命令查看
127.0.0.1:6379> set k1 redisOK127.0.0.1:6379> set k2 123OK127.0.0.1:6379> set k3 cccccccccccccccccccccccccccccccccccccccccccccOK127.0.0.1:6379> OBJECT ENCODING k1"embstr"127.0.0.1:6379> OBJECT ENCODING k2"int"127.0.0.1:6379> object encoding k3"raw"
存储方式
从上面的命令查看,我们可以看到实现string数据类型的数据结构有 embstr,int以及row。
int:当存储的字符串全是数字时,此时使用int方式来存储;embstr:当存储的字符串长度小于等于44个字符时,此时使用embstr方式来存储;raw:当存储的字符串长度大于44个字符时,此时使用raw方式来存储;
对于embstr和raw这两种encoding类型,其存储方式还不太一样。对于embstr类型,它将RedisObject对象头和SDS对象在内存中地址是连在一起的,但对于raw类型,二者在内存地址不是连续的。
简单动态字符串SDS
Redis 是用 C 语言写的,但是对于Redis的字符串,却不是 C 语言中的字符串(即以空字符’\0’结尾的字符数组),它是自己构建了一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。
SDS 定义:
struct sdsshr<T>{T len;//数组长度T alloc;//数组容量unsigned flags;//sdshdr类型char buf[];//数组内容}
可以看出,SDS的结构有点类似于Java中的ArrayList。buf[]表示真正存储的字符串内容,alloc表示所分配的数组的长度,len表示字符串的实际长度,并且由于len这个属性的存在,Redis可以在O(1)的时间复杂度内获取数组长度。
我们看上面对于 SDS 数据类型的定义:
- len :记录buf数组中已使用的字节数量
- alloc: 分配的buf数组长度,不包括头和空字符结尾
flags: 标志位, 最低3位表示header类型,另外5个位没有使用。类型对应下面5中类型,用3个bit位就可以表示。
#define SDS_TYPE_5 0#define SDS_TYPE_8 1#define SDS_TYPE_16 2#define SDS_TYPE_32 3#define SDS_TYPE_64 4
-
图示
举个例子:我们在一个SDS中存放了redis字符串,SDS是怎么表示的呢?

SDS类型
为了追求对于内存的极致优化,对于不同长度的字符串,
Redis底层会采用不同的结构体来表示。在Redis中的sds.h源码中存在着五种sdshdr,分别如下:
/* Note: sdshdr5 is never used, we just access the flags byte directly.* However is here to document the layout of type 5 SDS strings. */struct __attribute__ ((__packed__)) sdshdr5 {unsigned char flags; /* 3 lsb of type, and 5 msb of string length */char buf[];};struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* used */uint8_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len; /* used */uint16_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len; /* used */uint32_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};struct __attribute__ ((__packed__)) sdshdr64 {uint64_t len; /* used */uint64_t alloc; /* excluding the header and null terminator */unsigned char flags; /* 3 lsb of type, 5 unused bits */char buf[];};
上面说了,Redis底层会根据字符串的长度来决定具体使用哪种类型的sdshdr。可以看出,sdshdr5明显区别于其他四种结构,它一般只用于存储长度不会变化,且长度小于32个字符的字符串。但现在一般都不再使用该结构,因为其结构没有**len**和**alloc**这两个属性,不具备动态扩容操作,一旦预分配的内存空间使用完,就需要重新分配内存并完成数据的复制和迁移,类似于ArrayList的扩容操作,这种操作对性能的影响很大。
我们注意到在每个sdshdr的头定义上都有一个attribute((``packed``)),这个是为了告诉gcc取消优化对齐,这样,每个字段分配的内存地址就是紧紧排列在一起的,Redis中字符串参数的传递直接使用char*指针,其实现原理在于,由于sdshdr内存分配禁止了优化对齐,所以sds[-1]指向的就是flags属性的内存地址,而通过flags属性又可以确定sdshdr的属性,进而可以读取头部字段确定sds的相关属性。
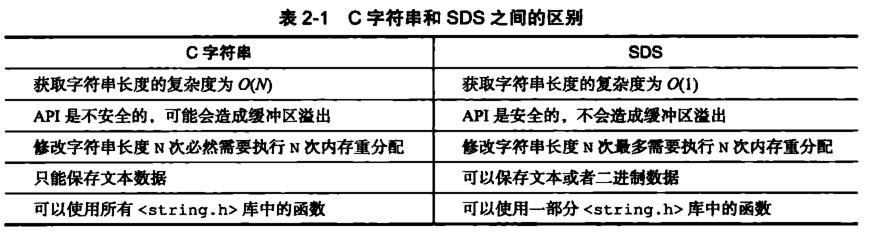
SDS相对C字符串的好处?
- 常数复杂度获取字符串长度
由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。通过 strlen key 命令可以获取 key 的字符串长度。
- 杜绝缓冲区溢出
我们知道在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 free 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
- 减少修改字符串的内存重新分配次数
C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
对于SDS来说,当其使用append进行字符串追加时,程序会用 alloc-len 比较下剩下的空余内存是否足够分配追加的内容,如果不够自然触发内存重分配,而如果剩余未使用内存空间足够放下,那么将直接进行分配,无需内存重分配。其扩容策略为,当字符串占用大小小于1M时,每次分配为**len** * 2,也就是保留100%的冗余;大于1M后,为了避免浪费,只多分配1M的空间。
而对于SDS,由于len属性和free属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放两种策略:
1、空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
2、惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 free 属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)
- 二进制安全
因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
- 兼容部分 C 字符串函数
虽然 SDS 是二进制安全的,但是一样遵从每个字符串都是以空字符串结尾的惯例,这样可以重用 C 语言库
C语言字符串和SDS的区别
总结导图


若有收获,就点个赞吧
0 人点赞
