上一篇说的Redis主从模式,切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式,自动切换,无需自己动手。
概述
Redis Sentinel是一个分布式架构,其中包含若干个Sentinel节点和Redis数据节点,每个Sentinel节点会对数据节点和其余Sentinel节点进行监控,当它发现节点不可达时,会对节点做下线标识。如果被标识的是主节点,它还会和其他Sentinel节点进行“协商”,当大多数Sentinel节点都认为主节点不可达时,它们会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给Redis应用方。
整个过程完全是自动的,不需要人工来介入,所以这套方案很有效地解决了Redis的高可用问题。
哨兵模式是一种特殊的模式,哨兵模式是基于主从模式,Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。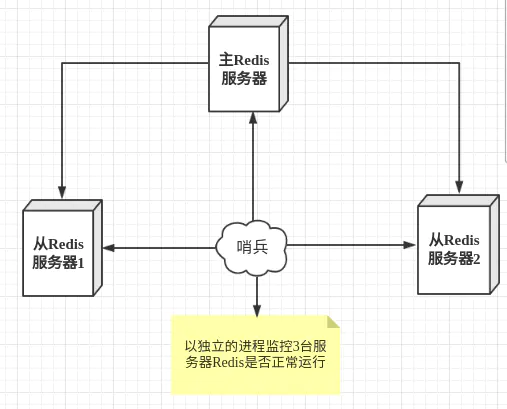
哨兵的三个作用:
- 监控:监控谁?支持主从结构的工作一个是主节点一个是从节点,那肯定就是监控这俩个了。监控主节点和从节点是否正常运行;检测主节点是否存活,主节点和从节点运行情况。
- 通知:哨兵检测的服务器出现问题时,会向其他的哨兵发送通知,哨兵之间就相当于一个微信群,每个哨兵发现的问题都会发在这个群里。
- 自动转移故障:当检测到主节点宕机后,断开与宕机主节点连接的所有从节点,在从节点中选取一个作为主节点,然后将其他的从节点连接到这个最新主节点的上。并且告知客户端最新的服务器地址。
这里有一个注意点,哨兵也是一台 Redis 服务器,只是不对外提供任何服务。配置哨兵时配置为单数。
图解
哨兵系统监控了一主三从。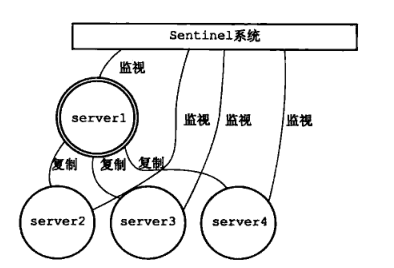
此时主服务器掉线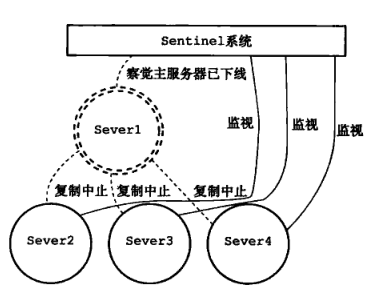
从服务server2被升级为新的主服务,server3和server3设置server2为主服务,进行复制数据和提供服务。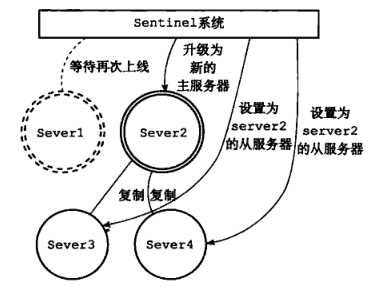
优点
缺点
哨兵sentinel初始化的过程
- 初始化服务器(sentinel也是一个正常的redis服务器)
- 将普通的redis使用的代码替换为哨兵sentinel专用代码
- 不用RDB/AOF文件(因为不需要加载数据,他为监控节点,而不是数据节点)
- 端口号不一样(sentinel的端口号为26379,而默认的redis端口为6379)
- 普通redis命令:set/get/dbsize
- 哨兵命令:ping/sentinel
- 初始化哨兵状态 sentinel
- 向redis服务器创建连接
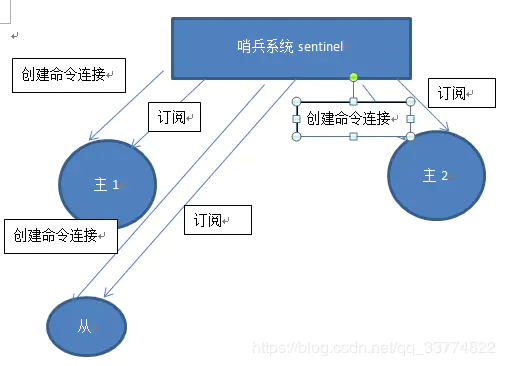
监控流程:
- 每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
- 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令
- 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
- 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
Sentinel为什么是3个?
首先必须哨兵节点必须客观的认为redis节点下线才可以进行主从切换,也就是说,需要多数的哨兵都主观的认为redis主节点下线,为什么呢?如果redis节点正常服务而哨兵服务网络波动而主观认定redis主节点下线,这样是无法进行主从切换的,这样可以有效地防止误判。
哨兵集群必须部署两个以上节点,如果哨兵集群仅仅部署了两个哨兵实例,那么他的大多数为2(2的大多数为2,3的大多数为2,5的大多数为3,4的大多数为2),如果其中一个哨兵宕机,就无法满足大多数大于等于2,那么在master发生故障的时候就无法进行主从切换。故障转移流程
sentinel领导节点的选举
Leader只是故障转移中出现的角色
采用Raft算法。
- redis主节点的选举
由领导节点将所有的从服务器保存在列表中,然后一项项过滤
A.去除所有处于下线的
B.去除近5s内没有回复的
C.优先级+复制偏移量最大(要求数据为最新的)
D.排序,选择运行ID最小的。
环境搭建
在上一篇Redis主从模式的基础上,我们再搭建三个哨兵节点。
复制配置文件
哨兵使用的配置文件是 sentinel.conf 。
[root@redis-master redis-6.2.4]# cp sentinel.conf sentinel-1.conf[root@redis-master redis-6.2.4]# cp sentinel.conf sentinel-2.conf[root@redis-master redis-6.2.4]# cp sentinel.conf sentinel-3.conf
修改哨兵节点配置文件
三个哨兵的端口分别为26379,26380,26381。
[root@redis-master redis-6.2.4]# vim sentinel-1.confport 26379sentinel monitor mymaster 127.0.0.1 6381 2sentinel auth-pass mymaster anin# 在测试阶段可以设置为no,方便看日志daemonize yessentinel down-after-milliseconds mymaster 5000sentinel parallel-syncs mymaster 1sentinel failover-timeout mymaster 15000
- port:当前sentinel服务运行的端口。
- sentinel monitor mymaster 127.0.0.1 6379 2:sentinel监视一个叫mymaster的主redis实例,这个主实例的IP地址为127.0.0.1,端口号为6379,后边的 2 代表的是,如果有俩个哨兵判断这个主节点挂了那这个主节点就挂了,通常设置为哨兵个数一半加一。
- sentinel auth-pass mymaster:redis的主节点配置的认证密码
- daemonize**:**后台启动,在测试阶段可以设置为no,方便看日志
- sentinel down-after-milliseconds mymaster 5000:自动失效时间,单位是毫秒。
- sentinel parallel-syncs mymaster 1:为指定执行故障转移的时候,最多可以有什么个从redis实例在同步新的主实例。
- sentinel failover-timeout mymaster 15000:为如果在该时间内未完成节点切换,则认为失败。
[root@redis-master redis-6.2.4]# vim sentinel-2.confport 26380sentinel monitor mymaster 127.0.0.1 6381 2sentinel auth-pass mymaster aninsentinel down-after-milliseconds mymaster 5000sentinel parallel-syncs mymaster 1sentinel failover-timeout mymaster 15000
[root@redis-master redis-6.2.4]# vim sentinel-3.confport 26381sentinel monitor mymaster 127.0.0.1 6381 2sentinel auth-pass mymaster aninsentinel down-after-milliseconds mymaster 5000sentinel parallel-syncs mymaster 1sentinel failover-timeout mymaster 15000
启动哨兵节点
[root@redis-master src]# redis-sentinel ../sentinel-1.conf[root@redis-master src]# redis-sentinel ../sentinel-2.conf[root@redis-master src]# redis-sentinel ../sentinel-3.conf
这里我们看到,已经成功监控了一个主节点和两个从节点,并且关联到了已经启动的哨兵。4102:X 16 Jul 2021 10:34:17.156 # Sentinel ID is cf64bbac38374fe37a2e744601bea775ed471b864102:X 16 Jul 2021 10:34:17.156 # +monitor master mymaster 127.0.0.1 6379 quorum 24102:X 16 Jul 2021 10:34:17.159 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 63794102:X 16 Jul 2021 10:34:17.161 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 63794102:X 16 Jul 2021 10:34:17.305 * +sentinel sentinel 20bf25e41d173358ad91a183bec4f758be697e5d 127.0.0.1 26381 @ mymaster 127.0.0.1 63794102:X 16 Jul 2021 10:34:28.851 * +sentinel sentinel 6b4d87e41a749e4e1d493d86ad2372f8c52cb0ae 127.0.0.1 26379 @ mymaster 127.0.0.1 6379
模拟主节点宕机
[root@redis-master src]# ps -ef|grep redisroot 3431 3333 0 7月15 pts/1 00:00:00 redis-cli -p 6380 -a aninroot 3554 3536 0 7月15 pts/2 00:00:00 redis-cli -p 6381 -a aninroot 4044 1 0 10:21 ? 00:00:00 redis-server 0.0.0.0:6380root 4051 1 0 10:21 ? 00:00:00 redis-server 0.0.0.0:6381root 4084 1 0 10:32 ? 00:00:00 redis-server 0.0.0.0:6379root 4097 4005 0 10:34 pts/5 00:00:00 redis-sentinel *:26381 [sentinel]root 4102 3979 0 10:34 pts/4 00:00:00 redis-sentinel *:26380 [sentinel]root 4107 3940 0 10:34 pts/3 00:00:00 redis-sentinel *:26379 [sentinel]root 4113 1839 0 10:35 pts/0 00:00:00 grep --color=auto redis[root@redis-master src]# kill -9 4084
查看哨兵日志
可以看到,哨兵检测到了6379的redis主节点down掉之后,选举6381的从节点升级为主节点,并且将6380从节点的主节点改为新的主节点。4222:X 16 Jul 2021 11:02:57.321 # +sdown master mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.321 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.387 # +odown master mymaster 127.0.0.1 6379 #quorum 3/24222:X 16 Jul 2021 11:02:57.387 # +new-epoch 24222:X 16 Jul 2021 11:02:57.387 # +try-failover master mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.391 # +vote-for-leader cf64bbac38374fe37a2e744601bea775ed471b86 24222:X 16 Jul 2021 11:02:57.397 # 6b4d87e41a749e4e1d493d86ad2372f8c52cb0ae voted for cf64bbac38374fe37a2e744601bea775ed471b86 24222:X 16 Jul 2021 11:02:57.398 # 20bf25e41d173358ad91a183bec4f758be697e5d voted for cf64bbac38374fe37a2e744601bea775ed471b86 24222:X 16 Jul 2021 11:02:57.458 # +elected-leader master mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.458 # +failover-state-select-slave master mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.521 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.521 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.598 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.605 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.605 # +failover-state-reconf-slaves master mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:57.670 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:58.099 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:58.099 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:58.151 # +failover-end master mymaster 127.0.0.1 63794222:X 16 Jul 2021 11:02:58.151 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 63814222:X 16 Jul 2021 11:02:58.152 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 63814222:X 16 Jul 2021 11:02:58.152 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
原本的没有权限写,也得到了相应的权限
127.0.0.1:6381> set testkey testkeyOK
down掉的主节点重新上线之后会被切换为主节点吗?
答案是否定的,就比如你被一个小弟抢了你老大的位置,他肯给回你这个位置吗。因此当master 回来之后,他也只能当个小弟。

若有收获,就点个赞吧
0 人点赞
