本文主要介绍腾讯大数据编译器研发团队自研的Java协程Kona Fiber最近一年来完善易用性(支持synchronized锁、死锁检测、网络操作)的工作。
▍协程用于解决什么问题?
图1.1展示了线程模型的常见做法,图中左侧的queue是一个任务队列,线程从任务队列里取任务执行,遇到IO操作时线程让出cpu。
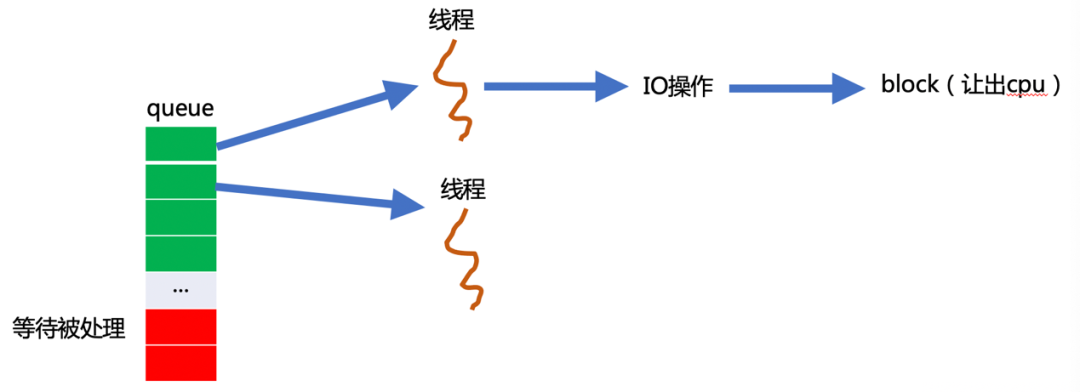
图1.1
互联网业务通常是高并发的,所谓高并发是指同时有多个任务被执行。如果用图1.1的线程模型去实现,就会存在两个明显的问题:
- 一个线程对应一个任务,即一个线程对应一个并发:线程的内存开销较大(通常超过1M),因此单机的线程个数就会受限(如果机器有32G,也只能创建3.2万个线程),继而限制单机的并发数;
- 对于类似图1.1的IO密集型业务(每个任务都要去访问外部数据库/网络),线程执行IO操作时,会让出CPU,CPU会切换到一个可以执行的线程。这种线程切换不是免费的,对于8核16G的机器,在CPU打满的情况下,每秒可以切换几十万次。也就是说,如果使用线程模型,当线程个数过多且切换频繁时,CPU会大量浪费在线程切换上,导致真正执行业务的CPU占比不高。
在协程出现以前,业务的高并发+IO密集型业务的需求是如何满足的呢?对于Java生态,可以选择各种各样的异步编程框架。这些异步编程框架,核心是一个线程能够同时完成多个业务,也就是一个线程对应多个并发(经典的线程模型是一个线程对应一个并发)。异步编程框架在理论上可以完美解决问题,但是异步编程框架存在两个问题:
- 异步编程框架需要程序员自己掌握程序的上下文切换时机,程序员需要知道哪些操作会导致线程Block,在线程Block之前切换到另一个上下文,然后等Block操作结束之后再切换回原上下文继续执行。这显然提高了对编程者的要求。
- 使用异步编程框架,由于一个线程上同时包含多个执行上下文,因此线程的调用栈通常难以理解,如果出现问题,很难诊断定位。因此异步编程的维护通常比经典的线程模型更困难。
协程提供了异步编程的能力,又保留了线程模型的简单性。使用协程,用户可以按照线程模型进行编程,同时获得接近异步编程的性能,且可以根据并发数创建任意数量的协程(单机可以创建几十万协程,Loom支持单机几千万的协程数量)
▍OpenJDK社区已有Loom,为什么还要自研Kona Fiber?
1、业务需要一个在JDK8/JDK11上稳定可用的协程实现
Loom作为OpenJDK社区的官方实现,目前基于前沿版本开发(当前为JDK19)。如果用户现在使用Loom,至少面对两个难点:
- Loom基于前沿版本开发,用户需要升级到JDK19,业务要为升级JDK作出很多改动、适配和压测。对于一些有外部依赖的业务,要等待外部依赖也升级到JDK19时才能升级。
- Loom仍处于开发状态,不断有新代码合入。如果使用过程中出现问题,社区不保证bug修复的时间。对于大多数业务来说,很难将业务问题提炼到向社区反馈的程度(社区要求写一个稳定复现问题的小case,需要报bug的人有一定的问题分析能力)
与Loom相比,Kona Fiber有如下特点:
- 基于JDK8/JDK11开发:JDK8/JDK11涵盖了绝大多数Java业务,无需升级JDK即可使用Kona Fiber。
- 提供协程的核心能力:一个完整的协程实现,包含协程切换的能力、调度器的优化、类库的改造、新的语法糖的引入等等。Kona Fiber主要实现协程切换、调度器的优化,改造必要的类库,暂时不增加新的语法糖,不引入新的概念。
- 保障协程的稳定性、及时的bug修复。
2、兼容Loom API:零成本升级Loom
虽然当前业务使用JDK8/JDK11,但是未来业务的JDK总归是要升级的。从代码演进性的角度,Kona Fiber在接口设计上和Loom保持一致。用户在切换到高版本JDK时,可以不加任何修改直接使用Loom替换Kona Fiber。
3、提供更好的切换效率
Loom采用stack copy的方案实现协程切换,当协程A切换到协程B时,需要将协程A的执行栈从线程拷贝到Java Heap,将协程B的栈从Java Heap中拷贝到当前线程的执行栈上。这种拷贝操作的好处是,协程的栈可以按需使用,不需要为协程的栈预留内存。
Kona Fiber是真正意义上的stackful实现,每个协程有独立的栈,切换时无需拷贝,只需要简单的切换rsp、rbp寄存器,保存一些基本的执行状态即可。因此Kona Fiber的切换效率相比Loom更高,占用的内存相比Loom稍多。图2.1展示了Kona Fiber、Loom、JKU的切换效率、内存占用的对比。
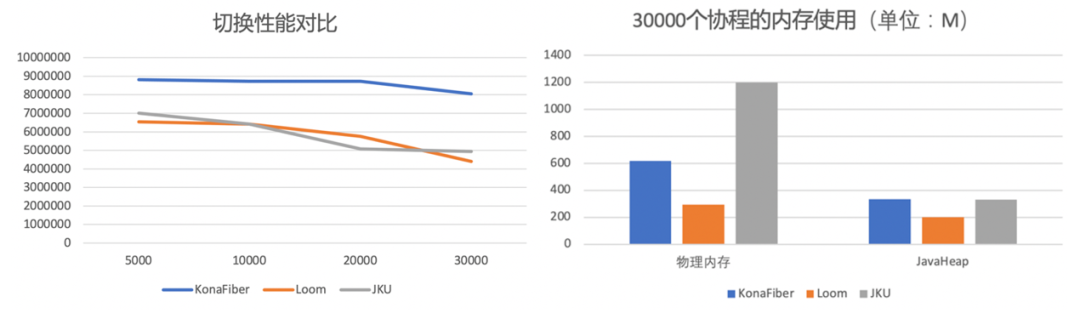
图2.1
▍腾讯自研协程Kona Fiber最近一年的改进
Kona Fiber主要从易用性(支持synchronized锁、死锁检测、网络操作)和完整性(Kona Fiber 11支持ZGC)两个角度进行完善,下图是Kona Fiber和Loom、JKU的对比:

1、支持synchronized锁
为什么协程需要支持synchronized锁?
在jvm中,synchronized锁膨胀为重量级锁时,锁的owner被标记成线程。如下图所示,VT_0和VT_1都是运行在Worker Thread 0上的协程,VT_0在执行过程中申请了一个重量级锁A,图中的yield表示协程切换操作。当VT_0遇到IO操作,让出执行权限时,VT_1被调度执行。如果VT_1也尝试去获取重量级锁A,因为重量级锁A此时的owner被标记成Worker Thread 0,且Java支持锁重入,所以VT_1也可以执行重量级锁A保护的临界区。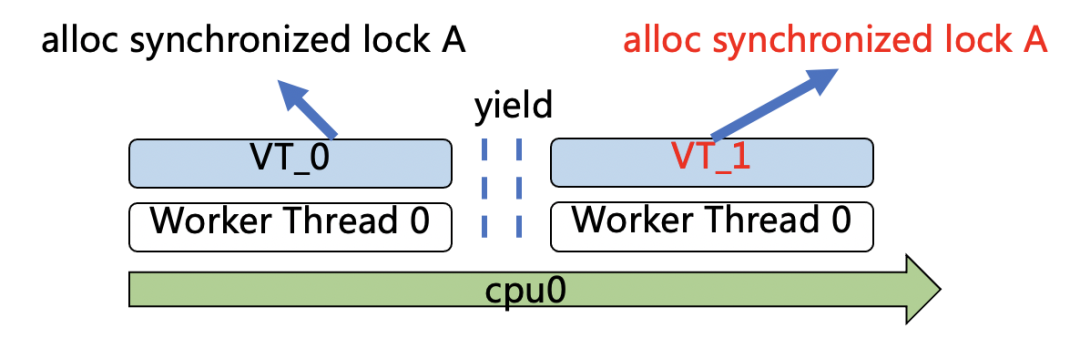
图3.2
协程在设计时,希望用户在使用协程时可以按照线程模型进行编程。如果用户把协程当作线程,那么synchronized的语义就可能失效,导致业务代码的逻辑出现问题。
下图展示了Loom的解决方案,本质上是在持有synchronized锁时不允许协程和线程分离,即协程绑住线程,另一个协程只能去新的线程上执行,cpu被迫执行一个较重的线程切换(即图中的context switch),这就是Loom引入的Pin的概念,即所谓的“协程退化成线程”。当持有synchronized锁时,通过禁止协程切换的方式,防止由于synchronized锁的出现导致临界区失效。
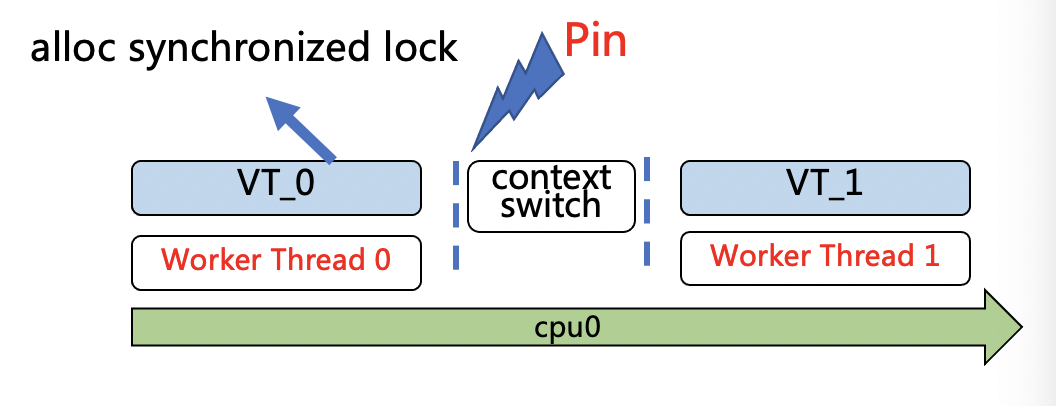 图3.3
图3.3
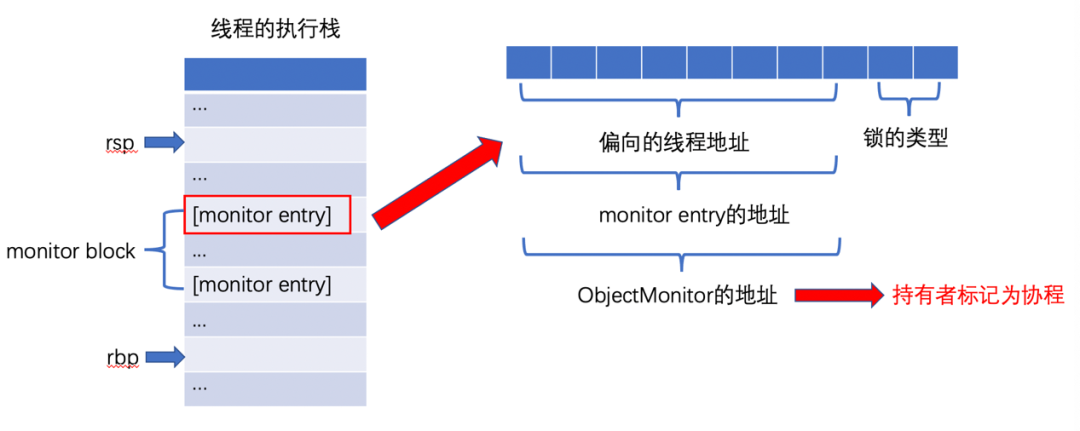
修改synchronized锁的owner
下图展示了synchronized锁的三种状态:偏向锁、轻量级锁、重量级。
- 偏向锁:在benchmark中有明显效果,但在实际业务中通常效果不大,在最新版本的jdk已经被移除,所以协程暂不支持偏向锁,即使用协程时自动关闭偏向锁。
- 轻量级锁:由于轻量级锁保存的owner是线程或协程的栈上地址,Kona Fiber作为有栈协程天然支持轻量级锁。
- 重量级锁:重量级锁保存的owner是持有锁的线程,需要将其改为持有锁的协程;
动态调整ForkJoinPool的可用线程
上述方案解决了协程持有synchronized锁切换的问题,当协程申请synchronized锁失败时,协程会block在jvm中,此时仍相当于协程退化成线程。协程在执行时需要挂载到线程上,协程个数通常远远多于运行协程的线程个数。绝大多数情况下,用户不需要感知运行协程的线程(类似用户使用线程编程时,不需要感知物理CPU),这时默认会创建一个ForkJoinPool作为运行协程的调度器。
当协程由于申请synchronized锁失败而block在jvm中时,会在ForkJoinPool线程不足时调用compensate动态调整ForkJoinPool的线程个数。
2、支持死锁检测
- 死锁检测原理分析
死锁检测是程序员常用的功能。由于协程的个数较多,如果没有辅助工具帮助用户进行死锁检测,逐一排查通常是一件耗时耗力的事。
死锁检测本质上是一个寻找环的过程,下图展示了线程死锁检测的逻辑。首先需要有一个出发点,例如图中的thread0:
- 检查thread0的状态,如果thread0是runnable状态,证明没有死锁,再另外寻找出发点。图中的thread 0是Block状态,block的原因是申请lock A失败;
- 接下来寻找lock A的owner,即图中的thread1,如果thread1是runnable状态,则没有死锁。图中的thread1在等待lock B,接下来寻找lock B的owner。
- lock B的owner是thread2,由于thread2在等待lock C,且lock C的owner是thread0,那么thread0、thread1、thread2就组成了一个环,即找到了死锁的线程。
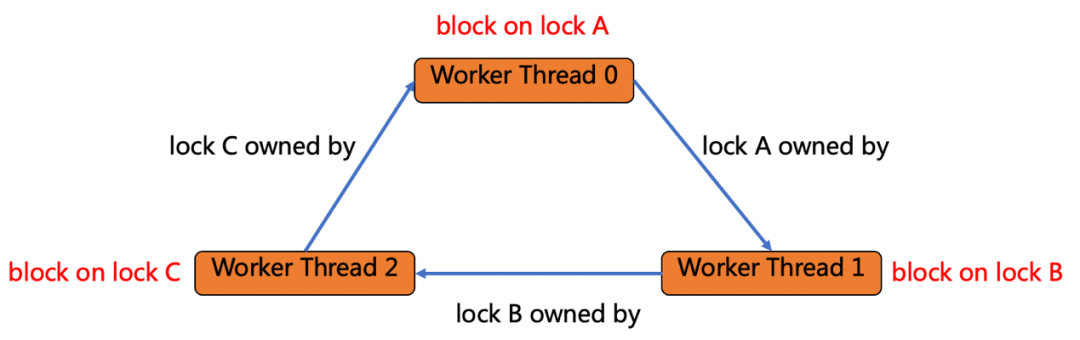
图3.6
协程死锁检测的demo
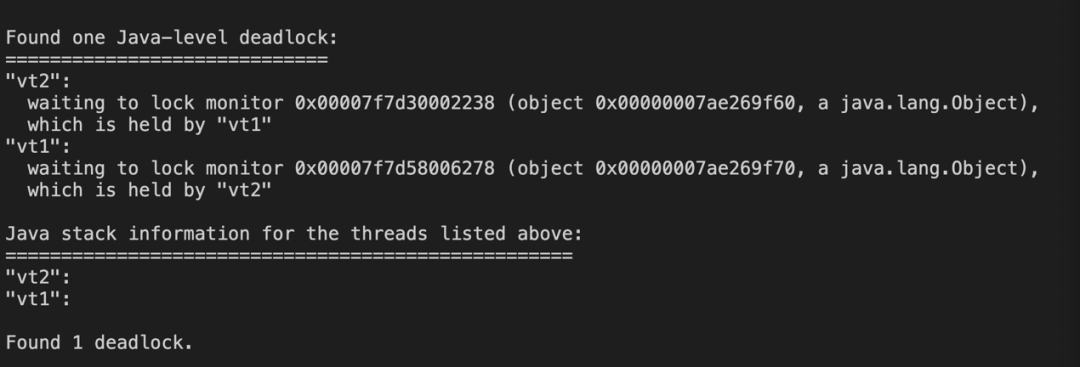
如下图所示,展示了协程死锁检测的运行结果。
- vt1:持有Synchronized A,等待Synchronized B;
- vt2:持有Synchronized B,等待Synchronized A;
- vt1和vt2组成一个死锁的环,对应的demo参看Kona Fiber 8:jdk/test/java/lang/VirtualThread/DeadLockTest.java
3、支持网络操作
协程执行网络操作产生的问题
如下图所示,展示了基本的TCP操作:
- 服务端bind对应的ip+端口;
- 服务端执行listen()等待客户端发起连接请求;
- 客户端调用connect()向服务端发起连接请求;
- 服务端收到客户端的连接请求,调用accept();
- 服务端执行accept()以后,tcp连接就建立完成,服务端和客户端各有一个Socket,可以调用send()和receive()进行消息发送和接收。
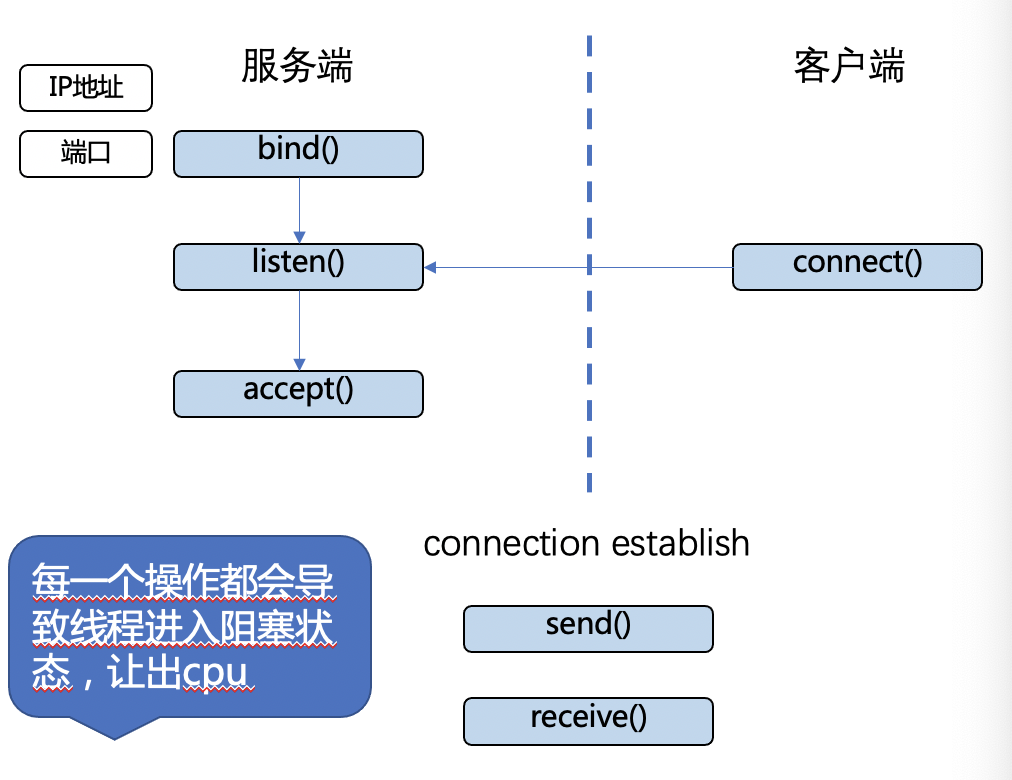
图3.8
问题是,这些操作在jvm上都是同步操作,且阻塞在jvm内部,对应的代码如下所示:
#define BLOCKING_IO_RETURN_INT(FD, FUNC) { \int ret; \threadEntry_t self; \fdEntry_t *fdEntry = getFdEntry(FD); \if (fdEntry == NULL) { \errno = EBADF; \return -1; \} \do { \startOp(fdEntry, &self); \ret = FUNC; \endOp(fdEntry, &self); \} while (ret == -1 && errno == EINTR); \return ret; \}
代码中的FUNC就对应每种操作,例如connect()、accept()等。这种block在native的操作,会导致协程退化成线程,因此协程需要做额外的适配。
如何适配协程?
下图展示了协程适配网络操作的基本思路:
- 将socket对应的fd设置为non-blocking模式,如果执行accept()等操作时需要等待,则返回unavailable;
- 协程遇到unavailable时,将网络操作对应的fd交给epoll监听,执行网络操作的协程通过park()让出执行权限,切换到另一个runnable状态的协程执行;
- 有一个独立的EPollPoller线程负责监听所有协程注册的fd,如果对应的fd收到事件,则unpark对应的协程;
- 协程被唤醒后,会再次执行网络操作,例如accept(),如果成功获得则返回。
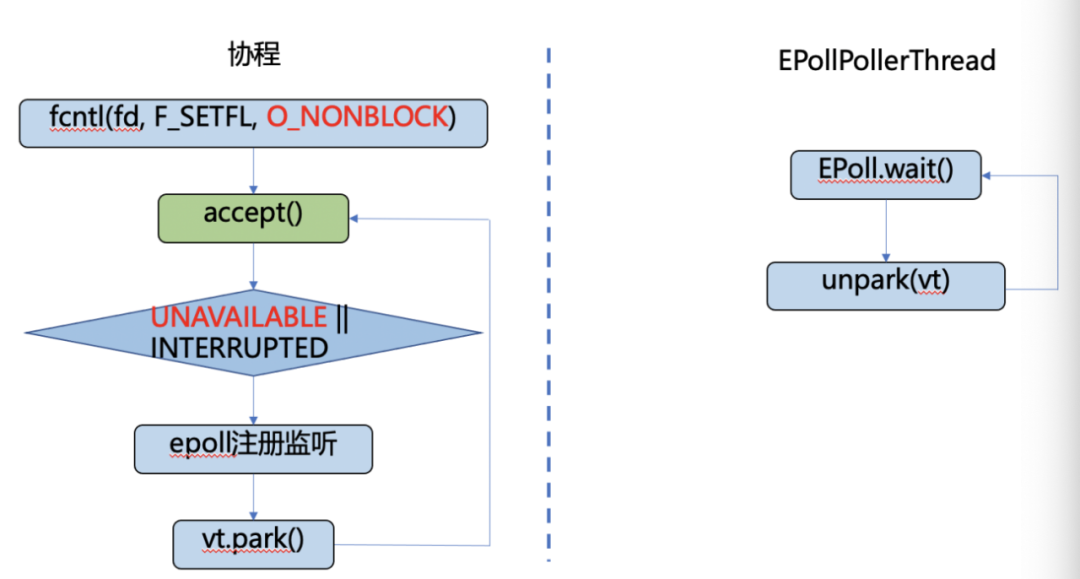
图3.9
▍传送门
更多Kona JDK信息请访问下面链接。
- Kona 8协程对外开源版本,欢迎star: https://github.com/Tencent/TencentKona-8/tree/KonaFiber
- Kona 11协程对外开源版本,欢迎star:https://github.com/Tencent/TencentKona-11/tree/KonaFiber
- Kona技术交流群,欢迎加入:

若有收获,就点个赞吧
0 人点赞
