1.读流程
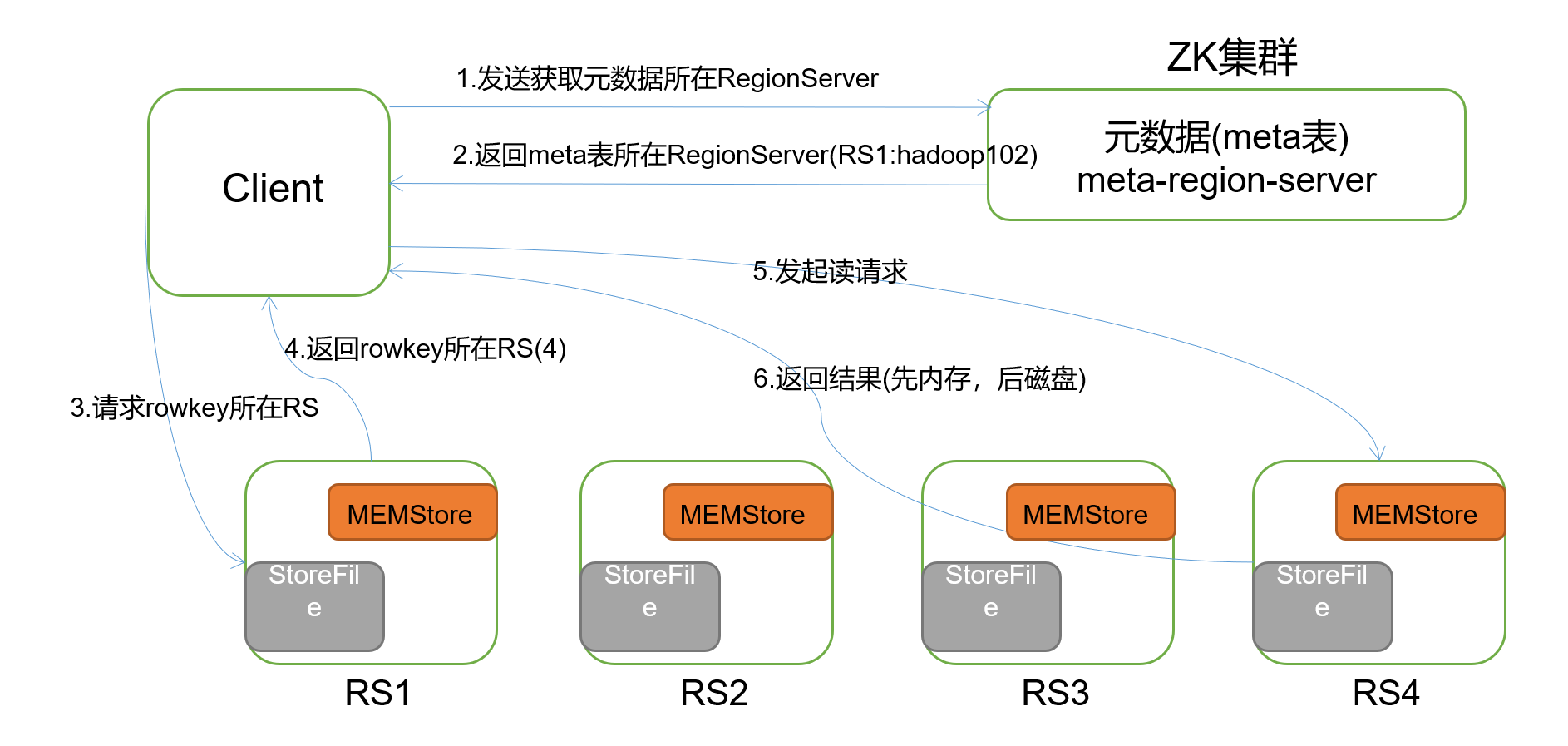
1.Client先访问zookeeper,通过/hbase/meta-region-server节点下查询到系统表meta的regionserver
2. 找到对应的regionServer,找到hbase:meta表数据根据namespace,rowkey,确定region及对应的regionserver
3.加载storefile和memstore数据,merge数据根据时间戳返回数据。(如果blockcache中存在storefile的文件那么可以不读storefile否则还是要读,总之hbase是一个写快读慢的框架)
2.写流程
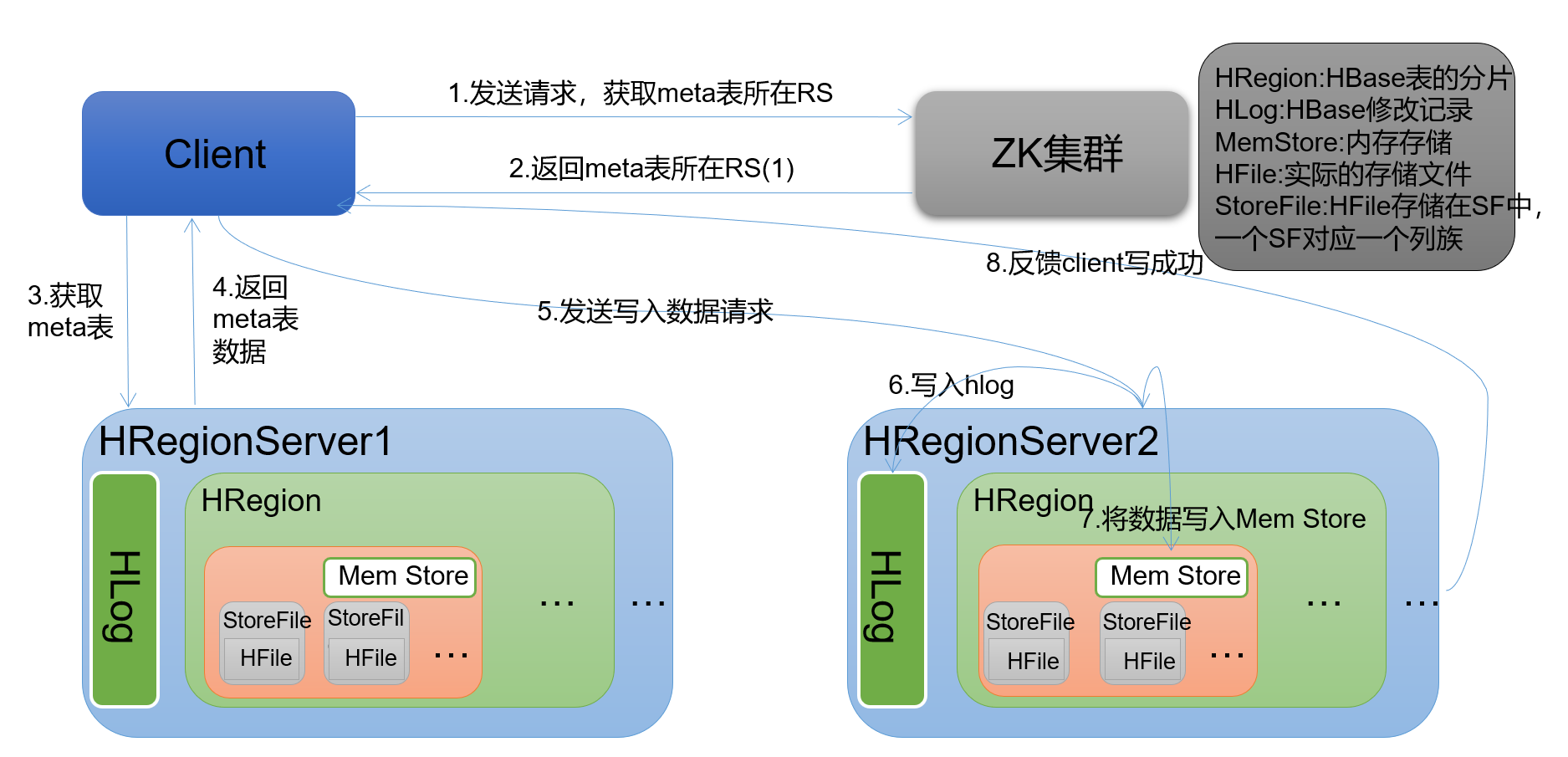
- Client先访问zookeeper,通过/hbase/meta-region-server节点下查询到系统表meta的regionserver 找到对应的
- regionServer,找到hbase:meta表数据根据namespace,rowkey,确定region及对应的regionserver
- Client连接对应的RegionServer上将数据写到HLog(write ahead log)的buffer并不会异步到磁盘中
- 然后再将数据接入到对应的region的store(其实时memstore)
- 写入memstore成功后将HLog中的buffer数据异步到磁盘,然后滚动版本这时候scan就可以查到
- 写入memstore过程中达到阈值(128M | 1h ) 将会触发flush线程,将文件刷写到hdfs形成storefile
当storefile达到阈值大于3个将触发compact,合并文件。。。待续
3.数据flush过程
当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
- 并将数据存储到HDFS中;
-
4.数据合并过程
当数据块达到3块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并;
- 合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理;
- 当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
- 注意:HLog会同步到HDFS。

若有收获,就点个赞吧
0 人点赞
