分区
> 概述
分区(Partitioning)是一种最为简单的拓展方式。
在我们面临单机的存储空间瓶颈时,第一点就能想到像传统的关系型数据库一样,进行数据分区。
或者假设手中有N台机器可以作为Redis服务器,所有机器内存总和有256G, 而客户端正好也需要一个大内存的存储空间。
我们除了可以把内存条都拆下来焊到一个机器上,也可以选择分区使用,这样又拓展了计算能力。
单指分区来讲,即将全部数据分散在多个Redis实例中,每个实例不需要关联,可以是完全独立的。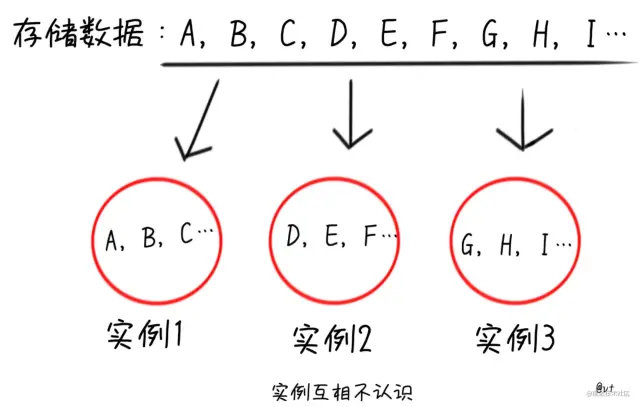
> 使用方式
- 客户端处理
和传统的数据库分库分表一样,可以从key入手,先进行计算,找到对应数据存储的实例在进行操作。范围角度,比如orderId:1~orderId:1000放入实例1,orderId:1001~orderId:2000放入实例2。
哈希计算,就像我们的hashmap一样,用hash函数加上位运算或者取模,高级玩法还有一致性Hash等操作,找到对应的实例进行操作 使用代理中间件
我们可以开发独立的代理中间件,屏蔽掉处理数据分片的逻辑,独立运行。
当然也有他人已经造好的轮子,Redis也有优秀的代理中间件,譬如Twemproxy,或者codis,可以结合场景选择是否使用。> 缺点
无缘多key操作,key都不一定在一个实例上,那么多key操作或者多key事务自然是不支持。
- 维护成本,由于每个实例在物理和逻辑上,都属于单独的一个节点,缺乏统一管理。
- 灵活性有限,范围分片还好,比如hash+MOD这种方式,如果想动态调整Redis实例的数量,就要考虑大量数据迁移,这就非常麻烦了。
同为开发者,深知我们虽然总能“曲线救国”的完成一些当前环境不支持的功能,但是总归要麻烦一些。
主从
> 概述数据迁移
常说的主从(Master-Slave),也就是复制(Replication)方式,怎么称呼都可以。
同上面的分区一样,也是Redis高可用架构的基础,新手可能会误以为这类基础模式即是“高可用”,这并不是十分正确的。
分区暂时能解决单点无法容纳的数据量问题,但是一个Key还是只在一个实例上,在大流量时代显得不那么可靠。
主从就是另一个纬度的拓展,节点将数据同步到从节点,就像将实例“分身”了一样,可靠性又提高了不少。
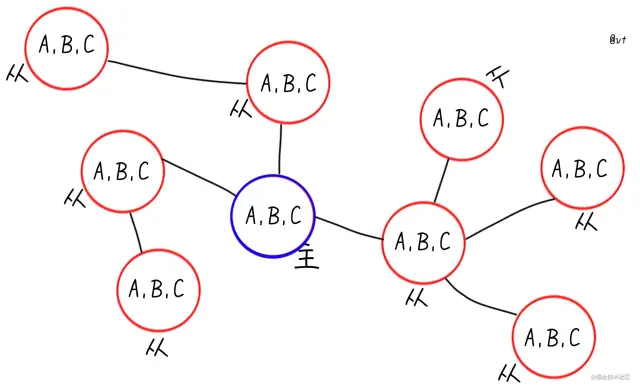
图画的有些夸张了,主要还是想体现结构灵活,是一主一从,还是一主多从,还是一主多从多从… 看你心情
有了“实例分身”,自然就可以做读写分离,将读流量均摊在各个从节点。
> 使用方式
高手云集的时代,聊天软件难免要备上这么一张表情包。
这表情包和使用方式有什么关系呢?首先看看使用方式:
- 作为主节点的Redis实例,并不要求配置任何参数,只需要正常启动
- 作为从节点的实例,使用配置文件或命令方式REPLICAOF 主节点Host 主节点port即可完成主从配置
是不是和表情包一样,“dalao”没动,我去“抱大腿”。
这样一个主从最小配置就完成了,主从实例即可对外提供服务。
命令里的“主节点”是相对的,slave也可以抱slave大腿,也就是上文提到的结构灵活。
> 缺点
- slave节点都是只读的,如果写流量大的场景,就有些力不从心了。
那我把slave节点只读关掉不就行了?当然不行,数据复制是由主到从,从节点独有数据同步不到主节点,数据就不一致了。 - 故障转移不友好,主节点挂掉后,写处理就无处安放,需要手工的设定新的主节点,如使用REPLICAOF no one(谁大腿我都不抱了) 晋升为主节点,再梳理其他slave节点的新主配置,相对来说比较麻烦。
哨兵
> 概述
主从的手工故障转移,肯定让人很难接受,自然就出现了高可用方案-哨兵(Sentinel)。
我们可以在主从架构不变的场景,直接加入Redis Sentinel,对节点进行监控,来完成自动的故障发现与转移。
并且还能够充当配置提供者,提供主节点的信息,就算发生了故障转移,也能提供正确的地址。
哨兵本身也是Redis实例的一种,但不作为数据存储方使用,启动命令也是不一样的。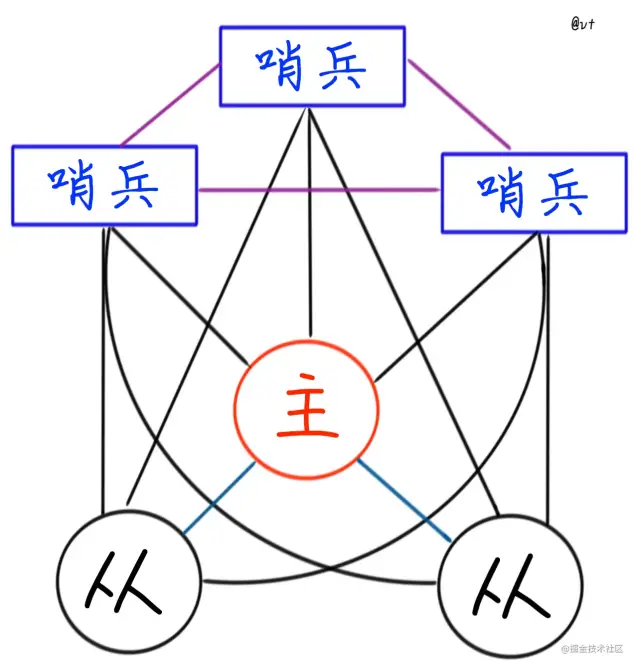
> 使用方式
Sentinel的最小配置,一行即可:
只需要配置master即可,然后用redis-sentinel <配置文件> 命令即可启用。
Redis官网提到的“最小配置”是如下所示,除了上面提到的一行,还有其它的一些配置: ```go sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 60000 sentinel failover-timeout mymaster 180000 sentinel parallel-syncs mymaster 1sentinel monitor <主节点别名> <主节点host> <主节点端口> <票数>
sentinel monitor resque 192.168.1.3 6380 4 sentinel down-after-milliseconds resque 10000 sentinel failover-timeout resque 180000 sentinel parallel-syncs resque 5
这是因为官网加了一个修饰词,是“**典型的最小配置**”,把重要参数和**多主**的例子都写出来了,照顾大家CV大法的时候,不要忘记重要参数,其实都是有默认值的。正如该例所示,设置**主节点别名**就是为了监控**多主**的时候,与其额外配置项能够与其对应, 以及sentinel一些命令,如SENTINEL get-master-addr-by-name就要用到别名了。<br />哨兵数量建议在三个以上且为奇数,在Redis官网也提到了各种情况的“布阵”方式,非常值得参考。<a name="DcbEd"></a>### **> 更多**既然是高可用方案,并非有严格意义上的“缺点”,还需配合使用场景进行考量。- 故障转移期间短暂的不可用,但其实官网的例子也给出了parallel-syncs参数来指定并行的同步实例数量,以免全部实例都在同步出现整体不可用的情况,相对来说要比手工的故障转移更加方便。- 分区逻辑需要自定义处理,虽然解决了主从下的高可用问题,但是Sentinel并没有提供分区解决方案,还需开发者考虑如何建设。- 既然是还是主从,如果异常的写流量搞垮了主节点,那么自动的“故障转移”会不会变成自动“灾难传递”,即slave提升为Master之后挂掉,又进行提升又被挂掉。<a name="hkXiu"></a>## **集群**<a name="MsfM6"></a>### **> 概述****Redis Cluster**是官方在**3.0**版本后推出的分布式方案。<br />对开发者而言,“官方支持”一词是大概率非常美好的,小到issue,大到feature。自定义去解决问题,成本总是要高一些。<br />有了官方的正式集群方案,从**请求路由、故障转移、弹性伸缩**几个纬度的使用上,将更为容易。<br />**Cluster**不同于哨兵,是支持分区的。有说法Cluster是哨兵的升级,这是不严谨的。<br />二者纬度不一样,如果因为Cluster也有故障转移的功能,就说它是哨兵的升级款,略显牵强。<br />**Cluster**在分区管理上,使用了“**哈希槽**”(hash slot)这么一个概念,一共有**16384**个槽位,每个实例负责一部分**槽**,通过CRC16(key)&16383这样的公式,计算出来key所对应的槽位。<br />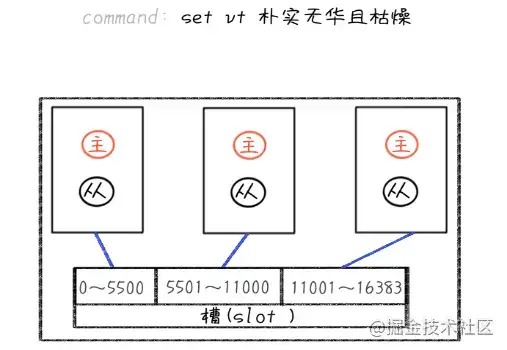虽然在**节点**和**key**二者中又引入了**槽**的概念,看起来不易理解,实际上因为颗粒度更细了,减少了节点的扩容和收缩难度,相比传统策略还是很有优势。<br />当然,“槽”是虚拟的概念,节点自身去维护“槽”的关系,并不是要真正下载启动个“槽服务”在跑。<a name="Ej4pj"></a>### **> 使用方式**Redis的各种玩法,都是从配置文件着手,集群也不例外。<br />关键配置简洁明了,有两步```gocluster-enabled yescluster-config-file "redis-node.conf"
- 开启集群
- 指定集群配置文件
集群配置文件(cluster-config-file)为内部使用,可以不去指定,Redis会帮助创建一个。启动还是普通的方式redis-server redis.conf
首先以集群方式启动了N台Redis实例,这当然还没完事。
接下来的步骤笔者称为“牵线搭桥分配槽”,听起来还算顺口。
“牵线搭桥分配槽”的方式也在不断升级,从直接用原始命令来处理,到使用脚本,以及现在的Redis-cli官方支持,使用哪种方式都可以。
上方的命令即是Redis官网给出的redis-cli的方式用法,一行命令完成“三主三从”以及自动分配槽的操作。
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \--cluster-replicas 1
这样集群就搭建完成了,当然,使用官方提供的check命令检查一下,也是有必要的。
> 更多
redis-cli --cluster check 127.0.0.1:7001
- 虽然是对分区良好支持,但也有一些分区的老问题,譬如:如果不在同一个“槽”的数据,是没法使用类似mset的多键操作。
- 在select命令页有提到, 集群模式下只能使用一个库,虽然平时一般也是这么用的,但是要了解一下。
- 运维上也要谨慎,俗话说得好,“使用越简单底层越复杂”,启动搭建是很方便,使用时面对带宽消耗,数据倾斜等等具体问题时,还需人工介入,或者研究合适的配置参数。

若有收获,就点个赞吧
0 人点赞
