命令查看
127.0.0.1:6379> sadd set1 zhangsan(integer) 1127.0.0.1:6379> sadd set1 zhangsan(integer) 0127.0.0.1:6379> sadd set1 lisi(integer) 1127.0.0.1:6379> sadd set1 wangwu(integer) 1127.0.0.1:6379> object encoding set1"hashtable"127.0.0.1:6379> sadd set2 1(integer) 1127.0.0.1:6379> sadd set2 2(integer) 1127.0.0.1:6379> sadd set2 3(integer) 1127.0.0.1:6379> object encoding set2"intset"
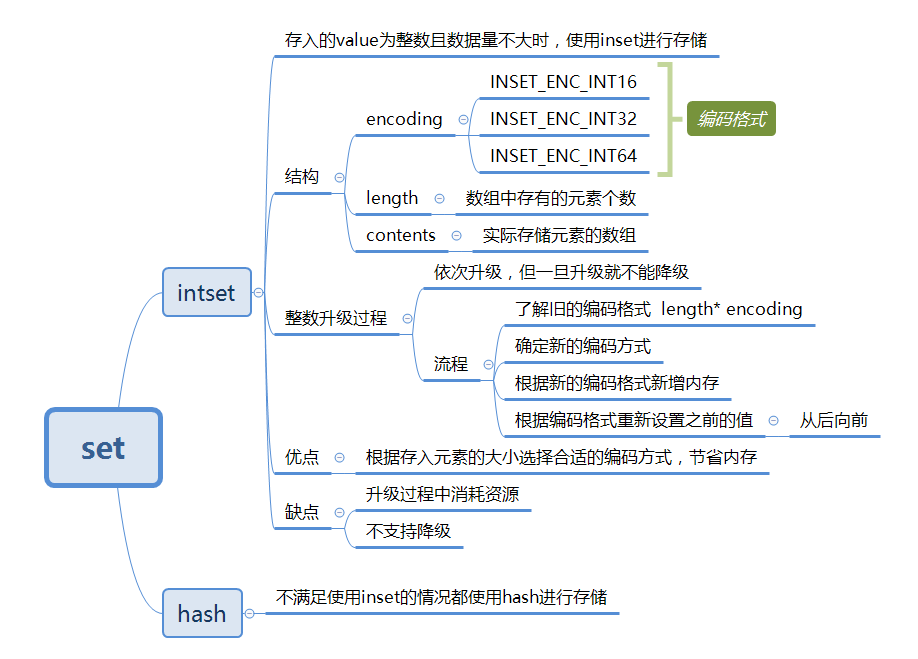
我们可以看到set的底层数据结构有两种, intset 和 hashtable 。
当value是整数值的时候,且数据量不大的时候用 instset 存储,其他的情况都用 hashtable 存储。hashtable 和上一篇Hash数据结构分析一致,这篇主要看 intset 。
intset 整数集合
Redis中inset的结构定义如下所示:
typedf struct inset{uint32_t encoding;//编码方式 有三种 默认 INSET_ENC_INT16uint32_t length;//集合元素个数int8_t contents[];//实际存储元素的数组,元素类型并不一定是ini8_t类型,柔性数组不占intset结构体大小,并且数组中的元素从小到大排列。}inset;#define INTSET_ENC_INT16 (sizeof(int16_t)) //16位,2个字节,表示范围-32,768~32,767#define INTSET_ENC_INT32 (sizeof(int32_t)) //32位,4个字节,表示范围-2,147,483,648~2,147,483,647#define INTSET_ENC_INT64 (sizeof(int64_t)) //64位,8个字节,表示范围-9,223,372,036,854,775,808~9,223,372,036,854,775,807
编码格式encoding:共有三种,INTSET_ENC_INT16、INSET_ENC_INT32和INSET_ENC_INT64三种,分别对应不同的范围。Redis为了尽可能地节省内存,会根据插入数据的大小选择不一样的类型来进行存储。
元素数量length:记录了保存数据的数组contents中共有多少个元素,这样获取个数的时间复杂度就是O(1)。
数组contents:真正存储数据的地方,数组是按照从小到大有序排列的,并且不包含任何重复项(因为set是不含重复项,所以其底层实现也是不含包含项的)。
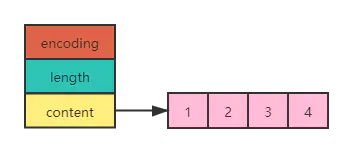
整数集合升级过程
上面的图我们重新看下,编码格式encoding为INTSET_ENC_INT16,即每个数据占16位。长度length为4,即数组content里面有四个元素,分别是1,2,3,4。如果我们要添加一个数字位40000,很明显超过编码格式为INTSET_ENC_INT16的范围-32,768~32,767,应该是编码格式为INTSET_ENC_INT32。那么他是如何升级的呢,从INTSET_ENC_INT16升级到INTSET_ENC_INT32的呢?
1.了解旧的存储格式
首先我们看下1,2,3,4这四个元素是如何存储的。首先要知道一共有多少位,计算规则为length*编码格式的位数,即4*16=64。所以每个元素占用了16位。
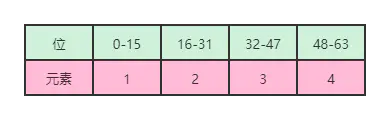
2.确定新的编码格式
新的元素为40000,已经超过了INTSET_ENC_INT16的范围-32,768~32,767,所以新的编码格式为INTSET_ENC_INT32。
3.根据新的编码格式新增内存
上面已经说明了编码格式为INTSET_ENC_INT32,计算规则为length*编码格式的位数,即5*32=160。所以新增的位数为64-159。
4.根据编码格式设置对应的值
从上面知道按照新的编码格式,每个数据应该占用32位,但是旧的编码格式,每个数据占用16位。所以我们从后面开始,每次获取32位用来存储数据。
这样说太难懂了,看下图☺。
首先,那最后32位,即128-159存储40000。那么第49-127是空着的。
接着,取空着的49-127最后的32位,即96到127这32位,用来存储4。那么之前4存储的位置48-63和49-127剩下的64-95这两部分组成了一个大部分,即48-95,现在空着啦。
在接着在48-95这个大部分,再取后32位,即64-95,用来存储3。那么之前3存储位置32-47和48-95剩下的48-63这两部分组成了一个大部分,即32-63,现在空着啦。
再接着,将32-63这个大部分,再取后32位,即还是32-63,用来存储2。那么之前2存储位置16-31空着啦。
最后,将16-31和原来0-31合起来,存储1。
至此,整个升级过程结束。整体来说,分为3步,确定新的编码格式,新增需要的内存空间,从后往前调整数据。
为啥要从后往前调整数据呢?
原因是如果从前往后,数据可能会覆盖。也拿上面个例子来说,数据1在0-15位,数据2在16-31位,如果从前往后,我们知道新的编码格式INTSET_ENC_INT32要求每个元素占用32位,那么数据1应该占用0-31,这个时候数据2就被覆盖了,以后就不知道数据2啦。
但是从后往前,因为后面新增了一些内存,所以不会发生覆盖现象。
升级的优点
- 节约内存
整数集合既可以让集合保存三种不同类型的值,又可以确保升级操作只在有需要的时候进行,这样就节省了内存。
- 不支持降级
一旦对数组进行升级,编码就会一直保存升级后的状态。即使后面把40000删掉了,编码格式还是不会将会INTSET_ENC_INT16。
总结

若有收获,就点个赞吧
0 人点赞
