
1.RDD
Spark的主要抽象是分布式的元素集合,称为弹性分布式数据集(Resilient DistributedDataset,RDD),它可被分发到集群的各个节点上进行并行操作。RDD可以通过Hadoop InputFormats创建(如HDFS),或者从其他RDD转换而来。RDD提供了一种高度受限的共享内存模型,既RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join、groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是:**转换操作:**(map、filter、groupBy、join等)接收RDD并返回RDD。**行动操作:**(count、collect等)接受RDD但返回非RDD(既输出一个值或结果)
常见的Transformation如下:
此处RDD为{1,2,3,3}
| 函数名 | 功能 | 例子 | 结果 |
|---|---|---|---|
| map() | 对每个元素应用函数 | rdd.map(x => x+1) | {2,3,4,4} |
| flatMap() | 压扁,常用来抽取单词 | rdd.fiatMap(x => x.to(3)) | {1,2,3,2,3,3,3} |
| filter() | 过滤 | rdd.filter(x=> x != 1) | {2,3,3} |
| distinct() | 去重 | rdd.distinct() | {1,2,3} |
Transformation也支持两个RDD的集合操作。例:一个RDD为{1,2,3},另一个RDD包含{3,4,5}
| 函数名 | 功能 | 例子 | 结果 |
|---|---|---|---|
| union() | 并集 | rdd.union(other) | {1,2,3,3,4,5} |
| intersection() | 交集 | rdd.intersection(other) | {3} |
| subtract() | 取存在第一个RDD的元素而不存在于第二个RDD的元素 | rdd.subtract(other) | {1,2} |
| cartesian() | 笛卡尔积 | rdd.cartesian(other) | {(1,3),(1,4),……(3,5)} |
常见的Action如下:
此处RDD为{1,2,3,3}
| 函数名 | 功能 | 例子 | 结果 |
|---|---|---|---|
| collect() | 返回RDD的所有元素 | rdd.collect() | {1,2,3,3} |
| count() | 计数 | rdd.count() | 4 |
| countByValue() | 返回一个map,表示唯一元素出现的个数 | rdd.countByValue() | {(1,1),(2,1),(3,2)} |
| take(num) | 返回几个元素 | rdd.take(2) | {1,2} |
| top(num) | 返回前几个元素 | rdd.top(2) | {3,3} |
| reduce(func) | 合并RDD中的元素 | rdd.reduce((x,y) => x+y) | 9 |
| foreach(func) | 对RDD的每个元素作用函数,什么也不返回 | rdd.foreach(func) | 无 |
2.测试
我们利用spark-shell简单测试几个例子:
1.统计文件行数
首先启动spark命令行界面
spark-shell
然后在命令行输入
var textFile = sc.textFile("file:///usr/local/spark/README.md")
获取RDD,然后运行Action
textFile.count()
结果如图所示:
2.单词数统计
Transformation:
var textFile = sc.textFile("file:///usr/local/spark/README.md")var wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => a + b)
Action:
wordCounts.collect
结果: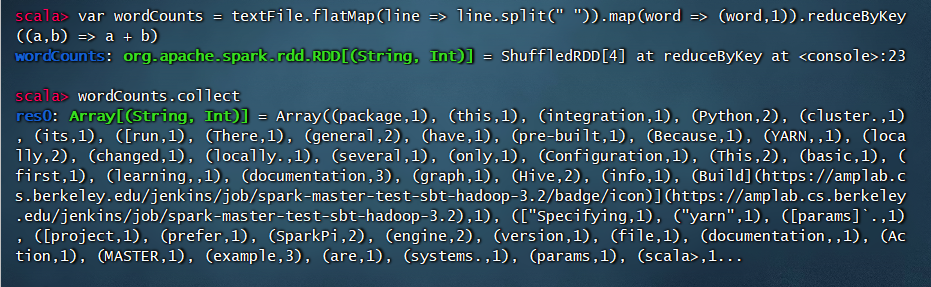

若有收获,就点个赞吧
0 人点赞
