work模型之平均消费信息
假设有这一些比较耗时的任务,按照上一次的那种方式,我们要一直等前面的耗时任务完成了之后才能接着处理后面耗时的任务,那要等多久才能处理完?别担心,我们今天的主角—工作队列就可以解决该问题。我们将围绕下面这个索引展开:
- 什么是工作队列
- 代码准备
- 循环分发
- 消息确认
- 公平分发
- 消息持久化
废话少说,直接展开。
一、什么是工作队列
工作队列—用来将耗时的任务分发给多个消费者(工作者),主要解决这样的问题:处理资源密集型任务,并且还要等他完成。有了工作队列,我们就可以将具体的工作放到后面去做,将工作封装为一个消息,发送到队列中,一个工作进程就可以取出消息并完成工作。如果启动了多个工作进程,那么工作就可以在多个进程间共享。
二、代码准备
1、RabbitMQ的工具类
import com.rabbitmq.client.Channel;import com.rabbitmq.client.Connection;import com.rabbitmq.client.ConnectionFactory;import java.io.IOException;import java.util.concurrent.TimeoutException;public class RabbitMQUtils {private static ConnectionFactory factory;static {//1.创建连接mq的连接工厂,工具类中类加载的时候就完成factory = new ConnectionFactory();//2.设置连接mq的主机及其信息//ipfactory.setHost("xx.xxx.xxx.xxx");//端口factory.setPort(5672);//虚拟主机名factory.setVirtualHost("/ems");//用户factory.setUsername("ems");//用户密码factory.setPassword("123456");}//定义提供链接对象的方法public static Connection getConnection(){//3.获取连接对象try {Connection connection = factory.newConnection();return connection;} catch (IOException e) {e.printStackTrace();return null;} catch (TimeoutException e) {e.printStackTrace();return null;}}public static void closeConnectionAndChanel(Channel channel, Connection connection){try{if (channel != null) {channel.close();}if (connection != null){connection.close();}} catch (TimeoutException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
2、生产者
package com.alex.blog.rabbitmq.workquene;import com.alex.blog.util.RabbitMQUtils;import com.rabbitmq.client.Channel;import com.rabbitmq.client.Connection;import java.io.IOException;public class Provider {public static void main(String[] args) throws IOException {//获取连接对象Connection connection = RabbitMQUtils.getConnection();//获取通道Channel channel = connection.createChannel();//通过通道,申明队列channel.queueDeclare("work",true,false,false,null);for (int i = 0;i<10;i++){//生产消息channel.basicPublish("","work",null,("第"+i+"次hello,workquene").getBytes());}//关闭资源RabbitMQUtils.closeConnectionAndChanel(channel,connection);}}
运行一次,查看是否生产了消息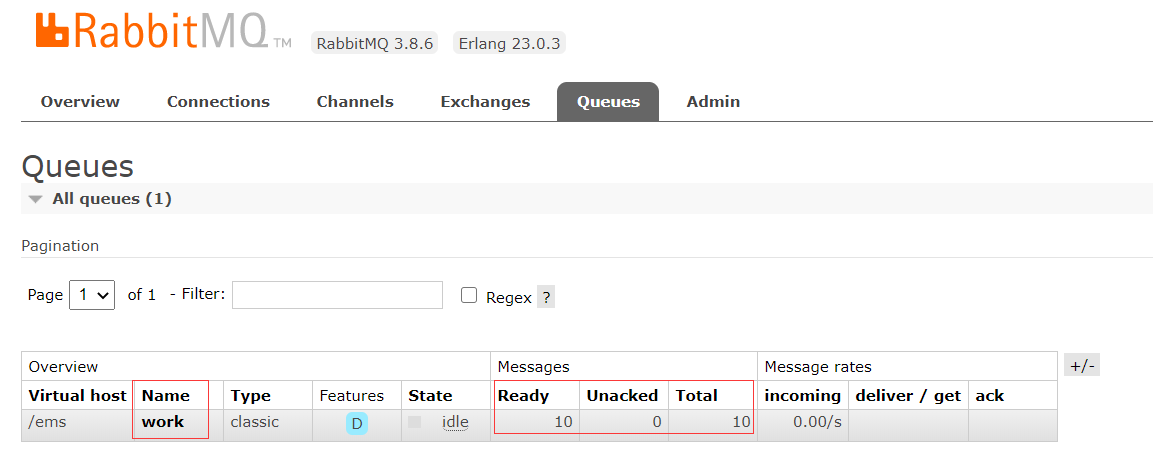
可以看到已经生产了十条消息
3、消费者,因为是workquene模式,所以起码用两个消费者来测试
package com.alex.blog.rabbitmq.workquene;import com.alex.blog.util.RabbitMQUtils;import com.rabbitmq.client.*;import java.io.IOException;public class Customer1 {public static void main(String[] args) throws IOException {//获取连接Connection connection = RabbitMQUtils.getConnection();//获取通道Channel channel = connection.createChannel();//通过通道,申明队列channel.queueDeclare("work",true,false,false,null);channel.basicConsume("work",true,new DefaultConsumer(channel){@Overridepublic void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {System.out.println("消费者1:"+new String(body));}});}}
三、循环分发
将队列删除,然后分别启动我们的消费者1和消费者2,然后去生产消息
消费者1: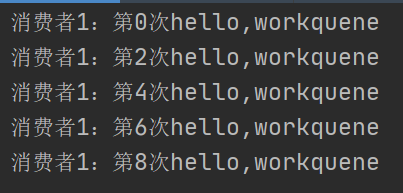
消费者2: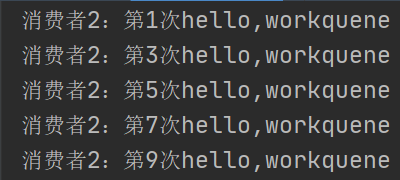
我推测,这里用了轮询去消费,我们新加一个消费者3来确认:
消费者1: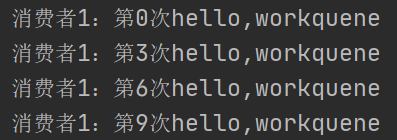
消费者2: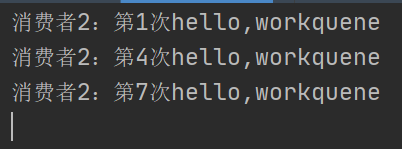
消费者3: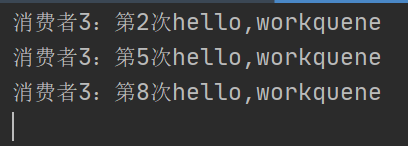
但是官方文档这里解释的是,平均分配,我测试了一下,让消费者1每执行一次sleep2秒,会发现,消费者2、3还是处理原来的那几天,消费者1也是处理那几条,只不过处理的慢一点,此时我们希望执行快的继续去执行,此时就出现了“能者多劳”机制,也就是公平分发:
四、消息确认
在此之前我们先想一个问题,假设消费者1处理的慢,需要两秒处理一个消息,队列现在有10条消息,消费者1要处理4条,消费者1处理了两条突然宕机,剩下的两条会被消费吗?消费了以后会执行吗?
此处我直接说我的测试结果:结果就是,队列的消息分配给消费者后,消费者会向mq说:“我已经消费了”,然后消费者再走内部逻辑,但是宕机后,mq认为消费者已经消费了,但实际情况确实没有消费
此时我们来测试一下,让消费者1每执行一次睡眠2s,然后执行到第二个,kill掉进程,查看管理页面
可以看到,队列中的消息已经全部消费完,然后看后台:
消费者1(执行两条后kill掉):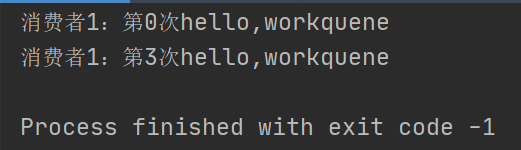
消费者2: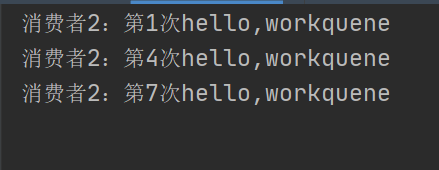
消费者3: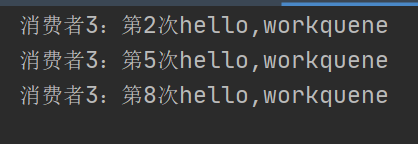
显然我们的消息6、9没有被消费,但是队列里已经消费了,这种叫客户端丢失
为了应对这种情况,RabbitMQ支持消息确认。消费者处理完消息之后,会发送一个确认消息告诉RabbitMQ,消息处理完了,你可以删掉它了。
修改程序中的代码:
channel.basicConsume("work",true,new DefaultConsumer(channel)//改为channel.basicConsume("work",false,new DefaultConsumer(channel)//关闭了自动确认,所以需要手动确认//手动确认:参数1、确认队列中的哪个消息 参数2、false 每次确认一个 true 开启多个消息同时确认channel.basicAck(envelope.getDeliveryTag(),false);
重启消费者1、2、3,继续上面的测试步骤:
此时,我们查看后台:
消费者1: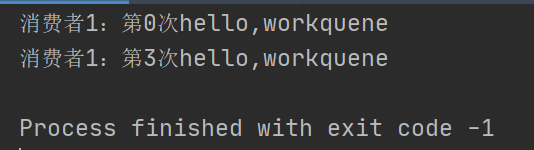
消费者2: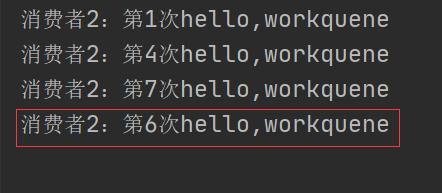
消费者3: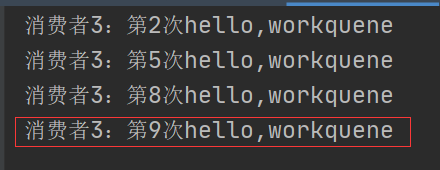
我们可以看到,消费者1应该消费的消息已经被消费者2、3消费了
五、公平分发
按照上面那种循环分发的方式,每个消费者会分到相同数量的任务,这样会有一个问题:假如有一些task非常耗时,之前的任务还没有完成,后面又来了那么多任务,来不及处理,那咋办? 有的消费者忙的不可开交,有的消费者却很快处理完事情然后无所事事浪费资源,那咋整?答案就是:公平分发。 怎么实现呢?
发生上述问题的原因就是RabbitMQ收到消息后就立即分发出去,而没有确认各个工作者未返回确认的消息数量。因此我们可以使用basicQos方法,并将参数prefetchCount设为1,告诉RabbitMQ 我每次值处理一条消息,你要等我处理完了再分给我下一个。这样RabbitMQ就不会轮流分发了,而是寻找空闲的工作者进行分发。
//消费者1、2、3同步修改,同时让消费者1睡眠2s、2睡眠3s、3睡眠4s,可以得知,消费者1消费的快channel.basicQos(1);//每次消费1条消息
测试:
消费者1:
消费者2: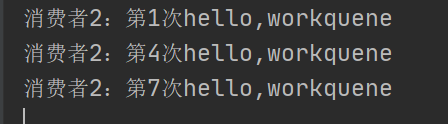
消费者3: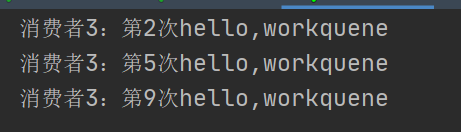
睡眠的时候太少,看的不明显,大家在测试的时候可以调大一点时间
六、消息持久化
上面说到消息确认的时候,提到了工作者被kill的情况。那如果RabbitMQ被stop掉了呢?我们来看下,列出要使用的命令:
systemctl start rabbitmq-server.service //启动rabbitmqrabbitmqctl stop //停止rabbitmq
首先,我们生产十条数据,消费了两三条后重启rabbitmq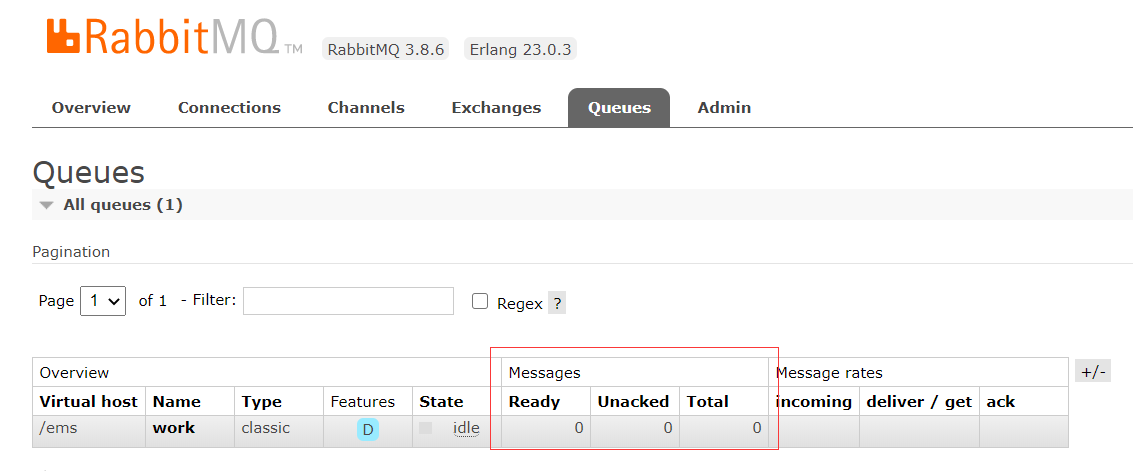
可以看到,消息已经丢失,这种属于服务端丢失:
因此需要将消息进行持久化来应对这种情况。
持久化需要做两件事情:
队列持久化,在声明队列的时候,将第二个参数设为true```java channel.queueDeclare(“work”,false,false,false,null);
//改为true
channel.queueDeclare(“work”,true,false,false,null); ```
消息持久化,在发送消息的时候,将第三个参数设为
java //生产消息 channel.basicPublish("","work",null,("第"+i+"次hello,workquene").getBytes()); //改为 //生产消息 channel.basicPublish("","work",MessageProperties.PERSISTENT_TEXT_PLAIN,("第"+i+"次hello,workquene").getBytes());
然后重复上面测试,我们会看到重新启动后,未被消费的消息继续被消费。

若有收获,就点个赞吧
0 人点赞
