Prometheus 简介
http://www.51niux.com/?id=244
https://yunlzheng.gitbook.io/prometheus-book
https://blog.csdn.net/weixin_46837396/article/details/120062123
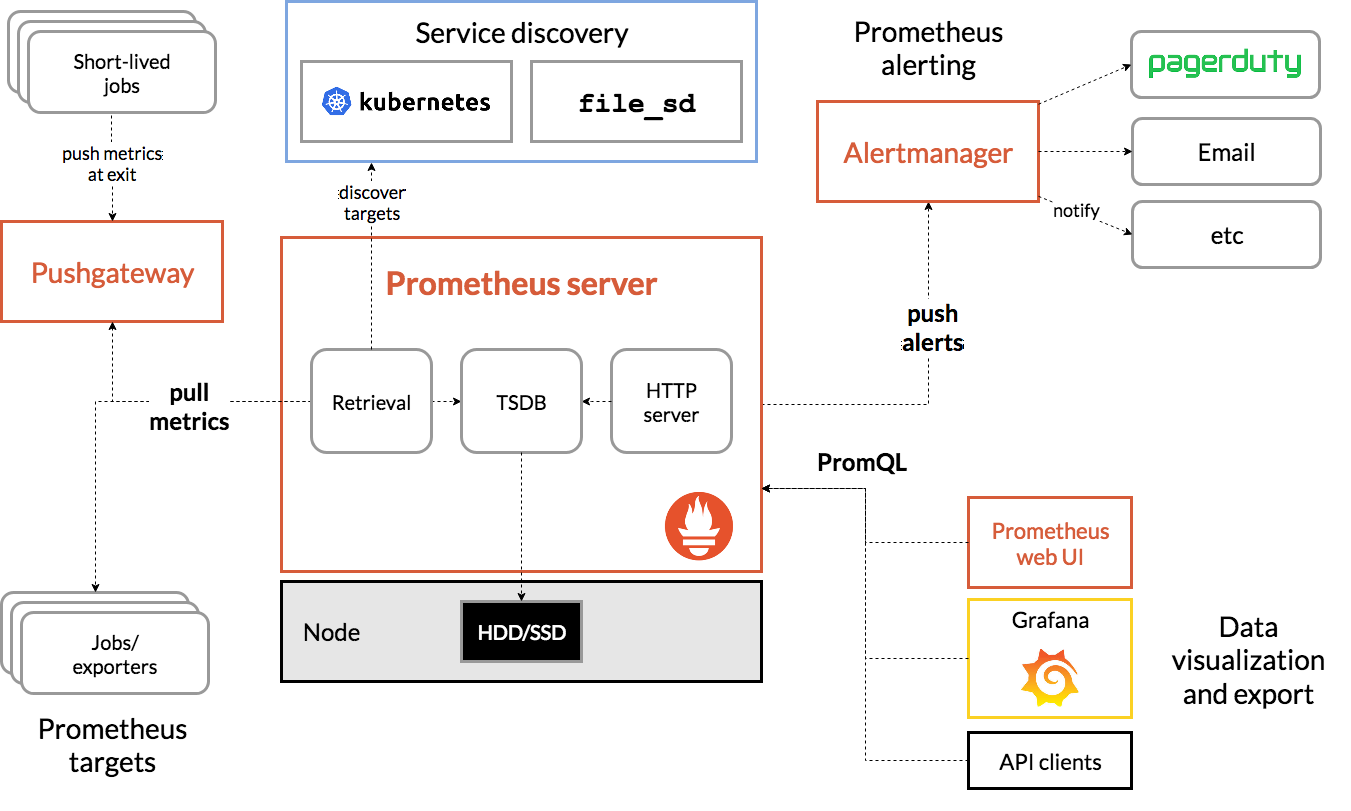
Prometheus Operator
https://github.com/prometheus-operator
Prometheus Operator可以配置原生Kubernetes并且可以管理和操作Prometheus和Alertmanager集群
该Operator引入了以下Kubernetes自定义资源定义(CRDs):Prometheus、ServiceMonitor、PrometheusRule和Alertmanager
更多内容可以访问链接:
https://github.com/coreos/prometheus-operator/blob/master/Documentation/design.md
告警策略
https://github.com/samber/awesome-prometheus-alerts
kube-prometheus
https://github.com/prometheus-operator/kube-prometheus
Kube-prometheus
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
[root@UR-20210425NAMA ~]# kubectl -n kubesphere-monitoring-system get prometheusrulesNAME AGEcustom-alerting-rule-zpnmw 83dprometheus-k8s-etcd-rules 112dprometheus-k8s-rules 112d[root@UR-20210425NAMA ~]# kubectl -n kubesphere-monitoring-system get podNAME READY STATUS RESTARTS AGEalertmanager-main-0 2/2 Running 0 2d20hkube-state-metrics-7f65879cfd-m6724 3/3 Running 0 21dnode-exporter-7s68q 2/2 Running 0 50mnode-exporter-7tm4p 2/2 Running 0 50mnode-exporter-bk79m 2/2 Running 0 51mnode-exporter-g4vbs 2/2 Running 0 51mnode-exporter-pr7ck 2/2 Running 0 51mnode-exporter-xr2xk 2/2 Running 0 52mnotification-manager-deployment-674dddcbd9-cwwx6 1/1 Running 1 2d20hnotification-manager-deployment-674dddcbd9-h2xb5 1/1 Running 0 26dnotification-manager-operator-7877c6574f-nwtz2 2/2 Running 0 2d20hprometheus-k8s-0 3/3 Running 1 2d20hprometheus-operator-7d7684fc68-chjl2 2/2 Running 1 2d20hthanos-ruler-kubesphere-0 2/2 Running 0 2d20hthanos-ruler-kubesphere-1 2/2 Running 0 21d[root@UR-20210425NAMA ~]#
[root@UR-20210425NAMA ~]# kubectl -n kubesphere-monitoring-system exec -it prometheus-k8s-0 -- /bin/sh
Defaulting container name to prometheus.
Use 'kubectl describe pod/prometheus-k8s-0 -n kubesphere-monitoring-system' to see all of the containers in this pod.
/prometheus # ls /etc/prometheus/rules/
prometheus-k8s-rulefiles-0
/prometheus # ls /etc/prometheus/rules/prometheus-k8s-rulefiles-0/
kubesphere-monitoring-system-prometheus-k8s-etcd-rules.yaml
kubesphere-monitoring-system-prometheus-k8s-rules.yaml
/prometheus #
[root@UR-20210425NAMA ~]# kubectl -n kubesphere-monitoring-system describe pod prometheus-k8s-0
Name: prometheus-k8s-0
Namespace: kubesphere-monitoring-system
Priority: 0
Node: ur-scm-worker02/192.168.13.182
Start Time: Tue, 07 Sep 2021 13:39:28 +0800
Labels: app=prometheus
controller-revision-hash=prometheus-k8s-566575c454
prometheus=k8s
statefulset.kubernetes.io/pod-name=prometheus-k8s-0
Annotations: cni.projectcalico.org/podIP: 172.27.60.11/32
cni.projectcalico.org/podIPs: 172.27.60.11/32
Status: Running
IP: 172.27.60.11
IPs:
IP: 172.27.60.11
Controlled By: StatefulSet/prometheus-k8s
Containers:
prometheus:
Container ID: docker://b9b25b8cf42c91ab9b2360ba63e7d8da30c0e832048c712714b93af050715894
Image: prom/prometheus:v2.26.0
Image ID: docker-pullable://prom/prometheus@sha256:3e6f1ebc047ec30971c92e86aa3b879b07d39327a7744cce8aa0b1076d4c94d6
Port: 9090/TCP
Host Port: 0/TCP
Args:
--web.console.templates=/etc/prometheus/consoles
--web.console.libraries=/etc/prometheus/console_libraries
--config.file=/etc/prometheus/config_out/prometheus.env.yaml
--storage.tsdb.path=/prometheus
--storage.tsdb.retention.time=7d
--web.enable-lifecycle
--storage.tsdb.no-lockfile
--query.max-concurrency=1000
--web.route-prefix=/
State: Running
Started: Tue, 07 Sep 2021 13:42:23 +0800
Last State: Terminated
Reason: Error
Message: level=error ts=2021-09-07T05:41:07.065Z caller=main.go:347 msg="Error loading config (--config.file=/etc/prometheus/config_out/prometheus.env.yaml)" err="open /etc/prometheus/config_out/prometheus.env.yaml: no such file or directory"
Exit Code: 2
Started: Tue, 07 Sep 2021 13:41:06 +0800
Finished: Tue, 07 Sep 2021 13:41:07 +0800
Ready: True
Restart Count: 1
Limits:
cpu: 4
memory: 16Gi
Requests:
cpu: 200m
memory: 400Mi
Liveness: http-get http://:web/-/healthy delay=0s timeout=3s period=5s #success=1 #failure=6
Readiness: http-get http://:web/-/ready delay=0s timeout=3s period=5s #success=1 #failure=120
Environment: <none>
Mounts:
/etc/prometheus/certs from tls-assets (ro)
/etc/prometheus/config_out from config-out (ro)
/etc/prometheus/rules/prometheus-k8s-rulefiles-0 from prometheus-k8s-rulefiles-0 (rw)
/etc/prometheus/secrets/kube-etcd-client-certs from secret-kube-etcd-client-certs (ro)
/prometheus from prometheus-k8s-db (rw,path="prometheus-db")
/var/run/secrets/kubernetes.io/serviceaccount from prometheus-k8s-token-5vnrl (ro)
prometheus-config-reloader:
Container ID: docker://27aeae94772492fbfa9484369ab7ffcaf04daa4d3826f068787a75f03d73ad63
Image: kubesphere/prometheus-config-reloader:v0.42.1
Image ID: docker-pullable://kubesphere/prometheus-config-reloader@sha256:f7604544fa941b35f93b92a2f1dca56777d3050b7810dd572c49d84ef269bf66
Port: <none>
Host Port: <none>
Command:
/bin/prometheus-config-reloader
Args:
--log-format=logfmt
--reload-url=http://localhost:9090/-/reload
--config-file=/etc/prometheus/config/prometheus.yaml.gz
--config-envsubst-file=/etc/prometheus/config_out/prometheus.env.yaml
State: Running
Started: Tue, 07 Sep 2021 13:42:16 +0800
Ready: True
Restart Count: 0
Limits:
memory: 25Mi
Requests:
memory: 25Mi
Environment:
POD_NAME: prometheus-k8s-0 (v1:metadata.name)
Mounts:
/etc/prometheus/config from config (rw)
/etc/prometheus/config_out from config-out (rw)
/var/run/secrets/kubernetes.io/serviceaccount from prometheus-k8s-token-5vnrl (ro)
rules-configmap-reloader:
Container ID: docker://7f6c71e1a9e699e141b3d8f029b882e1e7b48424323e7944d8afcbc671671877
Image: jimmidyson/configmap-reload:v0.3.0
Image ID: docker-pullable://jimmidyson/configmap-reload@sha256:1ec6625fda2f541d4df87514c8a48e52a563fbb744e857c5d9b41a75c9139413
Port: <none>
Host Port: <none>
Args:
--webhook-url=http://localhost:9090/-/reload
--volume-dir=/etc/prometheus/rules/prometheus-k8s-rulefiles-0
State: Running
Started: Tue, 07 Sep 2021 13:42:20 +0800
Ready: True
Restart Count: 0
Limits:
memory: 25Mi
Requests:
memory: 25Mi
Environment: <none>
Mounts:
/etc/prometheus/rules/prometheus-k8s-rulefiles-0 from prometheus-k8s-rulefiles-0 (rw)
/var/run/secrets/kubernetes.io/serviceaccount from prometheus-k8s-token-5vnrl (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
prometheus-k8s-db:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: prometheus-k8s-db-prometheus-k8s-0
ReadOnly: false
config:
Type: Secret (a volume populated by a Secret)
SecretName: prometheus-k8s
Optional: false
tls-assets:
Type: Secret (a volume populated by a Secret)
SecretName: prometheus-k8s-tls-assets
Optional: false
config-out:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
prometheus-k8s-rulefiles-0:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: prometheus-k8s-rulefiles-0
Optional: false
secret-kube-etcd-client-certs:
Type: Secret (a volume populated by a Secret)
SecretName: kube-etcd-client-certs
Optional: false
prometheus-k8s-token-5vnrl:
Type: Secret (a volume populated by a Secret)
SecretName: prometheus-k8s-token-5vnrl
Optional: false
QoS Class: Burstable
Node-Selectors: kubernetes.io/os=linux
Tolerations: dedicated=monitoring:NoSchedule
node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events: <none>
[root@UR-20210425NAMA ~]#
[root@UR-20210425NAMA ~]# kubectl -n kubesphere-monitoring-system describe prometheusrule prometheus-k8s-rules
Name: prometheus-k8s-rules
Namespace: kubesphere-monitoring-system
Labels: prometheus=k8s
role=alert-rules
Annotations: API Version: monitoring.coreos.com/v1
Kind: PrometheusRule
Metadata:
Creation Timestamp: 2021-05-20T10:27:44Z
Generation: 4
Managed Fields:
API Version: monitoring.coreos.com/v1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.:
f:kubectl.kubernetes.io/last-applied-configuration:
f:labels:
.:
f:prometheus:
f:role:
f:spec:
.:
f:groups:
Manager: kubectl
Operation: Update
Time: 2021-06-18T14:56:06Z
Resource Version: 60039787
Self Link: /apis/monitoring.coreos.com/v1/namespaces/kubesphere-monitoring-system/prometheusrules/prometheus-k8s-rules
UID: 880b60b1-e3f5-4b20-990c-ac807472b428
Spec:
Groups:
Name: kube-apiserver.rules
Rules:
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[1d]))
-
(
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[1d])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[1d])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[1d]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1d]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1d]))
Labels:
Verb: read
Record: apiserver_request:burnrate1d
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[1h]))
-
(
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[1h])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[1h])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[1h]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1h]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1h]))
Labels:
Verb: read
Record: apiserver_request:burnrate1h
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[2h]))
-
(
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[2h])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[2h])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[2h]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[2h]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[2h]))
Labels:
Verb: read
Record: apiserver_request:burnrate2h
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[30m]))
-
(
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30m])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[30m])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[30m]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[30m]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[30m]))
Labels:
Verb: read
Record: apiserver_request:burnrate30m
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[3d]))
-
(
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[3d])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[3d])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[3d]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[3d]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[3d]))
Labels:
Verb: read
Record: apiserver_request:burnrate3d
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[5m]))
-
(
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[5m])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[5m])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[5m]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[5m]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m]))
Labels:
Verb: read
Record: apiserver_request:burnrate5m
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[6h]))
-
(
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[6h])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[6h])) +
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[6h]))
)
)
+
# errors
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[6h]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[6h]))
Labels:
Verb: read
Record: apiserver_request:burnrate6h
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1d]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[1d]))
)
+
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1d]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1d]))
Labels:
Verb: write
Record: apiserver_request:burnrate1d
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1h]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[1h]))
)
+
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1h]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1h]))
Labels:
Verb: write
Record: apiserver_request:burnrate1h
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[2h]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[2h]))
)
+
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[2h]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[2h]))
Labels:
Verb: write
Record: apiserver_request:burnrate2h
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[30m]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[30m]))
)
+
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[30m]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[30m]))
Labels:
Verb: write
Record: apiserver_request:burnrate30m
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[3d]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[3d]))
)
+
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[3d]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[3d]))
Labels:
Verb: write
Record: apiserver_request:burnrate3d
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[5m]))
)
+
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[5m]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
Labels:
Verb: write
Record: apiserver_request:burnrate5m
Expr: (
(
# too slow
sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[6h]))
-
sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[6h]))
)
+
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[6h]))
)
/
sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[6h]))
Labels:
Verb: write
Record: apiserver_request:burnrate6h
Expr: sum by (code,resource) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m]))
Labels:
Verb: read
Record: code_resource:apiserver_request_total:rate5m
Expr: sum by (code,resource) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
Labels:
Verb: write
Record: code_resource:apiserver_request_total:rate5m
Expr: histogram_quantile(0.99, sum by (le, resource) (rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET"}[5m]))) > 0
Labels:
Quantile: 0.99
Verb: read
Record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
Expr: histogram_quantile(0.99, sum by (le, resource) (rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))) > 0
Labels:
Quantile: 0.99
Verb: write
Record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
Expr: sum(rate(apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
/
sum(rate(apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
Record: cluster:apiserver_request_duration_seconds:mean5m
Expr: histogram_quantile(0.99, sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod))
Labels:
Quantile: 0.99
Record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
Expr: histogram_quantile(0.9, sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod))
Labels:
Quantile: 0.9
Record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
Expr: histogram_quantile(0.5, sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod))
Labels:
Quantile: 0.5
Record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile
Interval: 3m
Name: kube-apiserver-availability.rules
Rules:
Expr: 1 - (
(
# write too slow
sum(increase(apiserver_request_duration_seconds_count{verb=~"POST|PUT|PATCH|DELETE"}[30d]))
-
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"POST|PUT|PATCH|DELETE",le="1"}[30d]))
) +
(
# read too slow
sum(increase(apiserver_request_duration_seconds_count{verb=~"LIST|GET"}[30d]))
-
(
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30d])) +
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope="namespace",le="0.5"}[30d])) +
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope="cluster",le="5"}[30d]))
)
) +
# errors
sum(code:apiserver_request_total:increase30d{code=~"5.."} or vector(0))
)
/
sum(code:apiserver_request_total:increase30d)
Labels:
Verb: all
Record: apiserver_request:availability30d
Expr: 1 - (
sum(increase(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[30d]))
-
(
# too slow
sum(increase(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30d])) +
sum(increase(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[30d])) +
sum(increase(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[30d]))
)
+
# errors
sum(code:apiserver_request_total:increase30d{verb="read",code=~"5.."} or vector(0))
)
/
sum(code:apiserver_request_total:increase30d{verb="read"})
Labels:
Verb: read
Record: apiserver_request:availability30d
Expr: 1 - (
(
# too slow
sum(increase(apiserver_request_duration_seconds_count{verb=~"POST|PUT|PATCH|DELETE"}[30d]))
-
sum(increase(apiserver_request_duration_seconds_bucket{verb=~"POST|PUT|PATCH|DELETE",le="1"}[30d]))
)
+
# errors
sum(code:apiserver_request_total:increase30d{verb="write",code=~"5.."} or vector(0))
)
/
sum(code:apiserver_request_total:increase30d{verb="write"})
Labels:
Verb: write
Record: apiserver_request:availability30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"2.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"2.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"2.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"2.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"2.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"2.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"3.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"3.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"3.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"3.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"3.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"3.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"4.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"4.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"4.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"4.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"4.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"4.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"5.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"5.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"5.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"5.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"5.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"5.."}[30d]))
Record: code_verb:apiserver_request_total:increase30d
Expr: sum by (code) (code_verb:apiserver_request_total:increase30d{verb=~"LIST|GET"})
Labels:
Verb: read
Record: code:apiserver_request_total:increase30d
Expr: sum by (code) (code_verb:apiserver_request_total:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
Labels:
Verb: write
Record: code:apiserver_request_total:increase30d
Name: kubelet.rules
Rules:
Expr: histogram_quantile(0.99, sum(rate(kubelet_pleg_relist_duration_seconds_bucket[5m])) by (instance, le) * on(instance) group_left(node) kubelet_node_name{job="kubelet"})
Labels:
Quantile: 0.99
Record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
Expr: histogram_quantile(0.9, sum(rate(kubelet_pleg_relist_duration_seconds_bucket[5m])) by (instance, le) * on(instance) group_left(node) kubelet_node_name{job="kubelet"})
Labels:
Quantile: 0.9
Record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
Expr: histogram_quantile(0.5, sum(rate(kubelet_pleg_relist_duration_seconds_bucket[5m])) by (instance, le) * on(instance) group_left(node) kubelet_node_name{job="kubelet"})
Labels:
Quantile: 0.5
Record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
Name: k8s.rules
Rules:
Expr: sum((container_cpu_usage_seconds_total{job="kubelet", image!="", container!=""} * on(namespace) group_left(workspace) kube_namespace_labels{job="kube-state-metrics"} - container_cpu_usage_seconds_total{job="kubelet", image!="", container!=""} offset 90s * on(namespace) group_left(workspace) kube_namespace_labels{job="kube-state-metrics"}) / 90) by (namespace, workspace)
or on(namespace, workspace) max by(namespace, workspace) (kube_namespace_labels * 0)
Record: namespace:container_cpu_usage_seconds_total:sum_rate
Expr: sum(container_memory_usage_bytes{job="kubelet", image!="", container!=""} * on(namespace) group_left(workspace) kube_namespace_labels{job="kube-state-metrics"}) by (namespace, workspace)
or on(namespace, workspace) max by(namespace, workspace) (kube_namespace_labels * 0)
Record: namespace:container_memory_usage_bytes:sum
Expr: sum(container_memory_working_set_bytes{job="kubelet", image!="", container!=""} * on(namespace) group_left(workspace) kube_namespace_labels{job="kube-state-metrics"}) by (namespace, workspace)
or on(namespace, workspace) max by(namespace, workspace) (kube_namespace_labels * 0)
Record: namespace:container_memory_usage_bytes_wo_cache:sum
Expr: sum by (namespace, label_name) (
sum(kube_pod_container_resource_requests_memory_bytes{job="kube-state-metrics"} * on (endpoint, instance, job, namespace, pod, service) group_left(phase) (kube_pod_status_phase{phase=~"Pending|Running"} == 1)) by (namespace, pod)
* on (namespace, pod)
group_left(label_name) kube_pod_labels{job="kube-state-metrics"}
)
Record: namespace:kube_pod_container_resource_requests_memory_bytes:sum
Expr: sum by (namespace, label_name) (
sum(kube_pod_container_resource_requests_cpu_cores{job="kube-state-metrics"} * on (endpoint, instance, job, namespace, pod, service) group_left(phase) (kube_pod_status_phase{phase=~"Pending|Running"} == 1)) by (namespace, pod)
* on (namespace, pod)
group_left(label_name) kube_pod_labels{job="kube-state-metrics"}
)
Record: namespace:kube_pod_container_resource_requests_cpu_cores:sum
Name: node.rules
Rules:
Expr: sum (node_cpu_seconds_total{job="node-exporter", mode=~"user|nice|system|iowait|irq|softirq"}) by (cpu, instance, job, namespace, pod)
Record: node_cpu_used_seconds_total
Expr: max(kube_pod_info{job="kube-state-metrics"} * on(node) group_left(role) kube_node_role{job="kube-state-metrics", role="master"} or on(pod, namespace) kube_pod_info{job="kube-state-metrics"}) by (node, namespace, host_ip, role, pod)
Record: node_namespace_pod:kube_pod_info:
Expr: count by (node, host_ip, role) (sum by (node, cpu, host_ip, role) (
node_cpu_seconds_total{job="node-exporter"}
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
))
Record: node:node_num_cpu:sum
Expr: avg(irate(node_cpu_used_seconds_total{job="node-exporter"}[5m]))
Record: :node_cpu_utilisation:avg1m
Expr: avg by (node, host_ip, role) (
irate(node_cpu_used_seconds_total{job="node-exporter"}[5m])
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:)
Record: node:node_cpu_utilisation:avg1m
Expr: 1 -
sum(node_memory_MemFree_bytes{job="node-exporter"} + node_memory_Cached_bytes{job="node-exporter"} + node_memory_Buffers_bytes{job="node-exporter"} + node_memory_SReclaimable_bytes{job="node-exporter"})
/
sum(node_memory_MemTotal_bytes{job="node-exporter"})
Record: :node_memory_utilisation:
Expr: sum by (node, host_ip, role) (
(node_memory_MemFree_bytes{job="node-exporter"} + node_memory_Cached_bytes{job="node-exporter"} + node_memory_Buffers_bytes{job="node-exporter"} + node_memory_SReclaimable_bytes{job="node-exporter"})
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:node_memory_bytes_available:sum
Expr: sum by (node, host_ip, role) (
node_memory_MemTotal_bytes{job="node-exporter"}
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:node_memory_bytes_total:sum
Expr: 1 - (node:node_memory_bytes_available:sum / node:node_memory_bytes_total:sum)
Record: node:node_memory_utilisation:
Expr: sum by (node, host_ip, role) (
irate(node_disk_reads_completed_total{job="node-exporter"}[5m])
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:data_volume_iops_reads:sum
Expr: sum by (node, host_ip, role) (
irate(node_disk_writes_completed_total{job="node-exporter"}[5m])
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:data_volume_iops_writes:sum
Expr: sum by (node, host_ip, role) (
irate(node_disk_read_bytes_total{job="node-exporter"}[5m])
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:data_volume_throughput_bytes_read:sum
Expr: sum by (node, host_ip, role) (
irate(node_disk_written_bytes_total{job="node-exporter"}[5m])
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:data_volume_throughput_bytes_written:sum
Expr: sum(irate(node_network_receive_bytes_total{job="node-exporter",device!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)"}[5m])) +
sum(irate(node_network_transmit_bytes_total{job="node-exporter",device!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)"}[5m]))
Record: :node_net_utilisation:sum_irate
Expr: sum by (node, host_ip, role) (
(irate(node_network_receive_bytes_total{job="node-exporter",device!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)"}[5m]) +
irate(node_network_transmit_bytes_total{job="node-exporter",device!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)"}[5m]))
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:node_net_utilisation:sum_irate
Expr: sum by (node, host_ip, role) (
irate(node_network_transmit_bytes_total{job="node-exporter",device!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)"}[5m])
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:node_net_bytes_transmitted:sum_irate
Expr: sum by (node, host_ip, role) (
irate(node_network_receive_bytes_total{job="node-exporter",device!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)"}[5m])
* on (namespace, pod) group_left(node, host_ip, role)
node_namespace_pod:kube_pod_info:
)
Record: node:node_net_bytes_received:sum_irate
Expr: sum by(node, host_ip, role) (sum(max(node_filesystem_files{device=~"/dev/.*", device!~"/dev/loop\\d+", job="node-exporter"}) by (device, pod, namespace)) by (pod, namespace) * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:)
Record: node:node_inodes_total:
Expr: sum by(node, host_ip, role) (sum(max(node_filesystem_files_free{device=~"/dev/.*", device!~"/dev/loop\\d+", job="node-exporter"}) by (device, pod, namespace)) by (pod, namespace) * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:)
Record: node:node_inodes_free:
Expr: sum by (node, host_ip, role) (node_load1{job="node-exporter"} * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:) / node:node_num_cpu:sum
Record: node:load1:ratio
Expr: sum by (node, host_ip, role) (node_load5{job="node-exporter"} * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:) / node:node_num_cpu:sum
Record: node:load5:ratio
Expr: sum by (node, host_ip, role) (node_load15{job="node-exporter"} * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:) / node:node_num_cpu:sum
Record: node:load15:ratio
Expr: sum by (node, host_ip, role) ((kube_pod_status_scheduled{job="kube-state-metrics", condition="true"} > 0) * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:)
Record: node:pod_count:sum
Expr: (sum(kube_node_status_capacity_pods{job="kube-state-metrics"}) by (node) * on(node) group_left(host_ip, role) max by(node, host_ip, role) (node_namespace_pod:kube_pod_info:{node!="",host_ip!=""}))
Record: node:pod_capacity:sum
Expr: node:pod_running:count / node:pod_capacity:sum
Record: node:pod_utilization:ratio
Expr: count(node_namespace_pod:kube_pod_info: unless on (pod, namespace) (kube_pod_status_phase{job="kube-state-metrics", phase=~"Failed|Pending|Unknown|Succeeded"} > 0)) by (node, host_ip, role)
Record: node:pod_running:count
Expr: count(node_namespace_pod:kube_pod_info: unless on (pod, namespace) (kube_pod_status_phase{job="kube-state-metrics", phase=~"Failed|Pending|Unknown|Running"} > 0)) by (node, host_ip, role)
Record: node:pod_succeeded:count
Expr: count(node_namespace_pod:kube_pod_info:{node!="",host_ip!=""} unless on (pod, namespace) (kube_pod_status_phase{job="kube-state-metrics", phase="Succeeded"}>0) unless on (pod, namespace) ((kube_pod_status_ready{job="kube-state-metrics", condition="true"}>0) and on (pod, namespace) (kube_pod_status_phase{job="kube-state-metrics", phase="Running"}>0)) unless on (pod, namespace) kube_pod_container_status_waiting_reason{job="kube-state-metrics", reason="ContainerCreating"}>0) by (node, host_ip, role)
Record: node:pod_abnormal:count
Expr: node:pod_abnormal:count / count(node_namespace_pod:kube_pod_info:{node!="",host_ip!=""} unless on (pod, namespace) kube_pod_status_phase{job="kube-state-metrics", phase="Succeeded"}>0) by (node, host_ip, role)
Record: node:pod_abnormal:ratio
Expr: sum(max(node_filesystem_avail_bytes{device=~"/dev/.*", device!~"/dev/loop\\d+", job="node-exporter"} * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:) by (device, node, host_ip, role)) by (node, host_ip, role)
Record: node:disk_space_available:
Expr: 1- sum(max(node_filesystem_avail_bytes{device=~"/dev/.*", device!~"/dev/loop\\d+", job="node-exporter"} * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:) by (device, node, host_ip, role)) by (node, host_ip, role) / sum(max(node_filesystem_size_bytes{device=~"/dev/.*", device!~"/dev/loop\\d+", job="node-exporter"} * on (namespace, pod) group_left(node, host_ip, role) node_namespace_pod:kube_pod_info:) by (device, node, host_ip, role)) by (node, host_ip, role)
Record: node:disk_space_utilization:ratio
Expr: (1 - (node:node_inodes_free: / node:node_inodes_total:))
Record: node:disk_inode_utilization:ratio
Name: cluster.rules
Rules:
Expr: count(kube_pod_info{job="kube-state-metrics"} unless on (pod, namespace) (kube_pod_status_phase{job="kube-state-metrics", phase="Succeeded"}>0) unless on (pod, namespace) ((kube_pod_status_ready{job="kube-state-metrics", condition="true"}>0) and on (pod, namespace) (kube_pod_status_phase{job="kube-state-metrics", phase="Running"}>0)) unless on (pod, namespace) kube_pod_container_status_waiting_reason{job="kube-state-metrics", reason="ContainerCreating"}>0)
Record: cluster:pod_abnormal:sum
Expr: sum((kube_pod_status_scheduled{job="kube-state-metrics", condition="true"} > 0) * on (namespace, pod) group_left(node) (sum by (node, namespace, pod) (kube_pod_info)))
Record: cluster:pod:sum
Expr: cluster:pod_abnormal:sum / sum(kube_pod_status_phase{job="kube-state-metrics", phase!="Succeeded"})
Record: cluster:pod_abnormal:ratio
Expr: count(kube_pod_info{job="kube-state-metrics"} and on (pod, namespace) (kube_pod_status_phase{job="kube-state-metrics", phase="Running"}>0))
Record: cluster:pod_running:count
Expr: cluster:pod_running:count / sum(kube_node_status_capacity_pods)
Record: cluster:pod_utilization:ratio
Expr: 1 - sum(max(node_filesystem_avail_bytes{device=~"/dev/.*", device!~"/dev/loop\\d+", job="node-exporter"}) by (device, instance)) / sum(max(node_filesystem_size_bytes{device=~"/dev/.*", device!~"/dev/loop\\d+", job="node-exporter"}) by (device, instance))
Record: cluster:disk_utilization:ratio
Expr: 1 - sum(node:node_inodes_free:) / sum(node:node_inodes_total:)
Record: cluster:disk_inode_utilization:ratio
Expr: sum(kube_node_status_condition{job="kube-state-metrics", condition="Ready", status=~"unknown|false"})
Record: cluster:node_offline:sum
Expr: sum(kube_node_status_condition{job="kube-state-metrics", condition="Ready", status=~"unknown|false"}) / sum(kube_node_status_condition{job="kube-state-metrics", condition="Ready"})
Record: cluster:node_offline:ratio
Name: namespace.rules
Rules:
Expr: (count(kube_pod_info{job="kube-state-metrics", node!=""}) by (namespace) - sum(kube_pod_status_phase{job="kube-state-metrics", phase="Succeeded"}) by (namespace) - sum(kube_pod_status_ready{job="kube-state-metrics", condition="true"} * on (pod, namespace) kube_pod_status_phase{job="kube-state-metrics", phase="Running"}) by (namespace) - sum(kube_pod_container_status_waiting_reason{job="kube-state-metrics", reason="ContainerCreating"}) by (namespace)) * on (namespace) group_left(workspace)(kube_namespace_labels{job="kube-state-metrics"})
Record: namespace:pod_abnormal:count
Expr: namespace:pod_abnormal:count / (sum(kube_pod_status_phase{job="kube-state-metrics", phase!="Succeeded", namespace!=""}) by (namespace) * on (namespace) group_left(workspace)(kube_namespace_labels{job="kube-state-metrics"}))
Record: namespace:pod_abnormal:ratio
Expr: max(kube_resourcequota{job="kube-state-metrics", type="used"}) by (resource, namespace) / min(kube_resourcequota{job="kube-state-metrics", type="hard"}) by (resource, namespace) * on (namespace) group_left(workspace) (kube_namespace_labels{job="kube-state-metrics"})
Record: namespace:resourcequota_used:ratio
Expr: sum (label_replace(label_join(sum(irate(container_cpu_usage_seconds_total{job="kubelet", pod!="", image!=""}[5m])) by (namespace, pod) * on (pod, namespace) group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind", "Deployment", "owner_kind", "ReplicaSet"), "owner_kind", "Pod", "owner_kind", "<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"), "workload",":","owner_kind","owner_name"), "workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, owner_kind)
Record: namespace:workload_cpu_usage:sum
Expr: sum (label_replace(label_join(sum(container_memory_usage_bytes{job="kubelet", pod!="", image!=""}) by (namespace, pod) * on (pod, namespace) group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind", "Deployment", "owner_kind", "ReplicaSet"), "owner_kind", "Pod", "owner_kind", "<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"), "workload",":","owner_kind","owner_name"), "workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, owner_kind)
Record: namespace:workload_memory_usage:sum
Expr: sum (label_replace(label_join(sum(container_memory_working_set_bytes{job="kubelet", pod!="", image!=""}) by (namespace, pod) * on (pod, namespace) group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind", "Deployment", "owner_kind", "ReplicaSet"), "owner_kind", "Pod", "owner_kind", "<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"), "workload",":","owner_kind","owner_name"), "workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, owner_kind)
Record: namespace:workload_memory_usage_wo_cache:sum
Expr: sum (label_replace(label_join(sum(irate(container_network_transmit_bytes_total{pod!="", interface!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)", job="kubelet"}[5m])) by (namespace, pod) * on (pod, namespace) group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind", "Deployment", "owner_kind", "ReplicaSet"), "owner_kind", "Pod", "owner_kind", "<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"), "workload",":","owner_kind","owner_name"), "workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, owner_kind)
Record: namespace:workload_net_bytes_transmitted:sum_irate
Expr: sum (label_replace(label_join(sum(container_network_transmit_bytes_total{pod!="", interface!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)", job="kubelet"}) by (namespace, pod) * on (pod, namespace) group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind", "Deployment", "owner_kind", "ReplicaSet"), "owner_kind", "Pod", "owner_kind", "<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"), "workload",":","owner_kind","owner_name"), "workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, owner_kind)
Record: namespace:workload_net_bytes_transmitted:sum
Expr: sum (label_replace(label_join(sum(irate(container_network_receive_bytes_total{pod!="", interface!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)", job="kubelet"}[5m])) by (namespace, pod) * on (pod, namespace) group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind", "Deployment", "owner_kind", "ReplicaSet"), "owner_kind", "Pod", "owner_kind", "<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"), "workload",":","owner_kind","owner_name"), "workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, owner_kind)
Record: namespace:workload_net_bytes_received:sum_irate
Expr: sum (label_replace(label_join(sum(container_network_receive_bytes_total{pod!="", interface!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)", job="kubelet"}) by (namespace, pod) * on (pod, namespace) group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind", "Deployment", "owner_kind", "ReplicaSet"), "owner_kind", "Pod", "owner_kind", "<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"), "workload",":","owner_kind","owner_name"), "workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, owner_kind)
Record: namespace:workload_net_bytes_received:sum
Expr: label_replace(label_replace(sum(kube_deployment_status_replicas_unavailable{job="kube-state-metrics"}) by (deployment, namespace) / sum(kube_deployment_spec_replicas{job="kube-state-metrics"}) by (deployment, namespace) * on (namespace) group_left(workspace)(kube_namespace_labels{job="kube-state-metrics"}), "workload","Deployment:$1", "deployment", "(.*)"), "owner_kind","Deployment", "", "")
Record: namespace:deployment_unavailable_replicas:ratio
Expr: label_replace(label_replace(sum(kube_daemonset_status_number_unavailable{job="kube-state-metrics"}) by (daemonset, namespace) / sum(kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"}) by (daemonset, namespace) * on (namespace) group_left(workspace)(kube_namespace_labels{job="kube-state-metrics"}) , "workload","DaemonSet:$1", "daemonset", "(.*)"), "owner_kind","DaemonSet", "", "")
Record: namespace:daemonset_unavailable_replicas:ratio
Expr: label_replace(label_replace((1 - sum(kube_statefulset_status_replicas_current{job="kube-state-metrics"}) by (statefulset, namespace) / sum(kube_statefulset_replicas{job="kube-state-metrics"}) by (statefulset, namespace)) * on (namespace) group_left(workspace)(kube_namespace_labels{job="kube-state-metrics"}) , "workload","StatefulSet:$1", "statefulset", "(.*)"), "owner_kind","StatefulSet", "", "")
Record: namespace:statefulset_unavailable_replicas:ratio
Expr: sum(kube_pod_container_resource_requests * on (pod, namespace)group_left(owner_kind,owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind","Deployment","owner_kind","ReplicaSet"),"owner_kind","Pod","owner_kind","<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)")) by (namespace, owner_kind, pod, resource)* on(namespace) group_left(workspace)kube_namespace_labels{job="kube-state-metrics"}
Record: namespace:kube_pod_resource_request:sum
Expr: sum(label_replace(label_join(kube_pod_container_resource_requests * on (pod, namespace)group_left(owner_kind,owner_name)label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind","Deployment","owner_kind","ReplicaSet"),"owner_kind","Pod","owner_kind","<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"),"workload",":","owner_kind","owner_name"),"workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, resource)* on(namespace) group_left(workspace) kube_namespace_labels{job="kube-state-metrics"}
Record: namespace:kube_workload_resource_request:sum
Expr: sum(label_replace(label_join(kube_pod_spec_volumes_persistentvolumeclaims_info * on (pod, namespace)group_left(owner_kind,owner_name)label_replace(label_join(label_replace(label_replace(kube_pod_owner{job="kube-state-metrics"},"owner_kind","Deployment","owner_kind","ReplicaSet"),"owner_kind","Pod","owner_kind","<none>"),"tmp",":","owner_name","pod"),"owner_name","$1","tmp","<none>:(.*)"),"workload",":","owner_kind","owner_name"),"workload","$1","workload","(Deployment:.+)-(.+)")) by (namespace, workload, pod, persistentvolumeclaim)* on(namespace, pod) group_left(node) kube_pod_info{job="kube-state-metrics"}* on (node, persistentvolumeclaim) group_left kubelet_volume_stats_capacity_bytes* on(namespace) group_left(workspace) kube_namespace_labels{job="kube-state-metrics"}
Record: namespace:pvc_bytes_total:sum
Name: apiserver.rules
Rules:
Expr: sum(up{job="apiserver"} == 1)
Record: apiserver:up:sum
Expr: sum(irate(apiserver_request_total{job="apiserver"}[5m]))
Record: apiserver:apiserver_request_total:sum_irate
Expr: sum(irate(apiserver_request_total{job="apiserver"}[5m])) by (verb)
Record: apiserver:apiserver_request_total:sum_verb_irate
Expr: sum(irate(apiserver_request_duration_seconds_sum{job="apiserver",subresource!="log", verb!~"LIST|WATCH|WATCHLIST|PROXY|CONNECT"}[5m])) / sum(irate(apiserver_request_duration_seconds_count{job="apiserver", subresource!="log",verb!~"LIST|WATCH|WATCHLIST|PROXY|CONNECT"}[5m]))
Record: apiserver:apiserver_request_duration:avg
Expr: sum(irate(apiserver_request_duration_seconds_sum{job="apiserver",subresource!="log", verb!~"LIST|WATCH|WATCHLIST|PROXY|CONNECT"}[5m])) by (verb) / sum(irate(apiserver_request_duration_seconds_count{job="apiserver", subresource!="log",verb!~"LIST|WATCH|WATCHLIST|PROXY|CONNECT"}[5m])) by (verb)
Record: apiserver:apiserver_request_duration:avg_by_verb
Name: scheduler.rules
Rules:
Expr: sum(up{job="kube-scheduler"} == 1)
Record: scheduler:up:sum
Expr: sum(scheduler_schedule_attempts_total{job="kube-scheduler"}) by (result)
Record: scheduler:scheduler_schedule_attempts:sum
Expr: sum(rate(scheduler_schedule_attempts_total{job="kube-scheduler"}[5m])) by (result)
Record: scheduler:scheduler_schedule_attempts:sum_rate
Expr: (sum(rate(scheduler_e2e_scheduling_duration_seconds_sum{job="kube-scheduler"}[1h])) / sum(rate(scheduler_e2e_scheduling_duration_seconds_count{job="kube-scheduler"}[1h])))
Record: scheduler:scheduler_e2e_scheduling_duration:avg
Name: scheduler_histogram.rules
Rules:
Expr: histogram_quantile(0.99, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[1h])) by (le) )
Labels:
Quantile: 0.99
Record: scheduler:scheduler_e2e_scheduling_duration:histogram_quantile
Expr: histogram_quantile(0.9, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[1h])) by (le) )
Labels:
Quantile: 0.9
Record: scheduler:scheduler_e2e_scheduling_duration:histogram_quantile
Expr: histogram_quantile(0.5, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[1h])) by (le) )
Labels:
Quantile: 0.5
Record: scheduler:scheduler_e2e_scheduling_duration:histogram_quantile
Name: controller_manager.rules
Rules:
Expr: sum(up{job="kube-controller-manager"} == 1)
Record: controller_manager:up:sum
Name: coredns.rules
Rules:
Expr: sum(up{job="coredns"} == 1)
Record: coredns:up:sum
Name: prometheus.rules
Rules:
Expr: sum(up{job="prometheus-k8s",namespace="kubesphere-monitoring-system"} == 1)
Record: prometheus:up:sum
Expr: sum(rate(prometheus_tsdb_head_samples_appended_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"} [5m])) by (job, pod)
Record: prometheus:prometheus_tsdb_head_samples_appended:sum_rate
Name: kube-state-metrics
Rules:
Alert: KubeStateMetricsListErrors
Annotations:
Message: kube-state-metrics is experiencing errors at an elevated rate in list operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubestatemetricslisterrors
Expr: (sum(rate(kube_state_metrics_list_total{job="kube-state-metrics",result="error"}[5m]))
/
sum(rate(kube_state_metrics_list_total{job="kube-state-metrics"}[5m])))
> 0.01
For: 15m
Labels:
Severity: critical
Alert: KubeStateMetricsWatchErrors
Annotations:
Message: kube-state-metrics is experiencing errors at an elevated rate in watch operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubestatemetricswatcherrors
Expr: (sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics",result="error"}[5m]))
/
sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics"}[5m])))
> 0.01
For: 15m
Labels:
Severity: critical
Name: node-exporter
Rules:
Alert: NodeFilesystemSpaceFillingUp
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left and is filling up.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemspacefillingup
Summary: Filesystem is predicted to run out of space within the next 24 hours.
Expr: (
node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 40
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: warning
Alert: NodeFilesystemSpaceFillingUp
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left and is filling up fast.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemspacefillingup
Summary: Filesystem is predicted to run out of space within the next 4 hours.
Expr: (
node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 15
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!=""}[6h], 4*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: critical
Alert: NodeFilesystemAlmostOutOfSpace
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemalmostoutofspace
Summary: Filesystem has less than 5% space left.
Expr: (
node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 5
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: warning
Alert: NodeFilesystemAlmostOutOfSpace
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemalmostoutofspace
Summary: Filesystem has less than 3% space left.
Expr: (
node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 3
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: critical
Alert: NodeFilesystemFilesFillingUp
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left and is filling up.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemfilesfillingup
Summary: Filesystem is predicted to run out of inodes within the next 24 hours.
Expr: (
node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 40
and
predict_linear(node_filesystem_files_free{job="node-exporter",fstype!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: warning
Alert: NodeFilesystemFilesFillingUp
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left and is filling up fast.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemfilesfillingup
Summary: Filesystem is predicted to run out of inodes within the next 4 hours.
Expr: (
node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 20
and
predict_linear(node_filesystem_files_free{job="node-exporter",fstype!=""}[6h], 4*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: critical
Alert: NodeFilesystemAlmostOutOfFiles
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemalmostoutoffiles
Summary: Filesystem has less than 5% inodes left.
Expr: (
node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 5
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: warning
Alert: NodeFilesystemAlmostOutOfFiles
Annotations:
Description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemalmostoutoffiles
Summary: Filesystem has less than 3% inodes left.
Expr: (
node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 3
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
For: 1h
Labels:
Severity: critical
Alert: NodeNetworkReceiveErrs
Annotations:
Description: {{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf "%.0f" $value }} receive errors in the last two minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodenetworkreceiveerrs
Summary: Network interface is reporting many receive errors.
Expr: increase(node_network_receive_errs_total[2m]) > 10
For: 1h
Labels:
Severity: warning
Alert: NodeNetworkTransmitErrs
Annotations:
Description: {{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf "%.0f" $value }} transmit errors in the last two minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodenetworktransmiterrs
Summary: Network interface is reporting many transmit errors.
Expr: increase(node_network_transmit_errs_total[2m]) > 10
For: 1h
Labels:
Severity: warning
Alert: NodeHighNumberConntrackEntriesUsed
Annotations:
Description: {{ $value | humanizePercentage }} of conntrack entries are used.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodehighnumberconntrackentriesused
Summary: Number of conntrack are getting close to the limit.
Expr: (node_nf_conntrack_entries / node_nf_conntrack_entries_limit) > 0.75
Labels:
Severity: warning
Alert: NodeClockSkewDetected
Annotations:
Message: Clock on {{ $labels.instance }} is out of sync by more than 300s. Ensure NTP is configured correctly on this host.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodeclockskewdetected
Summary: Clock skew detected.
Expr: (
node_timex_offset_seconds > 0.05
and
deriv(node_timex_offset_seconds[5m]) >= 0
)
or
(
node_timex_offset_seconds < -0.05
and
deriv(node_timex_offset_seconds[5m]) <= 0
)
For: 10m
Labels:
Severity: warning
Name: kubernetes-apps
Rules:
Alert: KubePodCrashLooping
Annotations:
Message: Pod {{ $labels.namespace }}/{{ $labels.pod }} ({{ $labels.container }}) is restarting {{ printf "%.2f" $value }} times / 5 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepodcrashlooping
Expr: rate(kube_pod_container_status_restarts_total{job="kube-state-metrics"}[15m]) * 60 * 5 > 0
For: 15m
Labels:
Severity: warning
Alert: KubePodNotReady
Annotations:
Message: Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a non-ready state for longer than 15 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepodnotready
Expr: sum by (namespace, pod) (max by(namespace, pod) (kube_pod_status_phase{job="kube-state-metrics", phase=~"Pending|Unknown"}) * on(namespace, pod) group_left(owner_kind) max by(namespace, pod, owner_kind) (kube_pod_owner{owner_kind!="Job"})) > 0
For: 15m
Labels:
Severity: warning
Alert: KubeDeploymentGenerationMismatch
Annotations:
Message: Deployment generation for {{ $labels.namespace }}/{{ $labels.deployment }} does not match, this indicates that the Deployment has failed but has not been rolled back.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubedeploymentgenerationmismatch
Expr: kube_deployment_status_observed_generation{job="kube-state-metrics"}
!=
kube_deployment_metadata_generation{job="kube-state-metrics"}
For: 15m
Labels:
Severity: warning
Alert: KubeDeploymentReplicasMismatch
Annotations:
Message: Deployment {{ $labels.namespace }}/{{ $labels.deployment }} has not matched the expected number of replicas for longer than 15 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubedeploymentreplicasmismatch
Expr: (
kube_deployment_spec_replicas{job="kube-state-metrics"}
!=
kube_deployment_status_replicas_available{job="kube-state-metrics"}
) and (
changes(kube_deployment_status_replicas_updated{job="kube-state-metrics"}[5m])
==
0
)
For: 15m
Labels:
Severity: warning
Alert: KubeStatefulSetReplicasMismatch
Annotations:
Message: StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} has not matched the expected number of replicas for longer than 15 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubestatefulsetreplicasmismatch
Expr: (
kube_statefulset_status_replicas_ready{job="kube-state-metrics"}
!=
kube_statefulset_status_replicas{job="kube-state-metrics"}
) and (
changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics"}[5m])
==
0
)
For: 15m
Labels:
Severity: warning
Alert: KubeStatefulSetGenerationMismatch
Annotations:
Message: StatefulSet generation for {{ $labels.namespace }}/{{ $labels.statefulset }} does not match, this indicates that the StatefulSet has failed but has not been rolled back.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubestatefulsetgenerationmismatch
Expr: kube_statefulset_status_observed_generation{job="kube-state-metrics"}
!=
kube_statefulset_metadata_generation{job="kube-state-metrics"}
For: 15m
Labels:
Severity: warning
Alert: KubeStatefulSetUpdateNotRolledOut
Annotations:
Message: StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} update has not been rolled out.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubestatefulsetupdatenotrolledout
Expr: max without (revision) (
kube_statefulset_status_current_revision{job="kube-state-metrics"}
unless
kube_statefulset_status_update_revision{job="kube-state-metrics"}
)
*
(
kube_statefulset_replicas{job="kube-state-metrics"}
!=
kube_statefulset_status_replicas_updated{job="kube-state-metrics"}
)
For: 15m
Labels:
Severity: warning
Alert: KubeDaemonSetRolloutStuck
Annotations:
Message: Only {{ $value | humanizePercentage }} of the desired Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are scheduled and ready.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubedaemonsetrolloutstuck
Expr: kube_daemonset_status_number_ready{job="kube-state-metrics"}
/
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} < 1.00
For: 15m
Labels:
Severity: warning
Alert: KubeContainerWaiting
Annotations:
Message: Pod {{ $labels.namespace }}/{{ $labels.pod }} container {{ $labels.container}} has been in waiting state for longer than 1 hour.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubecontainerwaiting
Expr: sum by (namespace, pod, container) (kube_pod_container_status_waiting_reason{job="kube-state-metrics"}) > 0
For: 1h
Labels:
Severity: warning
Alert: KubeDaemonSetNotScheduled
Annotations:
Message: {{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are not scheduled.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubedaemonsetnotscheduled
Expr: kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"}
-
kube_daemonset_status_current_number_scheduled{job="kube-state-metrics"} > 0
For: 10m
Labels:
Severity: warning
Alert: KubeDaemonSetMisScheduled
Annotations:
Message: {{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are running where they are not supposed to run.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubedaemonsetmisscheduled
Expr: kube_daemonset_status_number_misscheduled{job="kube-state-metrics"} > 0
For: 15m
Labels:
Severity: warning
Alert: KubeCronJobRunning
Annotations:
Message: CronJob {{ $labels.namespace }}/{{ $labels.cronjob }} is taking more than 1h to complete.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubecronjobrunning
Expr: time() - kube_cronjob_next_schedule_time{job="kube-state-metrics"} > 3600
For: 1h
Labels:
Severity: warning
Alert: KubeJobCompletion
Annotations:
Message: Job {{ $labels.namespace }}/{{ $labels.job_name }} is taking more than one hour to complete.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubejobcompletion
Expr: kube_job_spec_completions{job="kube-state-metrics"} - kube_job_status_succeeded{job="kube-state-metrics"} > 0
For: 1h
Labels:
Severity: warning
Alert: KubeJobFailed
Annotations:
Message: Job {{ $labels.namespace }}/{{ $labels.job_name }} failed to complete.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubejobfailed
Expr: kube_job_failed{job="kube-state-metrics"} > 0
For: 15m
Labels:
Severity: warning
Alert: KubeHpaReplicasMismatch
Annotations:
Message: HPA {{ $labels.namespace }}/{{ $labels.hpa }} has not matched the desired number of replicas for longer than 15 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubehpareplicasmismatch
Expr: (kube_hpa_status_desired_replicas{job="kube-state-metrics"}
!=
kube_hpa_status_current_replicas{job="kube-state-metrics"})
and
changes(kube_hpa_status_current_replicas[15m]) == 0
For: 15m
Labels:
Severity: warning
Alert: KubeHpaMaxedOut
Annotations:
Message: HPA {{ $labels.namespace }}/{{ $labels.hpa }} has been running at max replicas for longer than 15 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubehpamaxedout
Expr: kube_hpa_status_current_replicas{job="kube-state-metrics"}
==
kube_hpa_spec_max_replicas{job="kube-state-metrics"}
For: 15m
Labels:
Severity: warning
Name: kubernetes-resources
Rules:
Alert: KubeCPUOvercommit
Annotations:
Message: Cluster has overcommitted CPU resource requests for Pods and cannot tolerate node failure.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubecpuovercommit
Expr: sum(namespace:kube_pod_container_resource_requests_cpu_cores:sum{})
/
sum(kube_node_status_allocatable_cpu_cores)
>
(count(kube_node_status_allocatable_cpu_cores)-1) / count(kube_node_status_allocatable_cpu_cores)
For: 5m
Labels:
Severity: warning
Alert: KubeMemoryOvercommit
Annotations:
Message: Cluster has overcommitted memory resource requests for Pods and cannot tolerate node failure.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubememoryovercommit
Expr: sum(namespace:kube_pod_container_resource_requests_memory_bytes:sum{})
/
sum(kube_node_status_allocatable_memory_bytes)
>
(count(kube_node_status_allocatable_memory_bytes)-1)
/
count(kube_node_status_allocatable_memory_bytes)
For: 5m
Labels:
Severity: warning
Alert: KubeCPUQuotaOvercommit
Annotations:
Message: Cluster has overcommitted CPU resource requests for Namespaces.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubecpuquotaovercommit
Expr: sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="cpu"})
/
sum(kube_node_status_allocatable_cpu_cores)
> 1.5
For: 5m
Labels:
Severity: warning
Alert: KubeMemoryQuotaOvercommit
Annotations:
Message: Cluster has overcommitted memory resource requests for Namespaces.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubememoryquotaovercommit
Expr: sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="memory"})
/
sum(kube_node_status_allocatable_memory_bytes{job="node-exporter"})
> 1.5
For: 5m
Labels:
Severity: warning
Alert: KubeQuotaExceeded
Annotations:
Message: Namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage }} of its {{ $labels.resource }} quota.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubequotaexceeded
Expr: kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
> 0.90
For: 15m
Labels:
Severity: warning
Alert: CPUThrottlingHigh
Annotations:
Message: {{ $value | humanizePercentage }} throttling of CPU in namespace {{ $labels.namespace }} for container {{ $labels.container }} in pod {{ $labels.pod }}.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-cputhrottlinghigh
Expr: sum(increase(container_cpu_cfs_throttled_periods_total{container!="", }[5m])) by (container, pod, namespace)
/
sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container, pod, namespace)
> ( 25 / 100 )
For: 15m
Labels:
Severity: warning
Name: kubernetes-storage
Rules:
Alert: KubePersistentVolumeFillingUp
Annotations:
Message: The PersistentVolume claimed by {{ $labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} is only {{ $value | humanizePercentage }} free.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepersistentvolumefillingup
Expr: kubelet_volume_stats_available_bytes{job="kubelet"}
/
kubelet_volume_stats_capacity_bytes{job="kubelet"}
< 0.03
For: 1m
Labels:
Severity: critical
Alert: KubePersistentVolumeFillingUp
Annotations:
Message: Based on recent sampling, the PersistentVolume claimed by {{ $labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} is expected to fill up within four days. Currently {{ $value | humanizePercentage }} is available.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepersistentvolumefillingup
Expr: (
kubelet_volume_stats_available_bytes{job="kubelet"}
/
kubelet_volume_stats_capacity_bytes{job="kubelet"}
) < 0.15
and
predict_linear(kubelet_volume_stats_available_bytes{job="kubelet"}[6h], 4 * 24 * 3600) < 0
For: 1h
Labels:
Severity: warning
Alert: KubePersistentVolumeErrors
Annotations:
Message: The persistent volume {{ $labels.persistentvolume }} has status {{ $labels.phase }}.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubepersistentvolumeerrors
Expr: kube_persistentvolume_status_phase{phase=~"Failed|Pending",job="kube-state-metrics"} > 0
For: 5m
Labels:
Severity: critical
Name: kube-apiserver-slos
Rules:
Alert: KubeAPIErrorBudgetBurn
Annotations:
Message: The API server is burning too much error budget
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeapierrorbudgetburn
Expr: sum(apiserver_request:burnrate1h) > (14.40 * 0.01000)
and
sum(apiserver_request:burnrate5m) > (14.40 * 0.01000)
For: 2m
Labels:
Severity: critical
Alert: KubeAPIErrorBudgetBurn
Annotations:
Message: The API server is burning too much error budget
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeapierrorbudgetburn
Expr: sum(apiserver_request:burnrate6h) > (6.00 * 0.01000)
and
sum(apiserver_request:burnrate30m) > (6.00 * 0.01000)
For: 15m
Labels:
Severity: critical
Alert: KubeAPIErrorBudgetBurn
Annotations:
Message: The API server is burning too much error budget
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeapierrorbudgetburn
Expr: sum(apiserver_request:burnrate1d) > (3.00 * 0.01000)
and
sum(apiserver_request:burnrate2h) > (3.00 * 0.01000)
For: 1h
Labels:
Severity: warning
Alert: KubeAPIErrorBudgetBurn
Annotations:
Message: The API server is burning too much error budget
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeapierrorbudgetburn
Expr: sum(apiserver_request:burnrate3d) > (1.00 * 0.01000)
and
sum(apiserver_request:burnrate6h) > (1.00 * 0.01000)
For: 3h
Labels:
Severity: warning
Name: kubernetes-system-apiserver
Rules:
Alert: KubeAPILatencyHigh
Annotations:
Message: The API server has an abnormal latency of {{ $value }} seconds for {{ $labels.verb }} {{ $labels.resource }}.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeapilatencyhigh
Expr: (
cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"}
>
on (verb) group_left()
(
avg by (verb) (cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"} >= 0)
+
2*stddev by (verb) (cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"} >= 0)
)
) > on (verb) group_left()
1.2 * avg by (verb) (cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"} >= 0)
and on (verb,resource)
cluster_quantile:apiserver_request_duration_seconds:histogram_quantile{job="apiserver",quantile="0.99"}
>
1
For: 5m
Labels:
Severity: warning
Alert: KubeAPIErrorsHigh
Annotations:
Message: API server is returning errors for {{ $value | humanizePercentage }} of requests for {{ $labels.verb }} {{ $labels.resource }} {{ $labels.subresource }}.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeapierrorshigh
Expr: sum(rate(apiserver_request_total{job="apiserver",code=~"5.."}[5m])) by (resource,subresource,verb)
/
sum(rate(apiserver_request_total{job="apiserver"}[5m])) by (resource,subresource,verb) > 0.05
For: 10m
Labels:
Severity: warning
Alert: KubeClientCertificateExpiration
Annotations:
Message: A client certificate used to authenticate to the apiserver is expiring in less than 7.0 days.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeclientcertificateexpiration
Expr: apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and on(job) histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 604800
Labels:
Severity: warning
Alert: KubeClientCertificateExpiration
Annotations:
Message: A client certificate used to authenticate to the apiserver is expiring in less than 24.0 hours.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeclientcertificateexpiration
Expr: apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and on(job) histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 86400
Labels:
Severity: critical
Alert: AggregatedAPIErrors
Annotations:
Message: An aggregated API {{ $labels.name }}/{{ $labels.namespace }} has reported errors. The number of errors have increased for it in the past five minutes. High values indicate that the availability of the service changes too often.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-aggregatedapierrors
Expr: sum by(name, namespace)(increase(aggregator_unavailable_apiservice_count[5m])) > 2
Labels:
Severity: warning
Alert: AggregatedAPIDown
Annotations:
Message: An aggregated API {{ $labels.name }}/{{ $labels.namespace }} is down. It has not been available at least for the past five minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-aggregatedapidown
Expr: sum by(name, namespace)(sum_over_time(aggregator_unavailable_apiservice[5m])) > 0
For: 5m
Labels:
Severity: warning
Alert: KubeAPIDown
Annotations:
Message: KubeAPI has disappeared from Prometheus target discovery.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeapidown
Expr: absent(up{job="apiserver"} == 1)
For: 15m
Labels:
Severity: critical
Name: kubernetes-system-kubelet
Rules:
Alert: KubeNodeNotReady
Annotations:
Message: {{ $labels.node }} has been unready for more than 15 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubenodenotready
Expr: kube_node_status_condition{job="kube-state-metrics",condition="Ready",status="true"} == 0
For: 15m
Labels:
Severity: warning
Alert: KubeNodeUnreachable
Annotations:
Message: {{ $labels.node }} is unreachable and some workloads may be rescheduled.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubenodeunreachable
Expr: kube_node_spec_taint{job="kube-state-metrics",key="node.kubernetes.io/unreachable",effect="NoSchedule"} == 1
For: 2m
Labels:
Severity: warning
Alert: KubeletTooManyPods
Annotations:
Message: Kubelet '{{ $labels.node }}' is running at {{ $value | humanizePercentage }} of its Pod capacity.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubelettoomanypods
Expr: max(max(kubelet_running_pod_count{job="kubelet"}) by(instance) * on(instance) group_left(node) kubelet_node_name{job="kubelet"}) by(node) / max(kube_node_status_capacity_pods{job="kube-state-metrics"} != 1) by(node) > 0.95
For: 15m
Labels:
Severity: warning
Alert: KubeNodeReadinessFlapping
Annotations:
Message: The readiness status of node {{ $labels.node }} has changed {{ $value }} times in the last 15 minutes.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubenodereadinessflapping
Expr: sum(changes(kube_node_status_condition{status="true",condition="Ready"}[15m])) by (node) > 2
For: 15m
Labels:
Severity: warning
Alert: KubeletPlegDurationHigh
Annotations:
Message: The Kubelet Pod Lifecycle Event Generator has a 99th percentile duration of {{ $value }} seconds on node {{ $labels.node }}.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeletplegdurationhigh
Expr: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile{quantile="0.99"} >= 10
For: 5m
Labels:
Severity: warning
Alert: KubeletPodStartUpLatencyHigh
Annotations:
Message: Kubelet Pod startup 99th percentile latency is {{ $value }} seconds on node {{ $labels.node }}.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeletpodstartuplatencyhigh
Expr: histogram_quantile(0.99, sum(rate(kubelet_pod_worker_duration_seconds_bucket{job="kubelet"}[5m])) by (instance, le)) * on(instance) group_left(node) kubelet_node_name{job="kubelet"} > 60
For: 15m
Labels:
Severity: warning
Alert: KubeletDown
Annotations:
Message: Kubelet has disappeared from Prometheus target discovery.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeletdown
Expr: absent(up{job="kubelet"} == 1)
For: 15m
Labels:
Severity: critical
Name: kubernetes-system-scheduler
Rules:
Alert: KubeSchedulerDown
Annotations:
Message: KubeScheduler has disappeared from Prometheus target discovery.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubeschedulerdown
Expr: absent(up{job="kube-scheduler"} == 1)
For: 15m
Labels:
Severity: critical
Name: kubernetes-system-controller-manager
Rules:
Alert: KubeControllerManagerDown
Annotations:
Message: KubeControllerManager has disappeared from Prometheus target discovery.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-kubecontrollermanagerdown
Expr: absent(up{job="kube-controller-manager"} == 1)
For: 15m
Labels:
Severity: critical
Name: prometheus
Rules:
Alert: PrometheusBadConfig
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has failed to reload its configuration.
Summary: Failed Prometheus configuration reload.
Expr: # Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
max_over_time(prometheus_config_last_reload_successful{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m]) == 0
For: 10m
Labels:
Severity: critical
Alert: PrometheusNotificationQueueRunningFull
Annotations:
Description: Alert notification queue of Prometheus {{$labels.namespace}}/{{$labels.pod}} is running full.
Summary: Prometheus alert notification queue predicted to run full in less than 30m.
Expr: # Without min_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
(
predict_linear(prometheus_notifications_queue_length{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m], 60 * 30)
>
min_over_time(prometheus_notifications_queue_capacity{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
)
For: 15m
Labels:
Severity: warning
Alert: PrometheusErrorSendingAlertsToSomeAlertmanagers
Annotations:
Description: {{ printf "%.1f" $value }}% errors while sending alerts from Prometheus {{$labels.namespace}}/{{$labels.pod}} to Alertmanager {{$labels.alertmanager}}.
Summary: Prometheus has encountered more than 1% errors sending alerts to a specific Alertmanager.
Expr: (
rate(prometheus_notifications_errors_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
/
rate(prometheus_notifications_sent_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
)
* 100
> 1
For: 15m
Labels:
Severity: warning
Alert: PrometheusErrorSendingAlertsToAnyAlertmanager
Annotations:
Description: {{ printf "%.1f" $value }}% minimum errors while sending alerts from Prometheus {{$labels.namespace}}/{{$labels.pod}} to any Alertmanager.
Summary: Prometheus encounters more than 3% errors sending alerts to any Alertmanager.
Expr: min without(alertmanager) (
rate(prometheus_notifications_errors_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
/
rate(prometheus_notifications_sent_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
)
* 100
> 3
For: 15m
Labels:
Severity: critical
Alert: PrometheusNotConnectedToAlertmanagers
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is not connected to any Alertmanagers.
Summary: Prometheus is not connected to any Alertmanagers.
Expr: # Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
max_over_time(prometheus_notifications_alertmanagers_discovered{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m]) < 1
For: 10m
Labels:
Severity: warning
Alert: PrometheusTSDBReloadsFailing
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has detected {{$value | humanize}} reload failures over the last 3h.
Summary: Prometheus has issues reloading blocks from disk.
Expr: increase(prometheus_tsdb_reloads_failures_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[3h]) > 0
For: 4h
Labels:
Severity: warning
Alert: PrometheusTSDBCompactionsFailing
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has detected {{$value | humanize}} compaction failures over the last 3h.
Summary: Prometheus has issues compacting blocks.
Expr: increase(prometheus_tsdb_compactions_failed_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[3h]) > 0
For: 4h
Labels:
Severity: warning
Alert: PrometheusNotIngestingSamples
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is not ingesting samples.
Summary: Prometheus is not ingesting samples.
Expr: rate(prometheus_tsdb_head_samples_appended_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m]) <= 0
For: 10m
Labels:
Severity: warning
Alert: PrometheusDuplicateTimestamps
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is dropping {{ printf "%.4g" $value }} samples/s with different values but duplicated timestamp.
Summary: Prometheus is dropping samples with duplicate timestamps.
Expr: rate(prometheus_target_scrapes_sample_duplicate_timestamp_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m]) > 0
For: 10m
Labels:
Severity: warning
Alert: PrometheusOutOfOrderTimestamps
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is dropping {{ printf "%.4g" $value }} samples/s with timestamps arriving out of order.
Summary: Prometheus drops samples with out-of-order timestamps.
Expr: rate(prometheus_target_scrapes_sample_out_of_order_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m]) > 0
For: 10m
Labels:
Severity: warning
Alert: PrometheusRemoteStorageFailures
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} failed to send {{ printf "%.1f" $value }}% of the samples to {{ $labels.remote_name}}:{{ $labels.url }}
Summary: Prometheus fails to send samples to remote storage.
Expr: (
rate(prometheus_remote_storage_failed_samples_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
/
(
rate(prometheus_remote_storage_failed_samples_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
+
rate(prometheus_remote_storage_succeeded_samples_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
)
)
* 100
> 1
For: 15m
Labels:
Severity: critical
Alert: PrometheusRemoteWriteBehind
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} remote write is {{ printf "%.1f" $value }}s behind for {{ $labels.remote_name}}:{{ $labels.url }}.
Summary: Prometheus remote write is behind.
Expr: # Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
(
max_over_time(prometheus_remote_storage_highest_timestamp_in_seconds{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
- on(job, instance) group_right
max_over_time(prometheus_remote_storage_queue_highest_sent_timestamp_seconds{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
)
> 120
For: 15m
Labels:
Severity: critical
Alert: PrometheusRemoteWriteDesiredShards
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} remote write desired shards calculation wants to run {{ $value }} shards for queue {{ $labels.remote_name}}:{{ $labels.url }}, which is more than the max of {{ printf `prometheus_remote_storage_shards_max{instance="%s",job="prometheus-k8s",namespace="kubesphere-monitoring-system"}` $labels.instance | query | first | value }}.
Summary: Prometheus remote write desired shards calculation wants to run more than configured max shards.
Expr: # Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
(
max_over_time(prometheus_remote_storage_shards_desired{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
>
max_over_time(prometheus_remote_storage_shards_max{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m])
)
For: 15m
Labels:
Severity: warning
Alert: PrometheusRuleFailures
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has failed to evaluate {{ printf "%.0f" $value }} rules in the last 5m.
Summary: Prometheus is failing rule evaluations.
Expr: increase(prometheus_rule_evaluation_failures_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m]) > 0
For: 15m
Labels:
Severity: critical
Alert: PrometheusMissingRuleEvaluations
Annotations:
Description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has missed {{ printf "%.0f" $value }} rule group evaluations in the last 5m.
Summary: Prometheus is missing rule evaluations due to slow rule group evaluation.
Expr: increase(prometheus_rule_group_iterations_missed_total{job="prometheus-k8s",namespace="kubesphere-monitoring-system"}[5m]) > 0
For: 15m
Labels:
Severity: warning
Name: alertmanager.rules
Rules:
Alert: AlertmanagerConfigInconsistent
Annotations:
Message: The configuration of the instances of the Alertmanager cluster `{{$labels.service}}` are out of sync.
Expr: count_values("config_hash", alertmanager_config_hash{job="alertmanager-main",namespace="kubesphere-monitoring-system"}) BY (service) / ON(service) GROUP_LEFT() label_replace(max(prometheus_operator_spec_replicas{job="prometheus-operator",namespace="kubesphere-monitoring-system",controller="alertmanager"}) by (name, job, namespace, controller), "service", "alertmanager-$1", "name", "(.*)") != 1
For: 5m
Labels:
Severity: critical
Alert: AlertmanagerFailedReload
Annotations:
Message: Reloading Alertmanager's configuration has failed for {{ $labels.namespace }}/{{ $labels.pod}}.
Expr: alertmanager_config_last_reload_successful{job="alertmanager-main",namespace="kubesphere-monitoring-system"} == 0
For: 10m
Labels:
Severity: warning
Alert: AlertmanagerMembersInconsistent
Annotations:
Message: Alertmanager has not found all other members of the cluster.
Expr: alertmanager_cluster_members{job="alertmanager-main",namespace="kubesphere-monitoring-system"}
!= on (service) GROUP_LEFT()
count by (service) (alertmanager_cluster_members{job="alertmanager-main",namespace="kubesphere-monitoring-system"})
For: 5m
Labels:
Severity: critical
Name: general.rules
Rules:
Alert: TargetDown
Annotations:
Message: {{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are down.
Expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10
For: 10m
Labels:
Severity: warning
Alert: Watchdog
Annotations:
Message: This is an alert meant to ensure that the entire alerting pipeline is functional.
This alert is always firing, therefore it should always be firing in Alertmanager
and always fire against a receiver. There are integrations with various notification
mechanisms that send a notification when this alert is not firing. For example the
"DeadMansSnitch" integration in PagerDuty.
Expr: vector(1)
Labels:
Severity: none
Name: node-network
Rules:
Alert: NodeNetworkInterfaceFlapping
Annotations:
Message: Network interface "{{ $labels.device }}" changing it's up status often on node-exporter {{ $labels.namespace }}/{{ $labels.pod }}"
Expr: changes(node_network_up{job="node-exporter",device!~"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)"}[2m]) > 2
For: 2m
Labels:
Severity: warning
Name: prometheus-operator
Rules:
Alert: PrometheusOperatorReconcileErrors
Annotations:
Message: Errors while reconciling {{ $labels.controller }} in {{ $labels.namespace }} Namespace.
Expr: rate(prometheus_operator_reconcile_errors_total{job="prometheus-operator",namespace="kubesphere-monitoring-system"}[5m]) > 0.1
For: 10m
Labels:
Severity: warning
Alert: PrometheusOperatorNodeLookupErrors
Annotations:
Message: Errors while reconciling Prometheus in {{ $labels.namespace }} Namespace.
Expr: rate(prometheus_operator_node_address_lookup_errors_total{job="prometheus-operator",namespace="kubesphere-monitoring-system"}[5m]) > 0.1
For: 10m
Labels:
Severity: warning
Events: <none>
[root@UR-20210425NAMA ~]#
[root@UR-20210425NAMA ~]# kubectl -n kubesphere-monitoring-system get secret alertmanager-main
NAME TYPE DATA AGE
alertmanager-main Opaque 1 112d
[root@UR-20210425NAMA ~]# kubectl -n kubesphere-monitoring-system get secret alertmanager-main -o yaml
apiVersion: v1
data:
alertmanager.yaml: Imdsb2JhbCI6CiAgInJlc29sdmVfdGltZW91dCI6ICI1bSIKImluaGliaXRfcnVsZXMiOgotICJlcXVhbCI6CiAgLSAibmFtZXNwYWNlIgogIC0gImFsZXJ0bmFtZSIKICAic291cmNlX21hdGNoIjoKICAgICJzZXZlcml0eSI6ICJjcml0aWNhbCIKICAidGFyZ2V0X21hdGNoX3JlIjoKICAgICJzZXZlcml0eSI6ICJ3YXJuaW5nfGluZm8iCi0gImVxdWFsIjoKICAtICJuYW1lc3BhY2UiCiAgLSAiYWxlcnRuYW1lIgogICJzb3VyY2VfbWF0Y2giOgogICAgInNldmVyaXR5IjogIndhcm5pbmciCiAgInRhcmdldF9tYXRjaF9yZSI6CiAgICAic2V2ZXJpdHkiOiAiaW5mbyIKInJlY2VpdmVycyI6Ci0gIm5hbWUiOiAiRGVmYXVsdCIKLSAibmFtZSI6ICJXYXRjaGRvZyIKLSAibmFtZSI6ICJwcm9tZXRoZXVzIgogICJ3ZWJob29rX2NvbmZpZ3MiOgogIC0gInVybCI6ICJodHRwOi8vbm90aWZpY2F0aW9uLW1hbmFnZXItc3ZjLmt1YmVzcGhlcmUtbW9uaXRvcmluZy1zeXN0ZW0uc3ZjOjE5MDkzL2FwaS92Mi9hbGVydHMiCi0gIm5hbWUiOiAiZXZlbnQiCiAgIndlYmhvb2tfY29uZmlncyI6CiAgLSAic2VuZF9yZXNvbHZlZCI6IGZhbHNlCiAgICAidXJsIjogImh0dHA6Ly9ub3RpZmljYXRpb24tbWFuYWdlci1zdmMua3ViZXNwaGVyZS1tb25pdG9yaW5nLXN5c3RlbS5zdmM6MTkwOTMvYXBpL3YyL2FsZXJ0cyIKLSAibmFtZSI6ICJhdWRpdGluZyIKICAid2ViaG9va19jb25maWdzIjoKICAtICJzZW5kX3Jlc29sdmVkIjogZmFsc2UKICAgICJ1cmwiOiAiaHR0cDovL25vdGlmaWNhdGlvbi1tYW5hZ2VyLXN2Yy5rdWJlc3BoZXJlLW1vbml0b3Jpbmctc3lzdGVtLnN2YzoxOTA5My9hcGkvdjIvYWxlcnRzIgoicm91dGUiOgogICJncm91cF9ieSI6CiAgLSAibmFtZXNwYWNlIgogIC0gImFsZXJ0bmFtZSIKICAtICJydWxlX2lkIgogICJncm91cF9pbnRlcnZhbCI6ICI1bSIKICAiZ3JvdXBfd2FpdCI6ICIzMHMiCiAgInJlY2VpdmVyIjogIkRlZmF1bHQiCiAgInJlcGVhdF9pbnRlcnZhbCI6ICIxMmgiCiAgInJvdXRlcyI6CiAgLSAibWF0Y2giOgogICAgICAiYWxlcnRuYW1lIjogIldhdGNoZG9nIgogICAgInJlY2VpdmVyIjogIldhdGNoZG9nIgogIC0gImdyb3VwX2ludGVydmFsIjogIjMwcyIKICAgICJtYXRjaCI6CiAgICAgICJhbGVydHR5cGUiOiAiZXZlbnQiCiAgICAicmVjZWl2ZXIiOiAiZXZlbnQiCiAgLSAiZ3JvdXBfaW50ZXJ2YWwiOiAiMzBzIgogICAgIm1hdGNoIjoKICAgICAgImFsZXJ0dHlwZSI6ICJhdWRpdGluZyIKICAgICJyZWNlaXZlciI6ICJhdWRpdGluZyIKICAtICJtYXRjaF9yZSI6CiAgICAgICJhbGVydHR5cGUiOiAiLioiCiAgICAicmVjZWl2ZXIiOiAicHJvbWV0aGV1cyI=
kind: Secret
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{},"kind":"Secret","metadata":{"annotations":{},"name":"alertmanager-main","namespace":"kubesphere-monitoring-system"},"stringData":{"alertmanager.yaml":"\"global\":\n \"resolve_timeout\": \"5m\"\n\"inhibit_rules\":\n- \"equal\":\n - \"namespace\"\n - \"alertname\"\n \"source_match\":\n \"severity\": \"critical\"\n \"target_match_re\":\n \"severity\": \"warning|info\"\n- \"equal\":\n - \"namespace\"\n - \"alertname\"\n \"source_match\":\n \"severity\": \"warning\"\n \"target_match_re\":\n \"severity\": \"info\"\n\"receivers\":\n- \"name\": \"Default\"\n- \"name\": \"Watchdog\"\n- \"name\": \"prometheus\"\n \"webhook_configs\":\n - \"url\": \"http://notification-manager-svc.kubesphere-monitoring-system.svc:19093/api/v2/alerts\"\n- \"name\": \"event\"\n \"webhook_configs\":\n - \"send_resolved\": false\n \"url\": \"http://notification-manager-svc.kubesphere-monitoring-system.svc:19093/api/v2/alerts\"\n- \"name\": \"auditing\"\n \"webhook_configs\":\n - \"send_resolved\": false\n \"url\": \"http://notification-manager-svc.kubesphere-monitoring-system.svc:19093/api/v2/alerts\"\n\"route\":\n \"group_by\":\n - \"namespace\"\n - \"alertname\"\n - \"rule_id\"\n \"group_interval\": \"5m\"\n \"group_wait\": \"30s\"\n \"receiver\": \"Default\"\n \"repeat_interval\": \"12h\"\n \"routes\":\n - \"match\":\n \"alertname\": \"Watchdog\"\n \"receiver\": \"Watchdog\"\n - \"group_interval\": \"30s\"\n \"match\":\n \"alerttype\": \"event\"\n \"receiver\": \"event\"\n - \"group_interval\": \"30s\"\n \"match\":\n \"alerttype\": \"auditing\"\n \"receiver\": \"auditing\"\n - \"match_re\":\n \"alerttype\": \".*\"\n \"receiver\": \"prometheus\""},"type":"Opaque"}
creationTimestamp: "2021-05-20T10:27:45Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:alertmanager.yaml: {}
f:metadata:
f:annotations:
.: {}
f:kubectl.kubernetes.io/last-applied-configuration: {}
f:type: {}
manager: kubectl
operation: Update
time: "2021-06-18T14:56:08Z"
name: alertmanager-main
namespace: kubesphere-monitoring-system
resourceVersion: "12796905"
selfLink: /api/v1/namespaces/kubesphere-monitoring-system/secrets/alertmanager-main
uid: 0f0f46e1-3e28-4bf3-ae28-8ae6a84a980d
type: Opaque
[root@UR-20210425NAMA ~]# echo 'Imdsb2JhbCI6CiAgInJlc29sdmVfdGltZW91dCI6ICI1bSIKImluaGliaXRfcnVsZXMiOgotICJlcXVhbCI6CiAgLSAibmFtZXNwYWNlIgogIC0gImFsZXJ0bmFtZSIKICAic291cmNlX21hdGNoIjoKICAgICJzZXZlcml0eSI6ICJjcml0aWNhbCIKICAidGFyZ2V0X21hdGNoX3JlIjoKICAgICJzZXZlcml0eSI6ICJ3YXJuaW5nfGluZm8iCi0gImVxdWFsIjoKICAtICJuYW1lc3BhY2UiCiAgLSAiYWxlcnRuYW1lIgogICJzb3VyY2VfbWF0Y2giOgogICAgInNldmVyaXR5IjogIndhcm5pbmciCiAgInRhcmdldF9tYXRjaF9yZSI6CiAgICAic2V2ZXJpdHkiOiAiaW5mbyIKInJlY2VpdmVycyI6Ci0gIm5hbWUiOiAiRGVmYXVsdCIKLSAibmFtZSI6ICJXYXRjaGRvZyIKLSAibmFtZSI6ICJwcm9tZXRoZXVzIgogICJ3ZWJob29rX2NvbmZpZ3MiOgogIC0gInVybCI6ICJodHRwOi8vbm90aWZpY2F0aW9uLW1hbmFnZXItc3ZjLmt1YmVzcGhlcmUtbW9uaXRvcmluZy1zeXN0ZW0uc3ZjOjE5MDkzL2FwaS92Mi9hbGVydHMiCi0gIm5hbWUiOiAiZXZlbnQiCiAgIndlYmhvb2tfY29uZmlncyI6CiAgLSAic2VuZF9yZXNvbHZlZCI6IGZhbHNlCiAgICAidXJsIjogImh0dHA6Ly9ub3RpZmljYXRpb24tbWFuYWdlci1zdmMua3ViZXNwaGVyZS1tb25pdG9yaW5nLXN5c3RlbS5zdmM6MTkwOTMvYXBpL3YyL2FsZXJ0cyIKLSAibmFtZSI6ICJhdWRpdGluZyIKICAid2ViaG9va19jb25maWdzIjoKICAtICJzZW5kX3Jlc29sdmVkIjogZmFsc2UKICAgICJ1cmwiOiAiaHR0cDovL25vdGlmaWNhdGlvbi1tYW5hZ2VyLXN2Yy5rdWJlc3BoZXJlLW1vbml0b3Jpbmctc3lzdGVtLnN2YzoxOTA5My9hcGkvdjIvYWxlcnRzIgoicm91dGUiOgogICJncm91cF9ieSI6CiAgLSAibmFtZXNwYWNlIgogIC0gImFsZXJ0bmFtZSIKICAtICJydWxlX2lkIgogICJncm91cF9pbnRlcnZhbCI6ICI1bSIKICAiZ3JvdXBfd2FpdCI6ICIzMHMiCiAgInJlY2VpdmVyIjogIkRlZmF1bHQiCiAgInJlcGVhdF9pbnRlcnZhbCI6ICIxMmgiCiAgInJvdXRlcyI6CiAgLSAibWF0Y2giOgogICAgICAiYWxlcnRuYW1lIjogIldhdGNoZG9nIgogICAgInJlY2VpdmVyIjogIldhdGNoZG9nIgogIC0gImdyb3VwX2ludGVydmFsIjogIjMwcyIKICAgICJtYXRjaCI6CiAgICAgICJhbGVydHR5cGUiOiAiZXZlbnQiCiAgICAicmVjZWl2ZXIiOiAiZXZlbnQiCiAgLSAiZ3JvdXBfaW50ZXJ2YWwiOiAiMzBzIgogICAgIm1hdGNoIjoKICAgICAgImFsZXJ0dHlwZSI6ICJhdWRpdGluZyIKICAgICJyZWNlaXZlciI6ICJhdWRpdGluZyIKICAtICJtYXRjaF9yZSI6CiAgICAgICJhbGVydHR5cGUiOiAiLioiCiAgICAicmVjZWl2ZXIiOiAicHJvbWV0aGV1cyI=' | base64 -d
"global":
"resolve_timeout": "5m"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "critical"
"target_match_re":
"severity": "warning|info"
- "equal":
- "namespace"
- "alertname"
"source_match":
"severity": "warning"
"target_match_re":
"severity": "info"
"receivers":
- "name": "Default"
- "name": "Watchdog"
- "name": "prometheus"
"webhook_configs":
- "url": "http://notification-manager-svc.kubesphere-monitoring-system.svc:19093/api/v2/alerts"
- "name": "event"
"webhook_configs":
- "send_resolved": false
"url": "http://notification-manager-svc.kubesphere-monitoring-system.svc:19093/api/v2/alerts"
- "name": "auditing"
"webhook_configs":
- "send_resolved": false
"url": "http://notification-manager-svc.kubesphere-monitoring-system.svc:19093/api/v2/alerts"
"route":
"group_by":
- "namespace"
- "alertname"
- "rule_id"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "match":
"alertname": "Watchdog"
"receiver": "Watchdog"
- "group_interval": "30s"
"match":
"alerttype": "event"
"receiver": "event"
- "group_interval": "30s"
"match":
"alerttype": "auditing"
"receiver": "auditing"
- "match_re":
"alerttype": ".*"
"receiver": "prometheus"
[root@UR-20210425NAMA ~]#
告警策略
https://github.com/kubernetes-monitoring/kubernetes-mixin
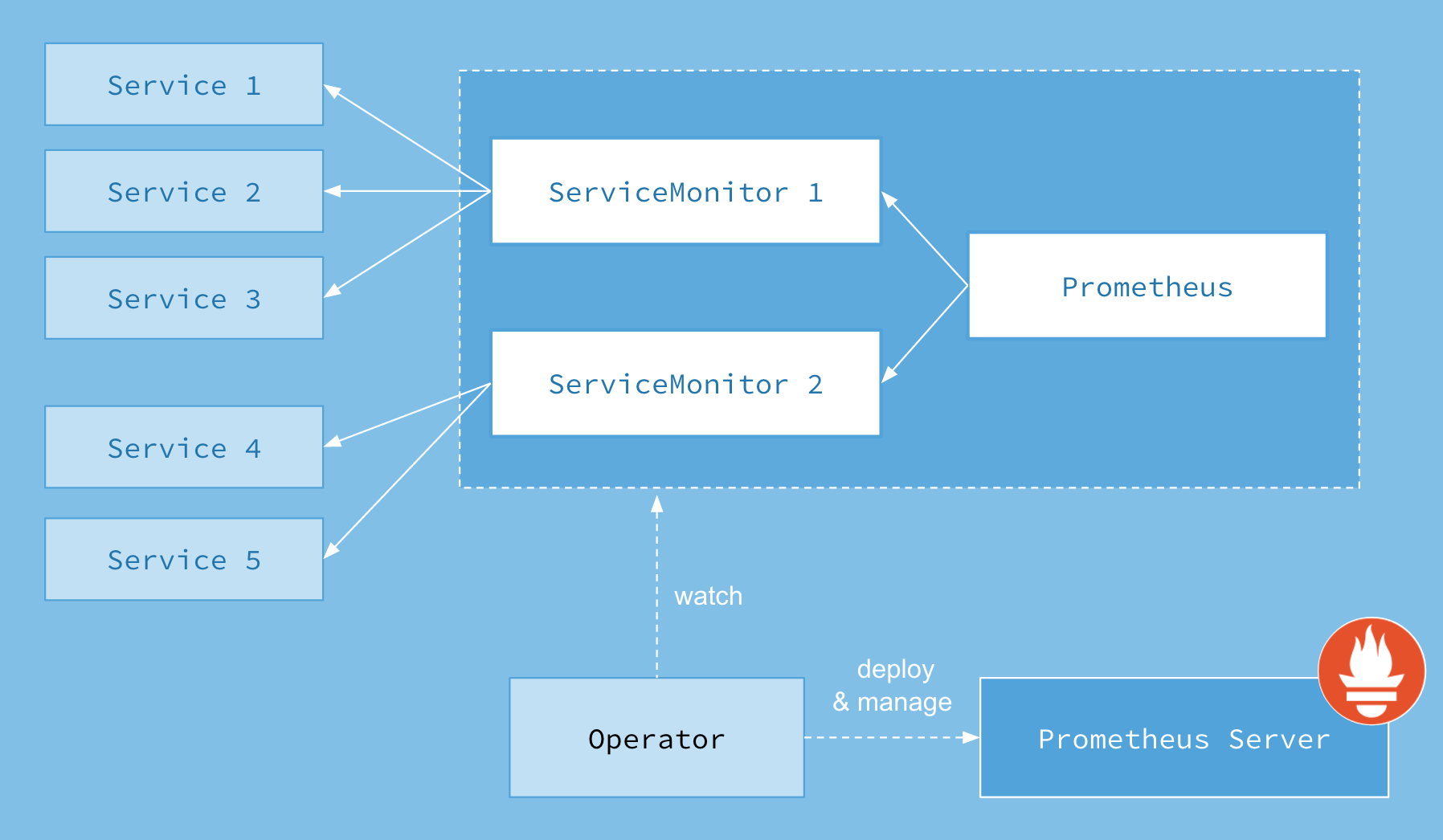
Prometheus 应用监控
https://prometheus.io/docs/instrumenting/exporters/#http
Tomcat
tomcat_exporter
https://github.com/nlighten/tomcat_exporter
jmx_exporter
https://github.com/prometheus/jmx_exporter
nginx
https://github.com/hnlq715/nginx-vts-exporter
https://github.com/vozlt/nginx-module-vts
https://github.com/knyar/nginx-lua-prometheus
apache
https://github.com/Lusitaniae/apache_exporter
java
https://github.com/prometheus/client_java
https://blog.csdn.net/qq_33430322/article/details/89488249#_279
https://www.cnblogs.com/you-men/tag/Prometheus/
Kvass 是一个 Prometheus 横向扩缩容解决方案,他使用Sidecar动态得根据Coordinator分配下来的target列表来为每个Prometheus生成只含特定target的配置文件,从而将采集任务动态调度到各个Prometheus分片。 Coordinator 用于服务发现,target调度和分片扩缩容管理. Thanos (或者其他TSDB) 用来将分片数据汇总成全局数据

若有收获,就点个赞吧
0 人点赞
