测试数据科学家聚类技术的40个问题(能力测验和答案)(上)
2017-03-23AI科技大本营介 绍
创造出具有自我学习能力的机器——人们的研究已经被这个想法推动了十几年。如果要实现这个梦想的话,无监督学习和聚类将会起到关键性作用。但是,无监督学习在带来许多灵活性的同时,也带来了更多的挑战。
在从尚未被标记的数据中得出见解的过程中,聚类扮演着很重要的角色。它将相似的数据进行分类,通过元理解来提供相应的各种商业决策。
在这次能力测试中,我们在社区中提供了聚类的测试,总计有1566人注册参与过该测试。如果你还没有测试过,通过阅读下面的文章,你可以统计一下自己能正确答对多少道题。
总结果
下面是分数的分布情况,可以帮你评估你的表现:
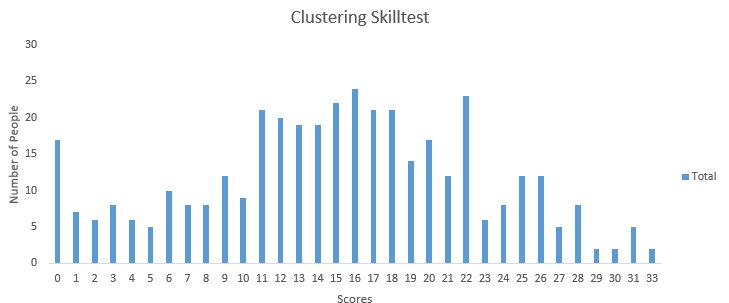
你也可以通过访问这里来查看自己的成绩(https://datahack.analyticsvidhya.com/contest/clustering-skilltest/lb)。超过390个人参加了测试,最高分数是33分。下面是对分数分布的部分统计。
总分布:
平均分:15.11
中位数:15
模型分数:16
相关资源:
An Introduction toClustering and different methods of clustering
https://www.analyticsvidhya.com/blog/2016/11/an-introduction-to-clustering-and-different-methods-of-clustering/Getting yourclustering right (Part I)
https://www.analyticsvidhya.com/blog/2013/11/getting-clustering-right/Getting yourclustering right (Part II)
https://www.analyticsvidhya.com/blog/2013/11/getting-clustering-right-part-ii/
Questions & Answers
Q1. 电影推荐系统是以下哪些的应用实例:
**
分类
聚类
强化学习
回归
选项:
只有2
1和2
1和3
2和3
1 2 3
1 2 3 4
答案: E
一般来说,电影推荐系统会基于用户过往的活动和资料,将用户聚集在有限数量的相似组中。然后,从根本上来说,对同一集群的用户进行相似的推荐。
在某些情况下,电影推荐系统也可以归为分类问题,将最适当的某类电影分配给特定用户组的用户。与此同时,电影推荐系统也可以视为增强学习问题,即通过先前的推荐来改进以后的电影推荐。
Q2. 情感分析是以下哪些的实例:
回归
分类
聚类
强化学习
选项:
只有1
1和2
1和3
1 2 3
1 2 4
1 2 3 4
答案:E
在基本水平上的情感分析可以被认为是将图像、文本或语音中表示的情感,分类成一些情感的集合,如快乐、悲伤、兴奋、积极、消极等。同时,它也可以被视为对相应的图像、文本或语音按照从1到10的情感分数进行回归。
另一种方式则是从强化学习的角度来思考,算法不断地从过去的情感分析的准确性上进行学习,以此提高未来的表现。
Q3. 决策树可以用来执行聚类吗?
**
能
不能
答案:A
决策树还可以用在数据中的聚类分析,但是聚类常常生成自然集群,并且不依赖于任何目标函数。
Q4. 在进行聚类分析之前,给出少于所需数据的数据点,下面哪种方法最适合用于数据清理?
**
限制和增加变量
去除异常值
选项:
1
2
1和2
都不能
答案:A
在数据点相对较少的时候,不推荐去除异常值,在一些情况下,对变量进行剔除或增加更合适。
Q5. 执行聚类时,最少要有多少个变量或属性?
**
0
1
2
3
答案:B
进行聚类分析至少要有一个变量。只有一个变量的聚类分析可以在直方图的帮助下实现可视化。
Q6. 运行过两次的K均值聚类,是否可以得到相同的聚类结果?
**
是
否
答案:B
K均值聚类算法通常会对局部最小值进行转换,个别时候这个局部最小值也是全局最小值,但这种情况比较少。因此,更建议在绘制集群的推断之前,多次运行K均值算法。
然而,每次运行K均值时设置相同的种子值是有可能得出相同的聚类结果的,但是这样做只是通过对每次的运行设置相同的随机值来进行简单的算法选择。
Q7. 在K均值的连续迭代中,对簇的观测值的分配没有发生改变。这种可能性是否存在?
**
是
否
不好说
以上都不对
答案:A
当K均值算法达到全局或局部最小值时,两次连续迭代所产生的数据点到簇的分配不会发生变化。
Q8. 以下哪项可能成为K均值的终止条件?
**
对固定数量的迭代。
在局部最小值不是特别差的情况下,在迭代中对簇观测值的分配不发生变化。
在连续迭代中质心不发生变化。
当 RRS 下降到阈值以下时终止。
选项:
1 3 4
1 2 3
1 2 4
全部都是
答案:D
这四种条件都可能成为K均值聚类的终止条件:
这个条件限制了聚类算法的运行时间,但是在一些情况下,由于迭代次数不足,聚类的质量会很差。
在局部最小值不是特别差的情况下,会产生良好的聚类,但是运行时间可能相当长。
这种条件要确保算法已经收敛在最小值以内。
在 RRS 下降到阈值以下时终止,可以确保之后聚类的质量。实际上,这是一个很好的做法,在结合迭代次数的同时保证了K均值的终止。
Q9. 以下哪种算法会受到局部最优的聚焦问题的影响?
**
K均值聚类算法
层次聚类算法
期望-最大化聚类算法
多样聚类算法
选项:
1
2 3
2 4
1 3
1 2 4
以上都是
答案:D
在上面四个选项中,只有K均值聚类和期望-最大化聚类算法有在局部最小值出收敛的缺点。
Q10. 以下哪种算法对离群值最敏感?
**
K均值聚类算法
K中位数聚类算法
K模型聚类算法
K中心点聚类算法
答案:A
在上面给出的选项中,K均值聚类算法对离群值最敏感,因为它使用集群数据点的平均值来查找集群的中心。
Q11. 在对数据集执行K均值聚类分析以后,你得到了下面的树形图。从树形图中可以得出那些结论呢?
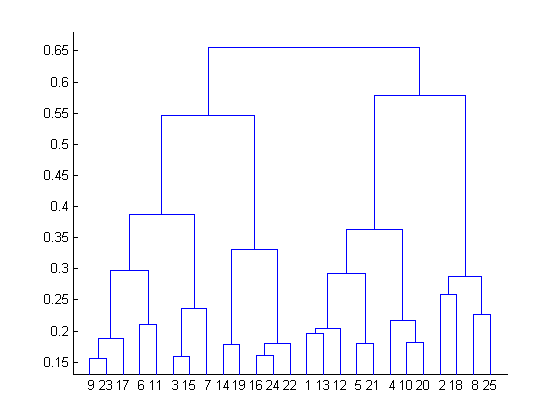
在聚类分析中有28个数据点
被分析的数据点里最佳聚类数是4
使用的接近函数是平均链路聚类
对于上面树形图的解释不能用于K均值聚类分析
答案:D
树形图不可能用于聚类分析。但是可以根据K聚类分析的结果来创建一个簇状图。
Q12. 如何使用聚类(无监督学习)来提高线性回归模型(监督学习)的准确性:
**
为不同的集群组创建不同的模型。
将集群的id设置为输入要素,并将其作为序数变量。
将集群的质心设置为输入要素,并将其作为连续变量。
将集群的大小设置为输入要素,并将其作为连续变量。
选项:
1
1 2
1 4
3
2 4
以上都是
答案:F
将集群的 id 设置为序数变量和将集群的质心设置为连续变量,这两项可能不会为多维数据的回归模型提供更多的相关信息。但是当在一个维度上进行聚类分析时,上面给出的所有方法都有望为多维数据的回归模型提供有意义的信息。举个例子,根据头发的长度将人们分成两组,将聚类 ID 存储为叙述变量,将聚类质心存储为连续变量,这样一来,多维数据的回归模型将会得到有用的信息。
Q13. 使用层次聚类算法对同一个数据集进行分析,生成两个不同的树形图有哪些可能的原因:
**
使用了接近函数
数据点的使用
变量的使用
只有B和C
以上都有
答案:E
接近函数、数据点、变量,无论其中哪一项的改变都可能使聚类分析产生不同的结果,并产生不同的树状图。
Q14. 在下面的图中,如果在y轴上绘制一条y=2的水平线,将产生多少簇?
**
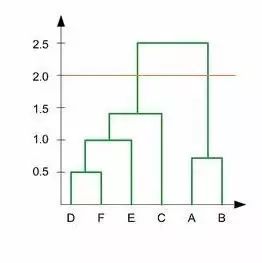
1
2
3
4
答案:B
因为在树状图中,与 y=2 红色水平线相交的垂直线有两条,因此将形成两个簇。
Q15. 根据下面的树形图,数据点所产生的簇数最可能是?
**
2
4
6
8
答案:B
通过观察树状图,可以很好的判断出不同组的簇数。根据下图,水平线贯穿过的树状图中垂直线的数量将是簇数的最佳选择,这条线保证了垂直横穿最大距离并且不与簇相交。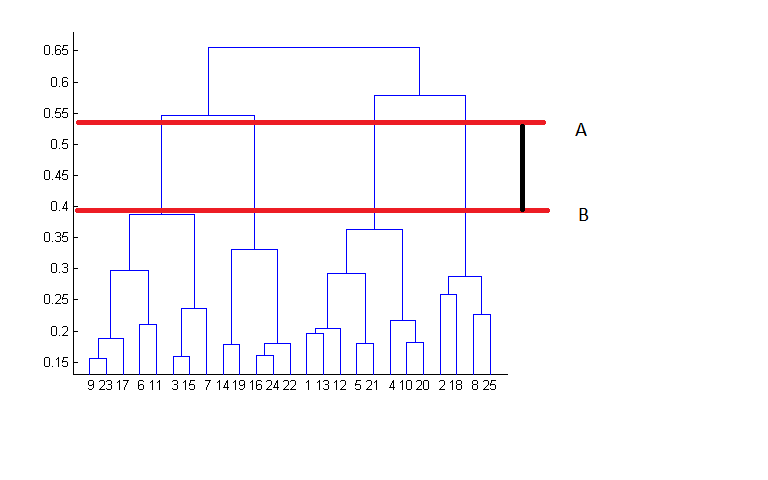
在上面的例子中,簇的数量最佳选择是4,因为红色水平线涵盖了最大的垂直距离AB。
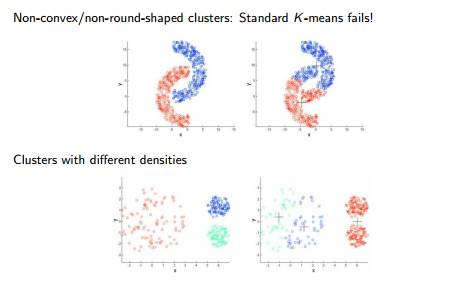
Q16. K均值聚类分析在下面哪种情况下无法得出好的结果?
**
具有异常值的数据点
具有不同密度的数据点
具有非环形的数据点
具有非凹形的数据点
选项:
1 2
2 3
2 4
1 2 4
1 2 3 4
答案:D
在数据包含异常值、数据点在数据空间上的密度扩展具有差异、数据点为非凹形状的情况下,K均值聚类算法的运行结果不佳。
Q17. 通过以下哪些指标我们可以在层次聚类中寻找两个集群之间的差异?
单链
完全链接
平均链接
选项:
1 2
1 3
2 3
1 2 3
答案:D
通过单链接、完全链接、平均链接这三种方法,我们可以在层次聚类中找到两个集群的差异。
Q18. 下面哪些是正确的?
特征性多重共线性对聚类分析有负面效应
异方差性对聚类分析有负面效应
选项:
1
2
1 2
以上都不是
答案:A
聚类分析不会受到异方差性的负面影响,但是聚类中使用的特征/变量多重共线性会对结果有负面的影响,因为相关的特征/变量会在距离计算中占据很高的权重。
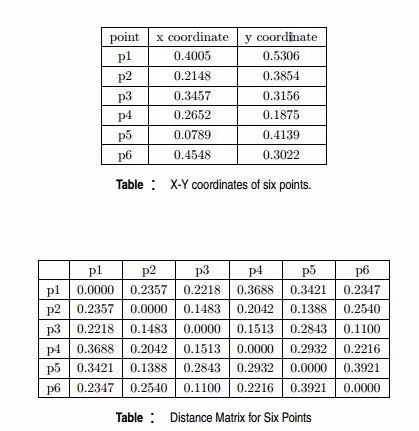
Q19. 给定具有以下属性的六个点:
**
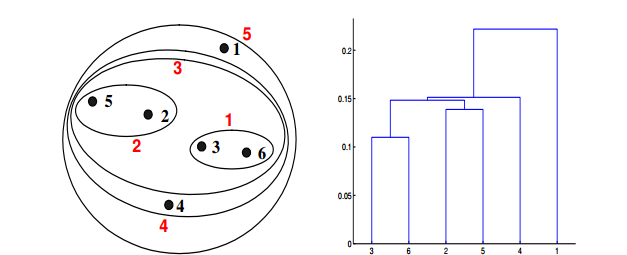
如果在层次聚类中使用最小值或单链接近函数,可以通过下面哪些聚类表示和树形图来描述?
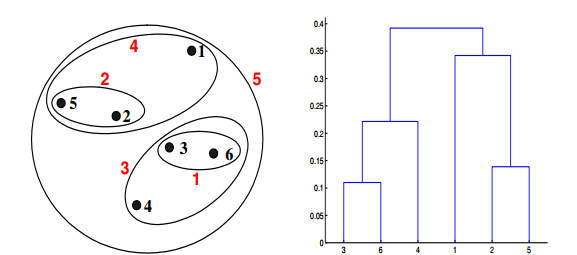
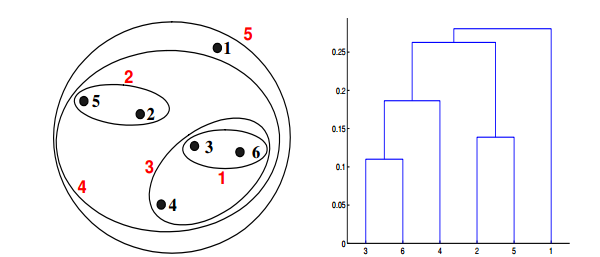
答案:A
对于层级聚类的单链路或者最小化,两个簇的接近度指的是不同簇中任何两个点之间的距离的最小值。例如,我们可以从图中看出点3和点6之间的距离是0.11,这正是他们在树状图中连接而成的簇的高度。再举一个例子,簇{3,6}和{2,5}之间的距离这样计算:dist({3, 6}, {2, 5}) =min(dist(3, 2), dist(6, 2), dist(3, 5), dist(6, 5)) = min(0.1483, 0.2540,0.2843, 0.3921) = 0.1483.
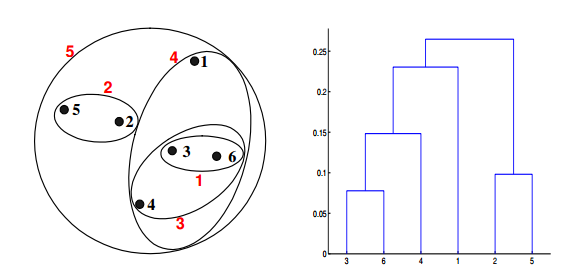
Q20. 给定具有以下属性的六个点:**
如果在层次聚类中使用最大值或完全链接接近函数,可以通过下面哪些聚类表示和树形图来描述?
答案:B
对于层级聚类的单链路或者最大值,两个簇的接近度指的是不同簇中任何两个点之间的距离的最大值。同样,点3和点6合并在了一起,但是{3,6}没有和{2,5}合并,而是和{4}合并在了一起。这是因为dist({3, 6}, {4}) = max(dist(3, 4), dist(6, 4)) = max(0.1513,0.2216) = 0.2216,它小于dist({3, 6}, {2, 5}) = max(dist(3,2), dist(6, 2), dist(3, 5), dist(6, 5)) = max(0.1483, 0.2540, 0.2843, 0.3921) =0.3921 and dist({3, 6}, {1}) = max(dist(3, 1), dist(6, 1)) = max(0.2218,0.2347) = 0.2347。
本文作者 Saurav Kaushik 是数据科学爱好者,还有一年他就从新德里 MAIT 毕业了,喜欢使用机器学习和分析来解决复杂的数据问题。
本文由 AI100 编译,转载需得到本公众号同意。
编译:AI100
原文链接:https://www.analyticsvidhya.com/blog/2017/02/test-data-scientist-clustering/
查看更多 AI 最新头条,请访问 AI100 微信公众号:

点击↙阅读原文↙查看更多资讯
阅读原文

若有收获,就点个赞吧
0 人点赞
