高并发,
1.抵御洪水方案:流量分开(分而治之),缓存(拓宽河道),异步(单位时间内处理更多请求)。
一般系统演进,
1.满足现状,选择最熟悉的技术体系。随着流量和业务增加修正架构存在问题,选择社区成熟的,团队熟悉的组件解决问题,
在社区没有合适解决方案的前提下,才会自己造轮子。对架构小修小补无法满足时,考虑重构或者重写,解决现有问题。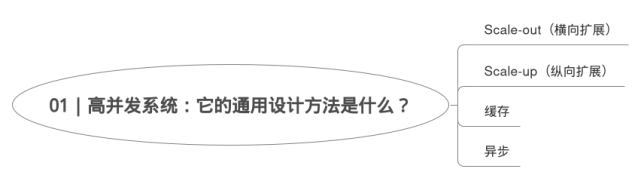
系统分层,
1.终端显示层:各端模板渲染并执行显示的层。当前主要是 Velocity 渲染,JS 渲染, JSP 渲染,移动端展示等。
2.开放接口层:将 Service 层方法封装成开放接口,同时进行网关安全控制和流量控制等。
3.Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
4.Service 层:业务逻辑层。
5.Manager 层:通用业务处理层。这一层主要有两个作用,其一,你可以将原先 Service 层的一些通用能力下沉到这一层,比如与缓存和存储交互策略,中间件的接入;其二,你也可以在这一层封装对第三方接口的调用,比如调用支付服务,调用审核服务等。
6.DAO 层:数据访问层,与底层 MySQL、Oracle、HBase 等进行数据交互。
7.外部接口或第三方平台:包括其它部门 RPC 开放接口,基础平台,其它公司的 HTTP 接口。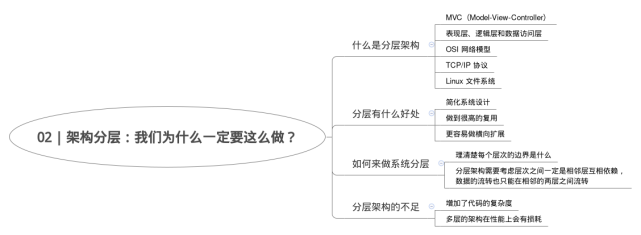
高并发性能优化,
1.一种提高系统的处理核心数,另一种是减少单次任务的响应时间(采用工具分析,通过监控来发现性能问题)。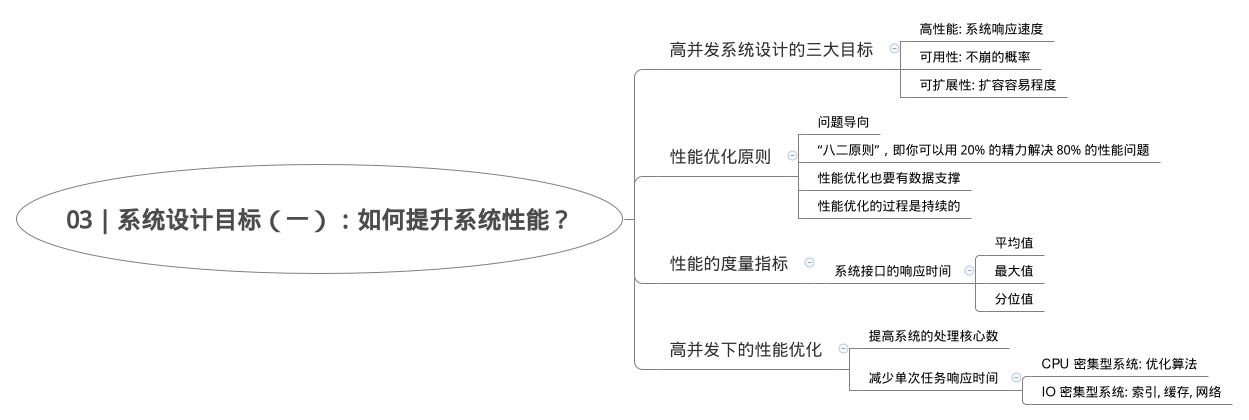
高可用,
1.一个成熟系统的可用性需要从系统设计和系统运维两方面来做保障,两者共同作用,缺一不可。
2.在做系统设计的时候,要把发生故障作为一个重要的考虑点,预先考虑如何自动化地发现故障,发生故障之后要如何解决 (监控系统)
3.还需要掌握一些具体的优化方法,比如 failover(故障转移)、超时控制以及降级和限流。
4.failover作用如果访问某一个节点失败,那么简单地随机访问另一个节点就好了。
5.灰度发布、故障演练。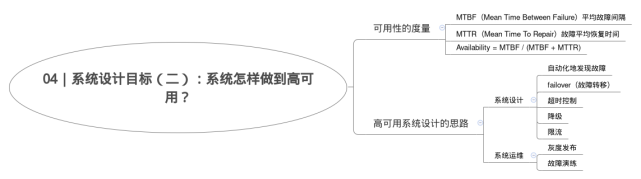
扩展性,
1.多台机器组成集群系统,通过增加机器的方式来线性提高系统的处理能力,从而承担更高的流量和并发。
2.拆分是把庞杂的系统拆分成独立的,有单一职责的模块(业务维度拆分,按照数据特征做水平的拆分)。
3.业务的维度拆分成用户池、内容池、关系池、评论池、点赞池和搜索池。
4.还可以根据业务接口的重要程度,把业务分为核心池和非核心池。
5.还可以根据接入客户端类型的不同做业务池的拆分。
注意:尽量不要使用事务,因为当一个事务中同时更新不同的数据库时,需要使用二阶段提交,来协调所有数据库要么全部更新成功,要么全部更新失败。这个协调的成本会随着资源的扩展不断升高,最终达到无法承受的程度。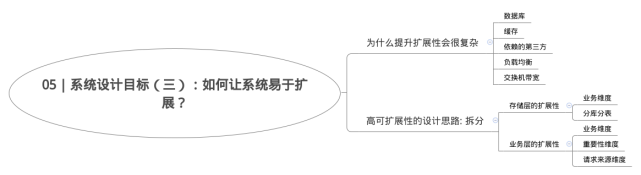
组件原理可以解决问题,
1.修改组件源码,提升业务处理能力。
2.开源项目构成,都是由各个组件组合而成的。
3.拆分成不同功能模块,形成独立组件,让宿主调用。
4.适应并行开发,解耦各个模块,避免模块之间的交叉依赖,加快编译速度, 从而提高并行开发效率。
5.代码解耦,组件单独运行,组件间通信,组件生命周期,集成调用,代码隔离,本地广播,进程间的AIDL,匿名的内存共享,Intent Bundle传递。
6.不断深入原理是在摸清知识的边界,考察知识的深度,了解你在遇到问题时解决问题的能力。
池化技术,
1.启动一个线程来定期检测连接池中的连接是否可用。
2.在获取到连接之后,先校验连接是否可用。
3.池化技术它的核心思想是空间换时间,期望使用预先创建好的对象来减少频繁创建对象的性能开销,同时还可以对对象进行统一的管理,降低了对象的使用的成本,总之是好处多多。
4.存储池子中的对象肯定需要消耗多余的内存,如果对象没有被频繁使用,就会造成内存上的浪费。
5.池子中的对象需要在系统启动的时候就预先创建完成,这在一定程度上增加了系统启动时间。
主从同步延迟,
1.第一种方案是数据的冗余。你可以在发送消息队列时不仅仅发送微博 ID,而是发送队列处理机需要的所有微博信息,借此避免从数据库中重新查询数据。
2.第二种方案是使用缓存。我可以在同步写数据库的同时,也把微博的数据写入到 Memcached 缓存里面,这样队列处理机在获取微博信息的时候会优先查询缓存,这样也可以保证数据的一致性。
3.最后一种方案是查询主库。我可以在队列处理机中不查询从库而改为查询主库。不过,这种方式使用起来要慎重,要明确查询的量级不会很大,是在主库的可承受范围之内,否则会对主库造成比较大的压力。
4.第一类以淘宝的 TDDL( Taobao Distributed Data Layer)为代表,以代码形式内嵌运行在应用程序内部。你可以把它看成是一种数据源的代理,它的配置管理着多个数据源,每个数据源对应一个数据库,可能是主库,可能是从库。当有一个数据库请求时,中间件将 SQL 语句发给某一个指定的数据源来处理,然后将处理结果返回。
5.另一类是单独部署的代理层方案,这一类方案代表比较多,如早期阿里巴巴开源的 Cobar,基于 Cobar 开发出来的 Mycat,360 开源的 Atlas,美团开源的基于 Atlas 开发的 DBProxy 等等。

若有收获,就点个赞吧
0 人点赞
