存储模型
- 文件线性切割成块(Block):偏移量offset
- Block散列在各个集群节点
- 单一Block大小一致,文件与文件可以不一致
- Block可以设置副本数,副本数分散在不同节点(副本数不超过节点数)
- 文件上传可以设置副本数和Block大小
- 已上传的文件可以调整Block副本数,大小不可以改变(namenode存的offset)
- 只支持一次上传多次读取,同一时刻只有只有一个写入者
-
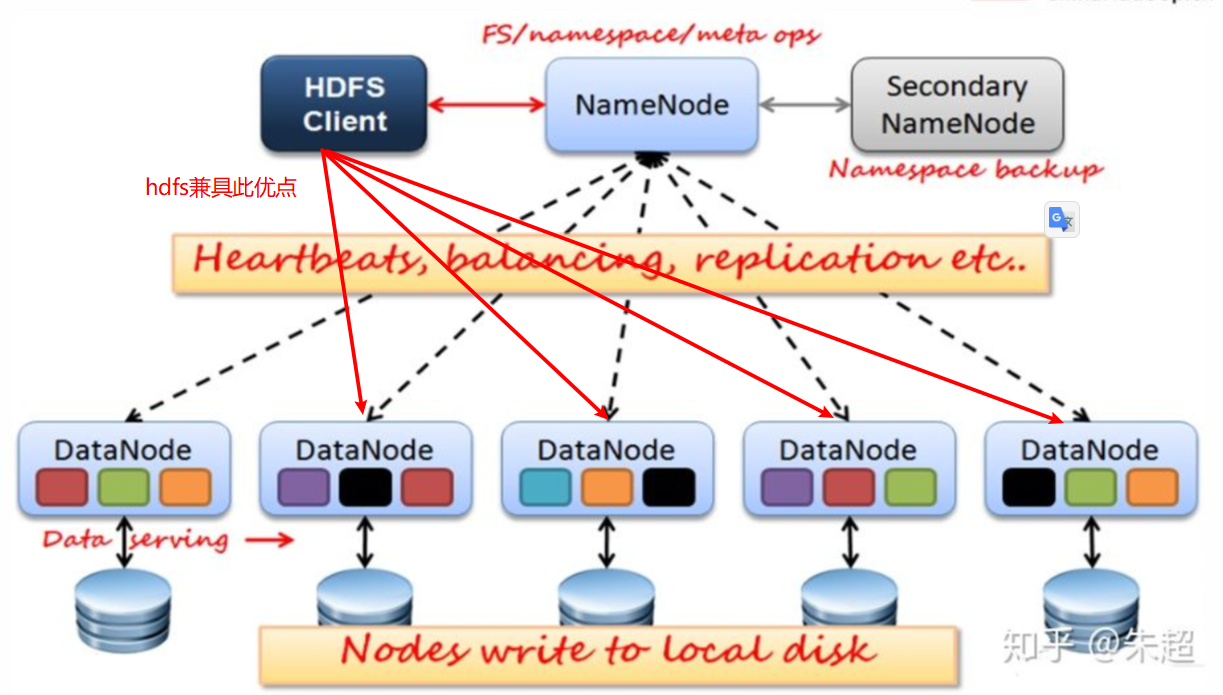
架构模型
文件元数据包括:MetaData+文件数据
- (主)NameNode节点包保存文件元数据:单节点 posix虚拟目录树
- (从)DataNode 节点保存Block块数据:多节点(主从架构)
- DataNode与NameNode保持心跳提交Block块列表
- HDFSClient与NameNode交互元数据信息
- HDFSClient与DataNode交互Block数据(负载均衡,后期hdsf读数据会具体讲解)
HDFS架构图
HDFS设计思想
Block块大小:128M(寻址时间10ms,即查找到目标block的时间为10ms,寻址时间为传输时间的1%时,则为最佳状态。因此,传输时间=10ms/0.01=1000ms=1s block大小=1s*100MB/s(普遍速度)=100MB)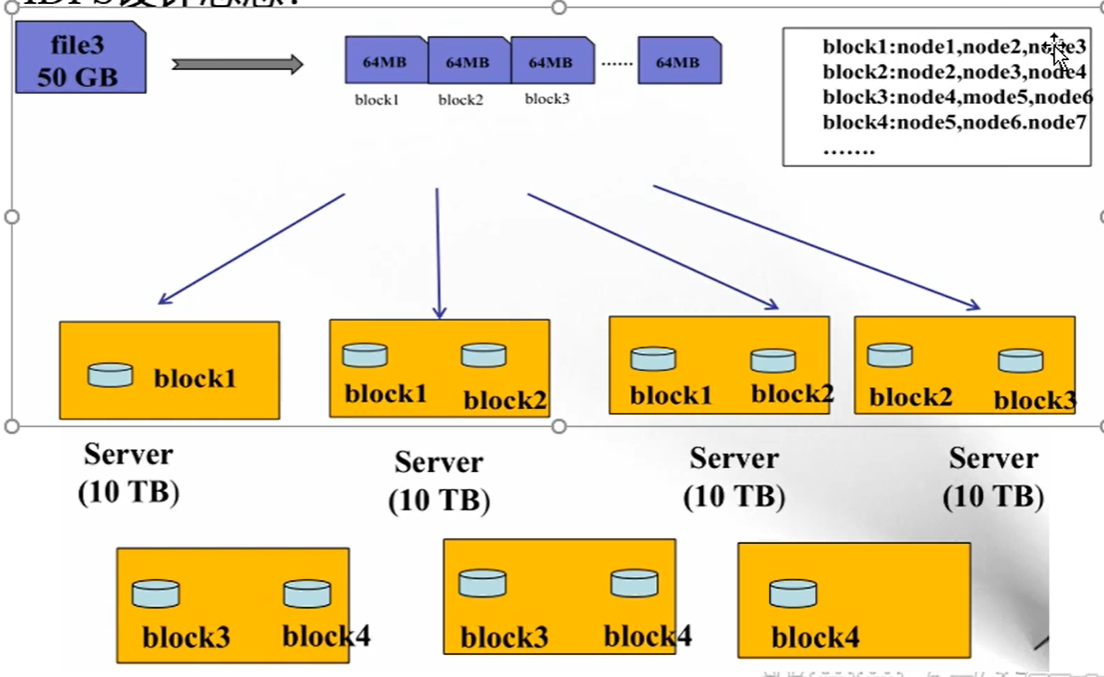

若有收获,就点个赞吧
0 人点赞
