今天接到了新需求,要让设备编号自动生成,因为设备编号可以从000000~999999,一开始的想法是从数据库拿到设备编号的集合,然后手动创建一个000000~999999的集合(耗时不到1秒),然后利用removeAll方法去掉重复的,从手动创建的list中取出第一个返回前端。
但是事与愿违,removeAll方法在数据量大的情况下,效率很低下,模拟一下: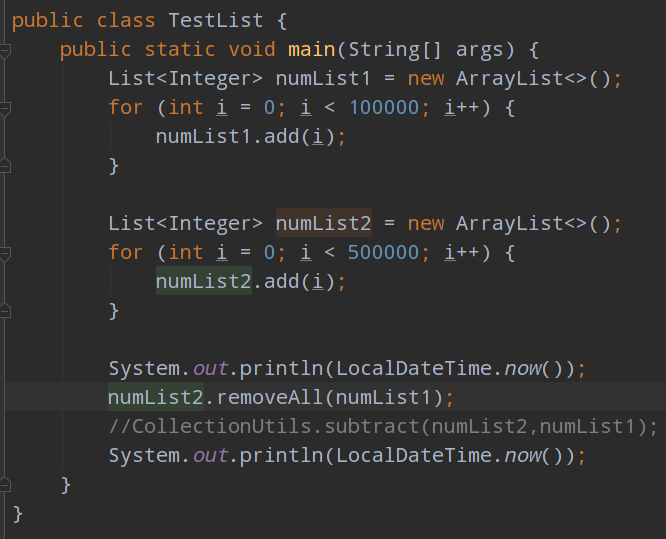
耗时: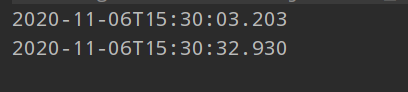
30秒!嗯,果断放弃掉。
然后想的是,直接比较两个list,因为顺序是排好的,用一个for循环进行比较。但是因为两个list长度不同,在比较的时候如果角标大于了短的list的长度,则会越界,还要在循环里做判断,想了一下效率应该也不高。
最后采用了commons-collections包下的CollectionUtils的subtract方法,这个方法是一个取差集的方法: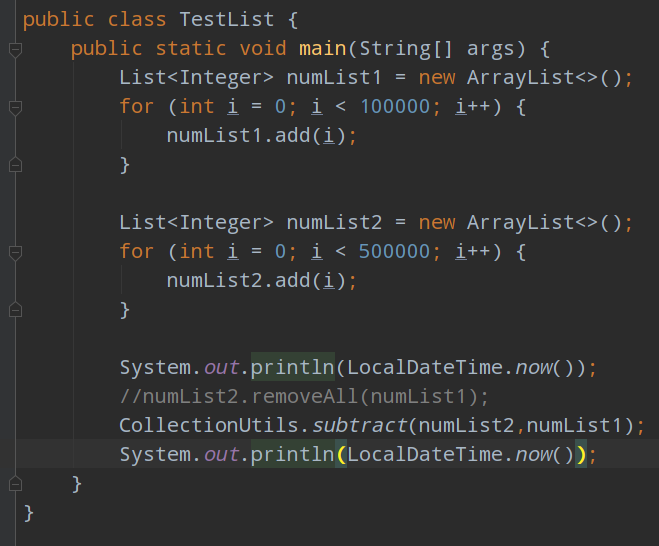
耗时: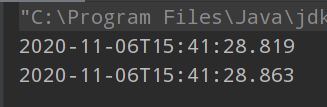
毫秒级别,已经可以了
但是为什么这两个方法会产生如此大的差别?看一下源码会不会有答案。
先看一下removeAll方法的源码,实际是调用的batchRemove: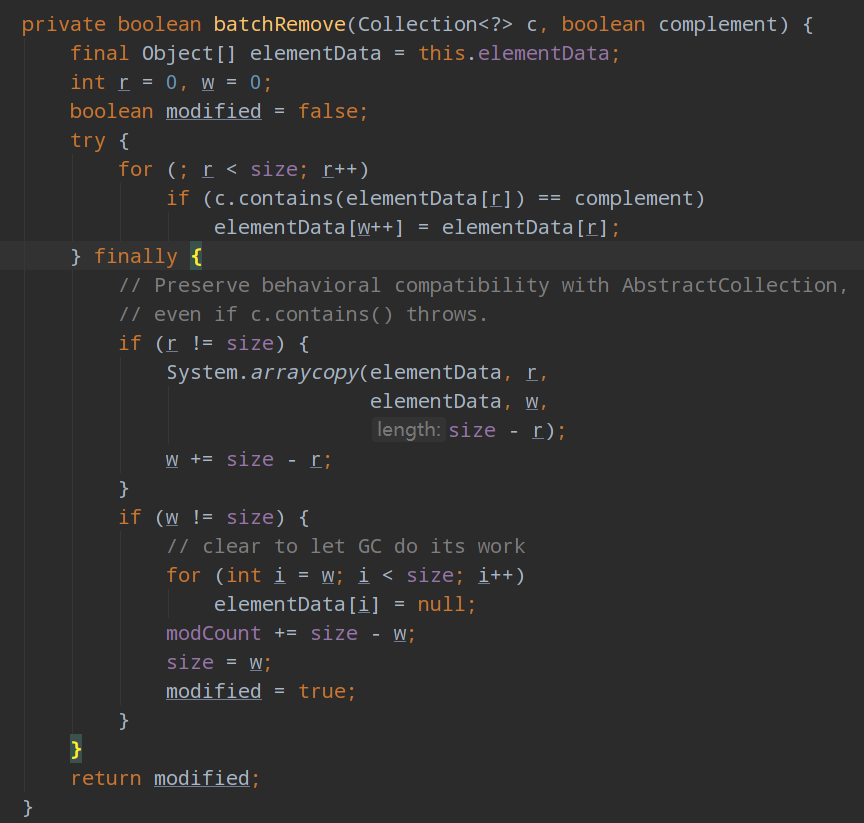
再看一下subtract方法: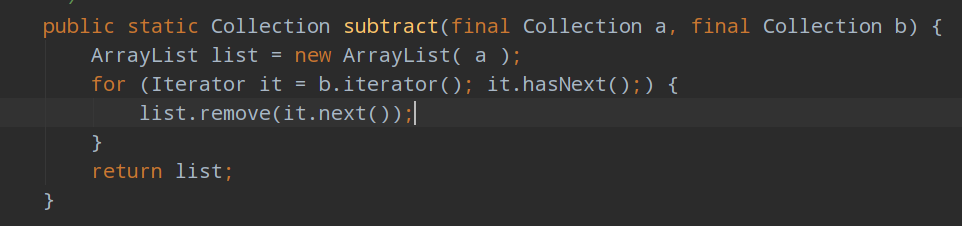
然后我们分析一下:
两个方法都是for循环,一个普通for循环,一个用迭代器循环,两者差不大
关键在于,batchRemove方法中的for循环调用了contains方法,contains方法就是调用indexOf遍历整个集合
,而subtract方法是遍历小集合,然后在大集合直接remove掉。
他们的空间复杂度:
batchRemove:O(n^2)
subtract:O(n)
so,问题就在这里,所以在数据量大求差集的情况下,建议还是使用CollectionUtils的subtract方法。

若有收获,就点个赞吧
0 人点赞
