# Spss K-means聚类分析案例——某移动公司客户细分模型
3877人阅读 收藏
聚类分析在各行各业应用十分常见,而顾客细分是其最常见的分析需求,顾客细分总是和聚类分析挂在一起。
顾客细分,关键问题是找出顾客的特征,一般可从顾客自然特征和消费行为入手,在大型统计分析工具出现之前,主要是通过两种方式进行“分群别类”,第一种,用单一变量进行划段分组,比如,以消费频率变量细分,即将该变量划分为几个段,高频客户、中频客户、低频客户,这样的状况;第二种,用多个变量交叉分组,比如用性别和收入两个变量,进行交叉细分。
事实是,我们总是希望考虑多方面特征进行聚类,这样基于多方面综合特征的客户细分比单个特征的细分更有意义,这正是spss聚类分析可以做到的,以下通过k-means聚类分析做一个小小案例来展示。
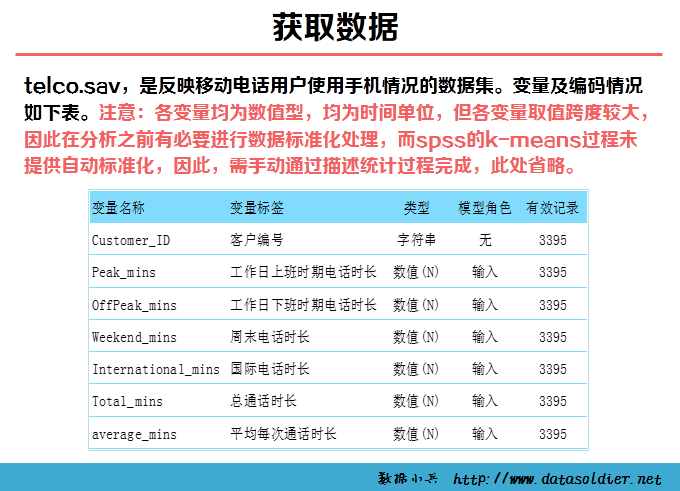
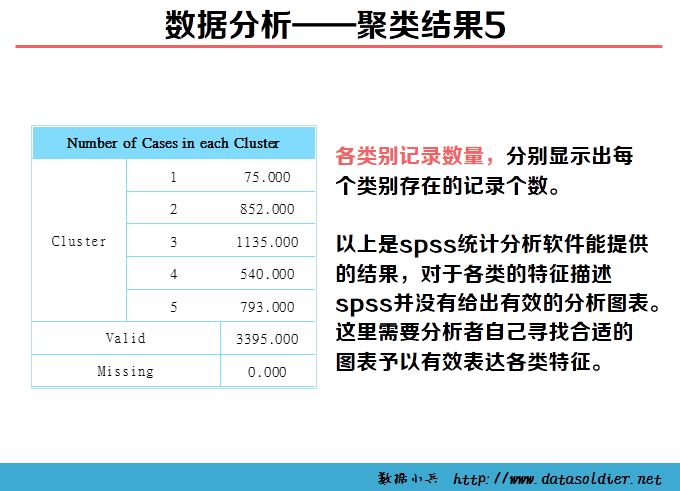
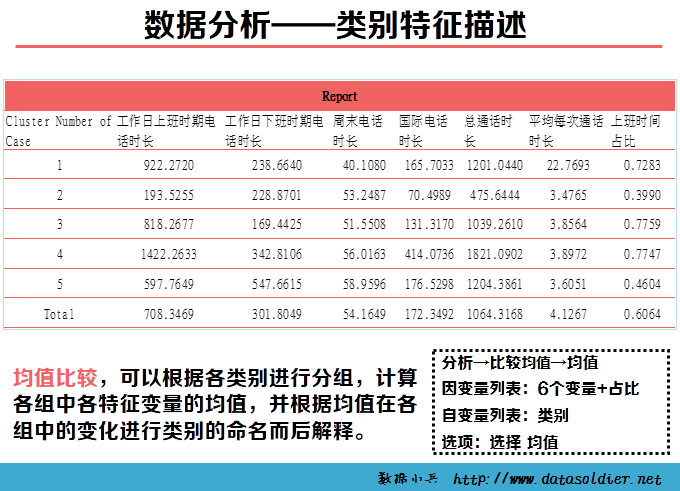
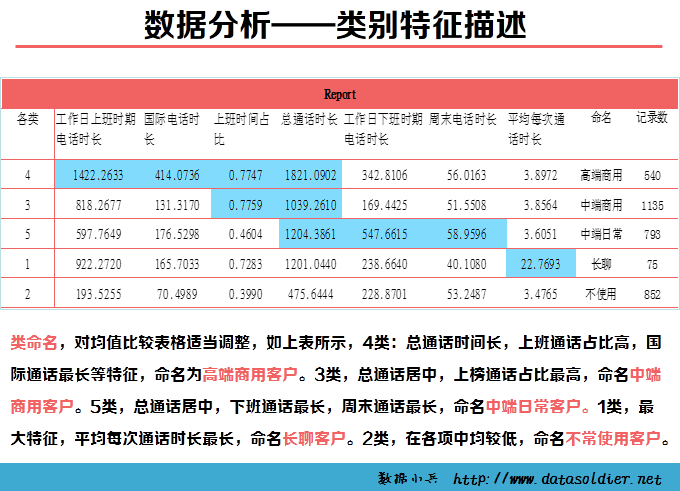
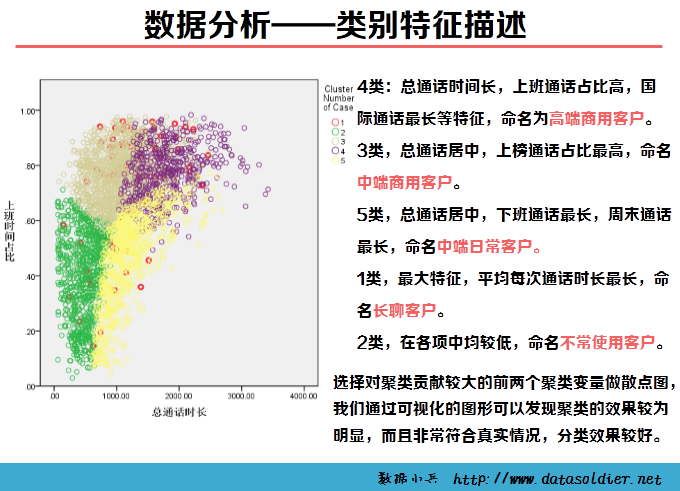
《SPSS统计分析高级教程》telco.sav,是反映移动电话用户使用手机情况的数据集。包含7个变量:用户编号、工作日上班时间电话时长、工作日下班时间电话时长、周末电话时长、国际电话时长、总通话时长、平均每次通话时长,现希望对移动用户细分,了解他们不同的手机消费习惯。根据研究调研及经验,认为移动用户应分为5个主要消费群体。数据分析工具:spss,参考教程:张文彤,《 SPSS12 统计分析高级教程》。

 现在存储于后台的数据太多了,以前做项目担心没有真实可靠的数据,现在这个问题没有那么复杂,但数据太多却引发了其他问题。辛苦采集到的数据口径不一致,存储格式不同,不符合数据分析要求还有待派生新的变量。
现在存储于后台的数据太多了,以前做项目担心没有真实可靠的数据,现在这个问题没有那么复杂,但数据太多却引发了其他问题。辛苦采集到的数据口径不一致,存储格式不同,不符合数据分析要求还有待派生新的变量。
这些过程看似简单却非常有必要!
仅仅预处理以上这些问题还不够,当数据分析方法复杂时,我们还需对采集的数据进行筛选构成小的数据集,对于数据集中变量的分布、缺失、描述统计指标进行一定程度的分析。
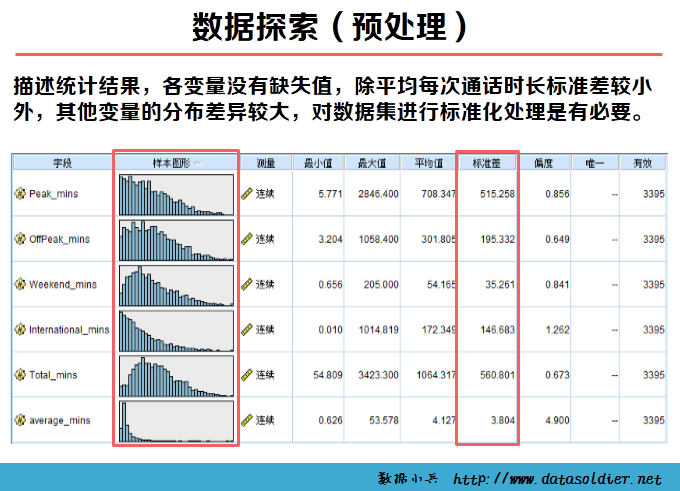
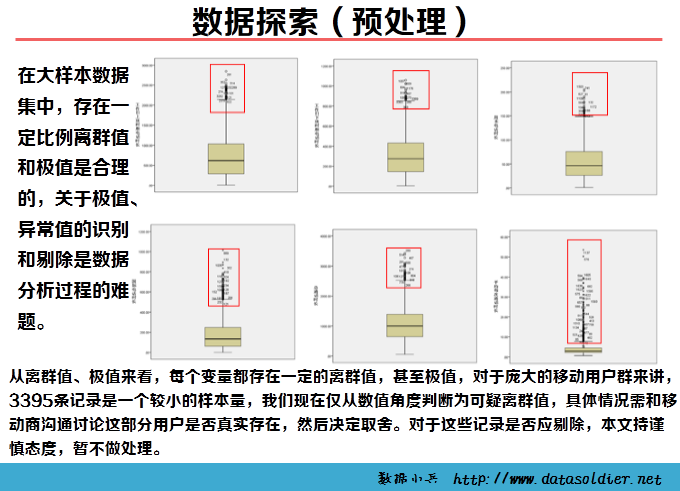

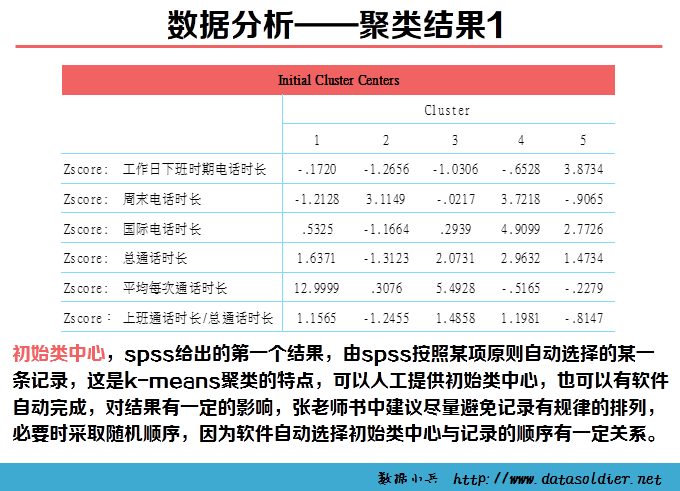
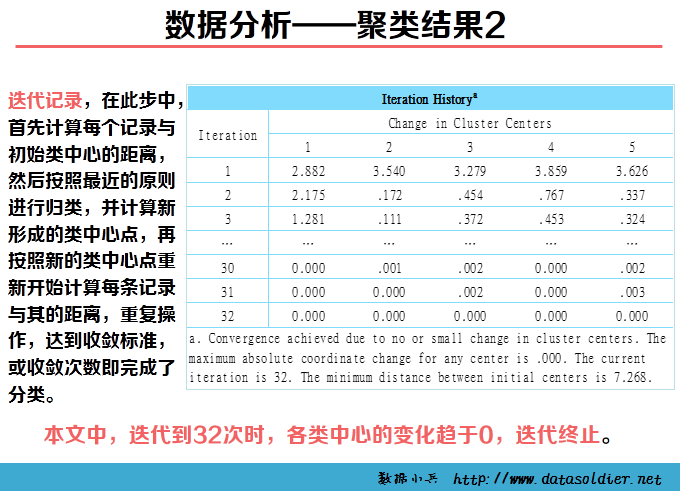
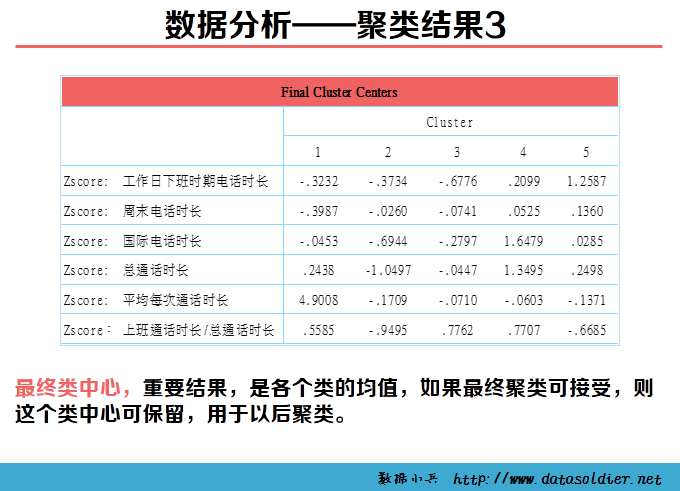
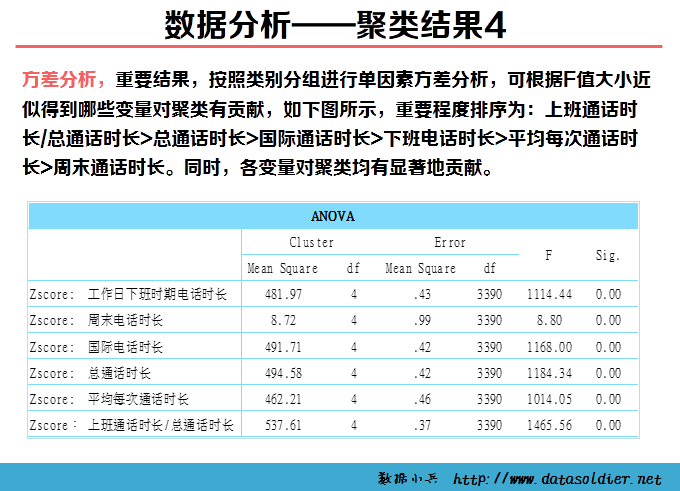
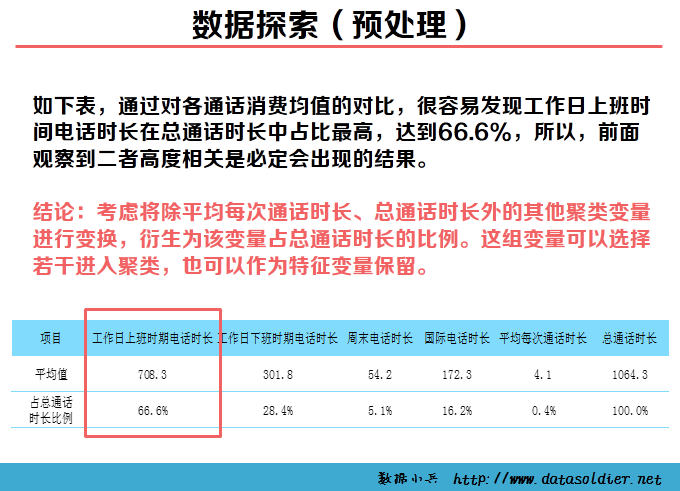 K-means聚类也称快速聚类,可以用于大量数据进行聚类的情形。在开始聚类之前,需要分析者自己制定类数目,并不是一次指定,可以经过多轮反复分析,根据实际情况最终判定最优类的数目。 K-means聚类是采用计算距离的方式测度变量间的亲疏程度,距离直接影响最终的结果,因此慎重审核数据质量。
K-means聚类也称快速聚类,可以用于大量数据进行聚类的情形。在开始聚类之前,需要分析者自己制定类数目,并不是一次指定,可以经过多轮反复分析,根据实际情况最终判定最优类的数目。 K-means聚类是采用计算距离的方式测度变量间的亲疏程度,距离直接影响最终的结果,因此慎重审核数据质量。

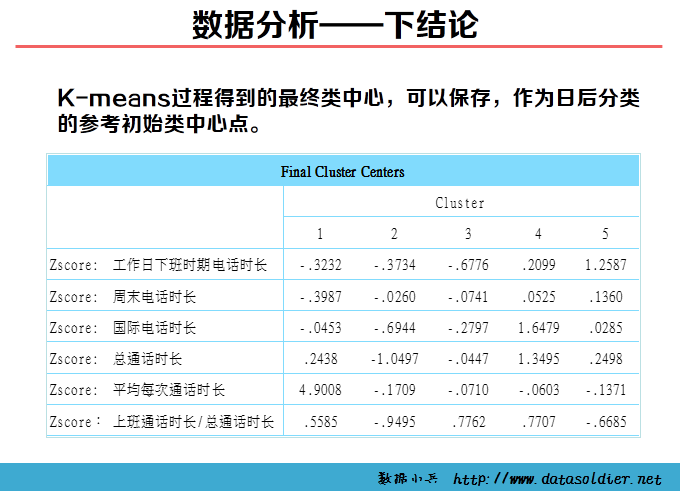
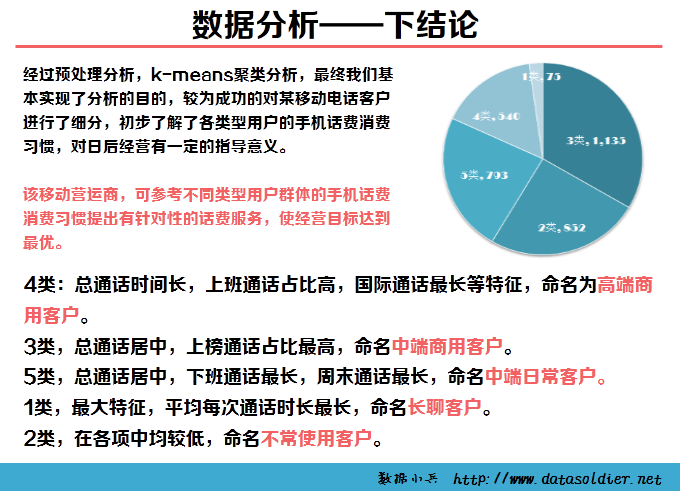
 做一个数据分析的项目,不能不下结论!
做一个数据分析的项目,不能不下结论!
雷声大,雨点小的事情,作为数据分析师千万要避免发生。提交数据分析报告,对分析下结论,对业务问题进行及时解决,养成这个良好的习惯。
本文来自:数据小兵博客
本文地址:http://www.datasoldier.net/post/kmeans.html

若有收获,就点个赞吧
0 人点赞
