关于正则表达式的语法,可以参考 - Python 正则,这篇主要介绍在 JavaScript 中,正则的应用。
正则表达式
ECMAScript通过 RegExp 类型支持正则表达式。正则表达式使用类似 Perl的简洁语法来创建:
let expression = /pattern/flags;
这个正则表达式的 pattern (模式)可以是任何简单或复杂的正则表 达式,包括字符类、限定符、分组、向前查找和反向引用。每个正则表达式 可以带零个或多个 flags (标记),用于控制正则表达式的行为。下面给 出了表示匹配模式的标记。
这个正则表达式的 pattern (模式)可以是任何简单或复杂的正则表 达式,包括字符类、限定符、分组、向前查找和反向引用。每个正则表达式 可以带零个或多个 flags (标记),用于控制正则表达式的行为。下面给 出了表示匹配模式的标记。
g :全局模式,表示查找字符串的全部内容,而不是找到第一个匹配 的内容就结束。
i :不区分大小写,表示在查找匹配时忽略 pattern 和字符串的大 小写。
m :多行模式,表示查找到一行文本末尾时会继续查找。
y :粘附模式,表示只查找从 lastIndex 开始及之后的字符串。
u :Unicode模式,启用Unicode匹配。
s : dotAll 模式,表示元字符 . 匹配任何字符(包括 \n 或 \r )。
test
/*new RegExp('a') 匹配规则test('abc') 匹配源 | 返回布尔值*/new RegExp('a').test('abc') // truenew RegExp('a').test('bcd') // false/*/.../ 是 RegExp 对象的简写,两者是等价的*//a/.test('abc') // true/a/.test('bcd') // false
exec
/b/.exec('abc') // ["b", index: 1, input: "abc"]/*返回匹配的信息[0] 匹配内容[1] 首次匹配位置[2] 匹配源*/
match
'abc'.match(/a/) // ["a", index: 0, input: "abc"]/*match 和 exec 的作用是一样的,只是 match 是字符串方法,而 exec 是正则方法*/
replace
'a'.replace(/\w/,'b') // b/*替换,也是一个支持正则的字符串方法*/
search
'cba'.search(/a/) // 2/*查找字符串位置,不存在返回 -1,可以看出是一个正常正则的 indexOf*/
split
'a b c'.split(/\s+/) // ['a','b','c'] | 裁剪
分组
/(a)(b)/.exec('ab') // ["ab", "a", "b", index: 0, input: "ab"]'ab'.match(/(a)(b)/) // ["ab", "a", "b", index: 0, input: "ab"]/*() 括号是特别的标示,不会影响正则匹配,括号的内容会单独返回出来,这种操作叫做分组exec 和 match 都支持分组功能*/
符号
/*g 全局 | 匹配多次*/'a1a'.match(/a/g) // ['a','a'] | 默认只匹配一次/*i 忽略大小写*//a/.test('A') // true/*m 多行匹配 | 即使文本换行了也能被匹配到*//^1/.test('\n1') // false/^1/m.test('\n1') // true
应用举例:
我有一个列表(在一个.txt文件),我想快速转换为JavaScript语法,
需要将其转为这样的数组格式
[“桜色”,”#bf242a”],
源文件如下:
桜色#bf242a薄桜#fdeff2桜鼠#e9dfe5鸨鼠#e4d2d8虹色#f6bfbc珊瑚色#f5b1aa...
使用工具notepad++
1.在notepad++中打开文件
2.ctrl+h 替换字符
3.先在开头结尾加上引号
行首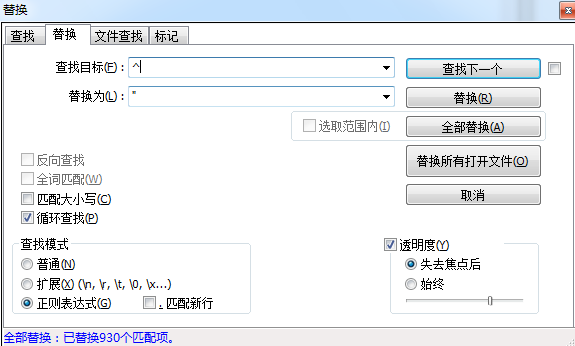
行尾
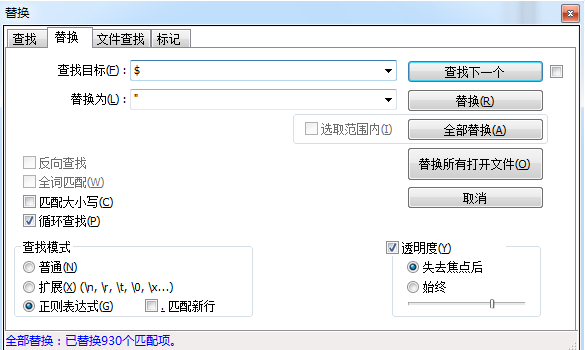
点击全部替换即可。
import jsonli = []with open("china.json",'r',encoding='UTF-8') as load_f:#load_dict = json.load(load_f)str = load_f.read()str_li = str.replace('\n',',').split(',')n = 0strs = ""for i in str_li:n+=1strs += i+','if n == 2:li.append(strs[:-1])strs = ""n=0for i in li:print(i)

或者直接这样,四行代码搞定
with open('china.txt', 'r', encoding='UTF-8') as chinacolor:asList = chinacolor.read().splitlines()for i in range(0, len(asList), 2):print("[\""+asList[i]+"\"",',',"\""+asList[i+1]+"\"]")

若有收获,就点个赞吧
0 人点赞
