解决的问题
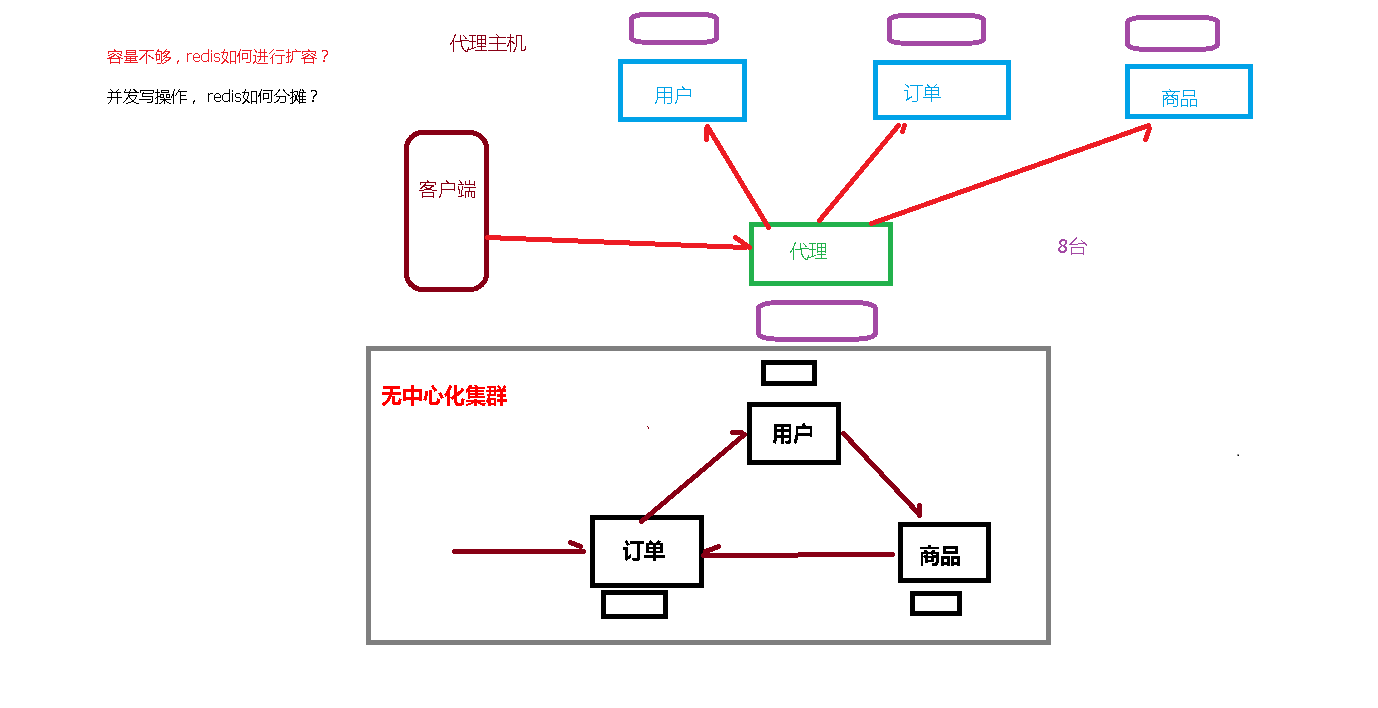
- 容量不够,redis如何进行扩容?
- 并发写操作, redis如何分摊?
- 另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。之前通过代理主机来解决,但是redis3.0中提供了解决方案。就是无中心化集群配置。集群中,任何一台服务器都可作为集群入口,取消了之前的代理服务器
什么是集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
集群演示
docker方式
https://www.cnblogs.com/pengboke/p/14999191.html
https://www.cnblogs.com/niceyoo/p/13011626.html
普通方式
https://blog.csdn.net/qq_42815754/article/details/82912130
redis cluster 如何分配这六个节点?
- 一个集群至少要有三个主节点。
- 选项 –cluster-replicas 1 :表示我们希望为集群中的每个主节点创建一个从节点。
- 分配原则尽量保证每个主数据库运行在不同的 IP 地址,每个从库和主库不在一个 IP 地址上。
什么是slots
一个 Redis 集群包含 16384 个插槽(hash slot),数据库中的每个键都属于这 16384 个插槽的其中一个。集群使用公式 CRC16 (key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16 (key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
- 节点 A 负责处理 0 号至 5460 号插槽。
- 节点 B 负责处理 5461 号至 10922 号插槽。
- 节点 C 负责处理 10923 号至 16383 号插槽。
在集群中录入值
在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。
redis-cli客户端提供了–c 参数实现自动重定向。如redis-cli -c–p 6379登入后,再录入、查询键值对可以自动重定向。不在一个slot下的键值,是不能使用mget,mset等多键操作。
可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。
查询集群中的值
CLUSTER GETKEYSINSLOT 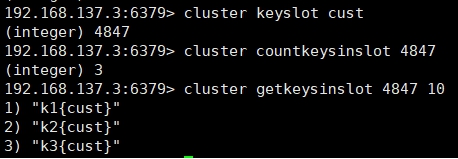
故障恢复
如果主节点下线?从节点能否自动升为主节点?注意:15秒超时
主节点恢复后,主从关系会如何?主节点回来变成从机。
如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
- 如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么,整个集群都挂掉
- 如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使用,也无法存储。
redis.conf中的参数 cluster-require-full-coverage
集群的Jedis开发
即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。
无中心化主从集群。无论从哪台主机写的数据,其他主机上都能读到数据。
public class JedisClusterTest {public static void main(String[] args) {Set<HostAndPort>set =new HashSet<HostAndPort>();set.add(new HostAndPort("192.168.31.211",6379));JedisCluster jedisCluster=new JedisCluster(set);jedisCluster.set("k1", "v1");System.out.println(jedisCluster.get("k1"));}}
Redis 集群的好处

若有收获,就点个赞吧
0 人点赞
