
1.Spark Streaming
Spark Streaming是Spark核心API的一个扩展,可以实现高吞吐、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂语法的处理。最后还可以将处理结果存储到文件系统。Spark的各个子框架都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话就是,在流数据分成一批一批后,通过一个先进先出的队列,然后Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产效率和消费速率。
2.模拟Spark Streaming
首先我们安装在服务器安装nc(netcat)
yum install -y nc
新建一个Maven项目,导入如下依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.2.1</version></dependency>
新建SparkStreaming.java类
import org.apache.spark.SparkConf;import org.apache.spark.streaming.Durations;import org.apache.spark.streaming.api.java.JavaDStream;import org.apache.spark.streaming.api.java.JavaPairDStream;import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;import org.apache.spark.streaming.api.java.JavaStreamingContext;import scala.Tuple2;import java.util.Arrays;public class SparkStreaming {public static void main(String[] args) throws InterruptedException {// Create a local StreamingContext with two working thread and batch interval of 1 secondSparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));// Create a DStream that will connect to hostname:port, like localhost:9999JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);// Split each line into wordsJavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());// Count each word in each batchJavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);// Print the first ten elements of each RDD generated in this DStream to the consolewordCounts.print();jssc.start(); // Start the computationjssc.awaitTermination(); // Wait for the computation to terminate}}
打包上传到服务器,执行下面命令
spark-submit --class SparkStreaming --master local[2] --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:/usr/local/log4j.xml" /usr/local/spark_streaming-1.0.jar
log4j.xml
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"><log4j:configuration xmlns:log4j='http://jakarta.apache.org/log4j/' ><appender name="FILE" class="org.apache.log4j.DailyRollingFileAppender"><param name="file" value="spark_streaming.log" /><param name="threshold" value="INFO"/><param name="DatePattern" value="yyyyMMdd"/><param name="append" value="true" /><layout class="org.apache.log4j.PatternLayout"><param name="ConversionPattern" value="%d [%t] %-5p %c(%L) - %m%n"/></layout></appender><root>//指出日志级别<priority value ="INFO"/><appender-ref ref="FILE"/></root></log4j:configuration>
然后我们启动nc
nc -lk 9999
然后我们随便输入一个单词,比如abc,然后查看控制台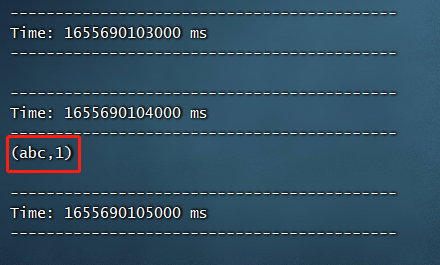
然后再输入abcdef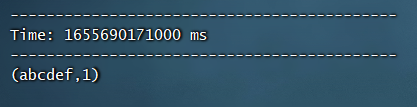
OK,到这里SparkStreaming的基本Demo就已完成,想让spark-submit后台执行只需要在命令前加nohup即可~

若有收获,就点个赞吧
0 人点赞
