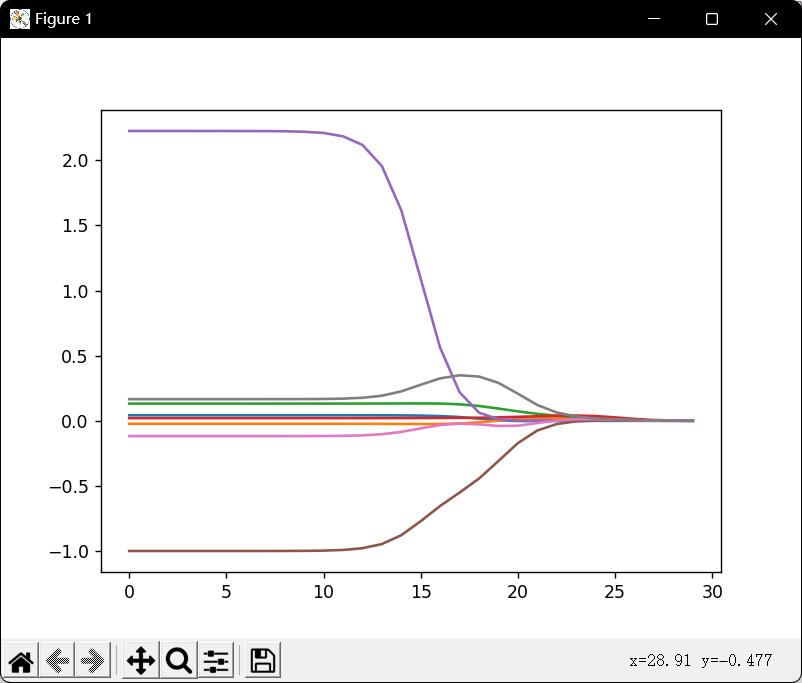
前向逐步线性回归
def stageWise(xArr,yArr,eps=0.01,numIt=100):xMat = mat(xArr); yMat=mat(yArr).TyMean = mean(yMat,0)yMat = yMat - yMean #can also regularize ys but will get smaller coefxMat = regularize(xMat)m,n=shape(xMat)returnMat = zeros((numIt,n)) #testing code removews = zeros((n,1)); wsTest = ws.copy(); wsMax = ws.copy()for i in range(numIt):print(ws.T)lowestError = inf;for j in range(n):for sign in [-1,1]:wsTest = ws.copy()wsTest[j] += eps*signyTest = xMat*wsTestrssE = rssError(yMat.A,yTest.A)if rssE < lowestError:lowestError = rssEwsMax = wsTestws = wsMax.copy()returnMat[i,:]=ws.Treturn returnMat
权衡偏差和方差
示例:预测乐高玩具套装的价格
获取数据
from time import sleepimport jsonimport urllib.requestdef searchForSet(retX, retY, setNum, yr, numPce, origPrc):sleep(10)myAPIstr = 'AIzaSyD2cR2KFyx12hXu6PFU-wrWot3NXvko8vY'searchURL = 'https://www.googleapis.com/shopping/search/v1/public/products?key=%s&country=US&q=lego+%d&alt=json' % (myAPIstr, setNum)pg = urllib.request.urlopen(searchURL)retDict = json.loads(pg.read())for i in range(len(retDict['items'])):try:currItem = retDict['items'][i]if currItem['product']['condition'] == 'new':newFlag = 1else: newFlag = 0listOfInv = currItem['product']['inventories']for item in listOfInv:sellingPrice = item['price']if sellingPrice > origPrc * 0.5:print("%d\t%d\t%d\t%f\t%f" % (yr,numPce,newFlag,origPrc, sellingPrice))retX.append([yr, numPce, newFlag, origPrc])retY.append(sellingPrice)except: print('problem with item %d' % i)def setDataCollect(retX, retY):searchForSet(retX, retY, 8288, 2006, 800, 49.99)searchForSet(retX, retY, 10030, 2002, 3096, 269.99)searchForSet(retX, retY, 10179, 2007, 5195, 499.99)searchForSet(retX, retY, 10181, 2007, 3428, 199.99)searchForSet(retX, retY, 10189, 2008, 5922, 299.99)searchForSet(retX, retY, 10196, 2009, 3263, 249.99)

若有收获,就点个赞吧
0 人点赞
