前言
分布式系统顾名思义就是利用多台计算机协同解决单台计算机所不能解决的计算、存储等问题。单机系统与分布式系统的最大的区别在于问题的规模,即计算、存储的数据量的区别。将一个单机问题使用分布式解决,首先要解决的就是如何将问题拆解为可以使用多机分布式解决,使得分布式系统中的每台机器负责原问题的一个子集。由于无论是计算还是存储,其问题输入对象都是数据,所以如何拆解分布式系统的输入数据成为分布式系统的基本问题,本文称这样的数据拆解为数据分布方式,介绍几种常见的数据分布方式,最后对这几种方式加以对比讨论。 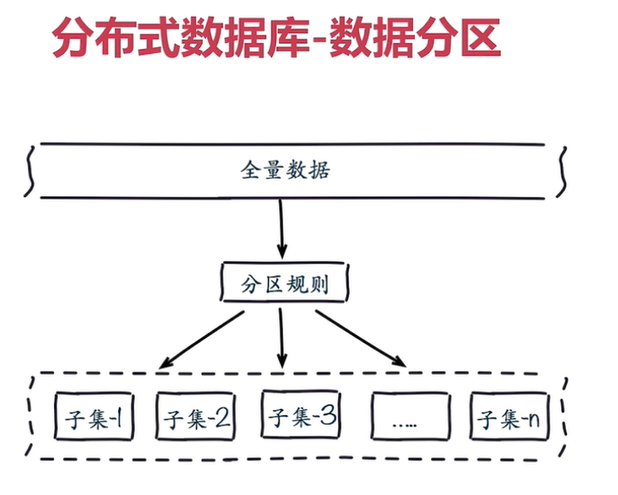
常用数据分布方式之哈希分布
哈希方式是最常见的数据分布方式,其方法是按照数据的某一特征计算哈希值,并将哈希值与机器中的机器建立映射关系,从而将不同哈希值的数据分布到不同的机器上。所谓数据特征可以是 key-value 系统中的 key,也可以是其他与应用业务逻辑相关的值。
例如,一种常见的哈希方式是按 数据属于的用户id计算哈希值,集群中的服务器按0到机器数减1编号,哈希值除以服务器的个数, 结果的余数作为处理该数据的服务器编号。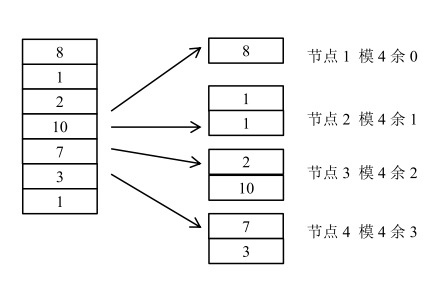
缺点
- 可扩展性不高,一旦集群规模需要扩展,则几乎所有的数据需要被迁移并重新分布。
工程中,扩展哈希分布数据的系统时,往往使得集群规模成倍扩展,按照数据重新计算哈希,这样原本一台机器上的数据只需迁移一半到另一台对应的机器上即可 完成扩展。
针对哈希方式扩展性差的问题,一种思路是不再简单的将哈希值与机器做除法取模映射,而是将对应关系作为元数据由专门的元数据服务器管理。
- 一旦某数据特征值的数据严重不均,容易出现“数据倾斜”(dataskew)问题。
在这种情况下只能重新选择需要哈希的数据特征,例如选择用户 id 与另一个数据维度的组合作
为哈希函数的输入,如这样做,则需要完全重新分布数据,在工程实践中可操作性不高。
常用数据分布方式之按数据范围分布
按数据范围分布是另一个常见的数据分布式,将数据按特征值的值域范围划分为不同的区间,使得集群中每台(组)服务器处理不同区间的数据。
例如:已知某系统中用户 id 的值域范围是[1,100),集群有 3 台服务器,使用按数据范围划分数据的数据分布方式。将用户 id 的值域分为三个区间[1, 33),,[33, 90),[90, 100)分别由 3 台服务器 负责处理。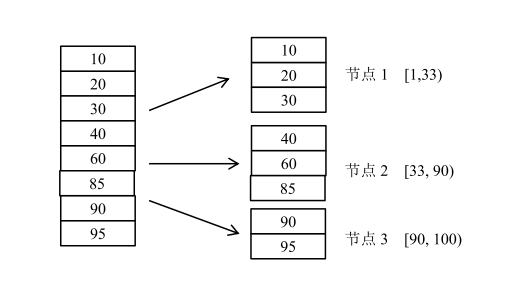
- 工程中,为了数据迁移等负载均衡操作的方便,往往利用动态划分区间的技术,使得每个区间中服务的数据量尽量的一样多。当某个区间的数据量较大时,通过将区间“分裂”的方式拆分为两个区间,使得每个数据区间中的数据量都尽量维持在一个较为固定的阈值之下。
- 使用范围分布数据的方式的最大优点就是可以灵活的根据数据量的具体情况拆分原有数据区间,拆分后的数据区间可以迁移到其他机器,一旦需要集群完成负载均衡时,与哈希方式相比非常灵活。另外,当集群需要扩容时,可以随意添加机器,而不限为倍增的方式,只需将原机器上的部分数据分区迁移到新加入的机器上就可以完成集群扩容。
按范围分布数据方式的缺点是需要维护较为复杂的元信息。随着集群规模的增长,元数据服务器较为容易成为瓶颈,从而需要较为负责的多元数据服务器机制解决这个问题。(一般的,往往需要使用专门的服务器在内存中维护数据分布信息,称这种数据的分布信息为一种元信息。)
常用数据分布方式之按数据量分布
另一类常用的数据分布方式则是按照数据量分布数据。与哈希方式和按数据范围方式不同,数据量分布数据与具体的数据特征无关,而是将数据视为一个顺序增长的文件,并将这个文件按照某一较为固定的大小划分为若干数据块(chunk),不同的数据块分布到不同的服务器上。
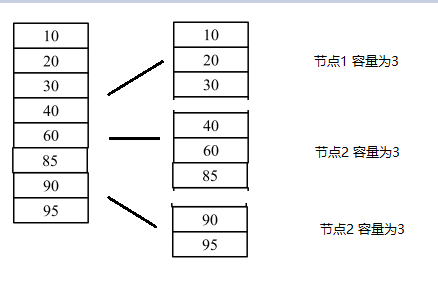
由于与具体的数据内容无关,按数据量分布数据的方式一般没有数据倾斜的问题,数据总是被均匀切分并分布到集群中。当集群需要重新负载均衡时,只需通过迁移数据块即可完成。集群扩容也没有太大的限制,只需将部分数据库迁移到新加入的机器上即可以完成扩容。
- 按数据量划分数据的缺点是需要管理较为复杂的元信息,与按范围分布数据的方式类似,当集群规模较大时,元信息的数据量也变得很大,高效的管理元信息成为新的课题。
常用数据分布方式之一致性哈希
一致性哈希的基本方式是使用一个哈希函数计算数据或数据特征的哈希值,令该哈希函数的输出值域为一个封闭的环,即哈希函数输出的最大值是最小值的前序。将节点随机分布到这个环上,每个节点负责处理从自己开始顺 时针至下一个节点的全部哈希值域上的数据。
详细可以看这一篇:白话解析:一致性哈希算法 consistent hashing
常用数据分布方式之哈希槽分区
哈希槽(虚拟桶)是取模和一致性哈希二者的折中办法。
- 采用固定节点数量,来避免取模的不灵活性。
- 采用可配置映射节点,来避免一致性哈希的部分影响。
基本思想:
- 固定数量个槽,每台服务器分管其中的一部分
- 插入一个数据的时候,先根据CRC16算法计算key对应的值,然后用该值对槽数量取余数,确定将数据放到哪个槽里面
- 在增加的时候,之前的节点各自分出一些槽给新节点,对应的数据也一起迁出。

若有收获,就点个赞吧
0 人点赞
