简介:
hadoop安装分为:Hadoop本地模式安装,伪分布式安装,分布式安装,HA.下面会具体讲下他们的安装过程。
本地模式部署:
先决条件:
下载hadoop文件(http://hadoop.apache.org/releases.html)
安装JDK
命令
cd hadoop~mkdir inputcp etc/hadoop/*.xml inputbin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar grep input output 'dfs[a-z.]+'cat output/*
伪分布式
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
hadoop能够以单节点作为伪分布式模式, 每个hadoop守护程序运行在一个独立的进程上。
修改配置
etc/hadoop/core-site.xml:
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>#注意默认hdfs文件路径是/tmp这个路径是相当危险的所以尽管不设置路径可以正常运行但是要是建议设置hdfs文件夹<property><name>hadoop.tmp.dir</name><value>/opt/data/tmp</value></property></configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
namenode格式化: bin/hdfs namenode -format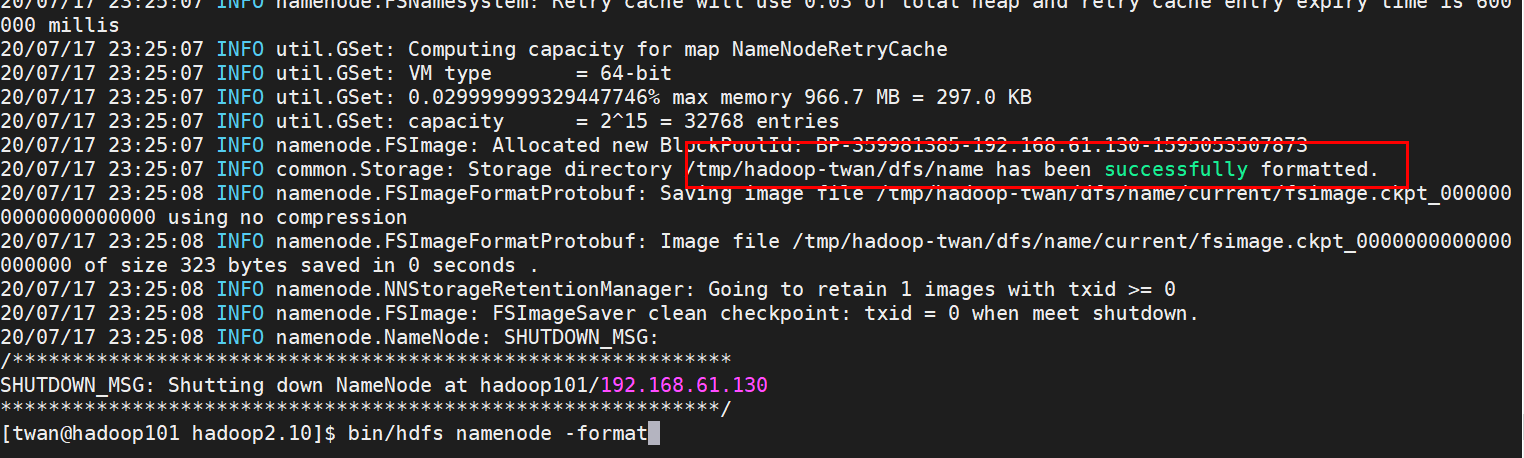
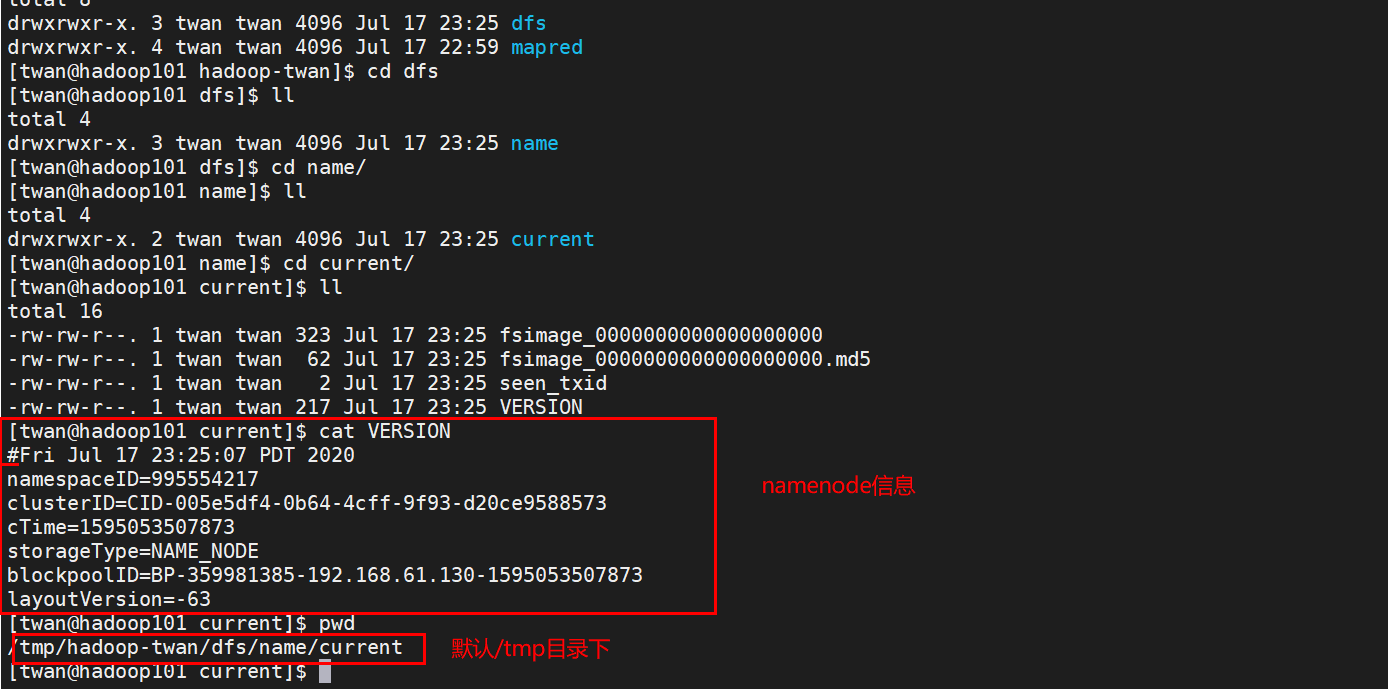
fsimage是NameNode元数据在内存满了后,持久化保存到的文件。
fsimage*.md5 是校验文件,用于校验fsimage的完整性。
seen_txid 是hadoop的版本
vession文件里保存:
namespaceID:NameNode的唯一ID。
clusterID:集群ID,NameNode和DataNode的集群ID应该一致,表明是一个集群。
启动datanode&namenode
启动namenode :sbin/hadoop-daemon.sh start namenode
启动datanode :sbin/hadoop-daemon.sh start datanode
启动Yarn
1.yarn-env.sh/mapred-env.sh 配置JAVA_HOME变量
2.yarn-site.xml配置
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
3.mapred-site.xml.template重新命名为-->mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.启动服务 sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager
5.执行wordcount程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar
wordcount /user/input /user/output
6. http://hadoop101:8088/cluster 查看执行结果
集群配置
集群规划:
| vm1 | vm2 | vm2 |
|---|---|---|
| NameNode | ResourceManage | |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| HistoryServer | SecondaryNameNode |
修改配置:
1.配置Hadoop JDK路径修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径
2.core-site.xml
<configuration>
<property>
#fs.defaultFS为NameNode的地址
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/app/hadoop-2.5.0/data/tmp</value>
</property>
</configuration>
3.hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
4.slaves
hadoop101
hadoop102
hadoop103
5.yarn-site.xml根据规划:
yarn.resourcemanager.hostname这个指定resourcemanager服务器指向hadoop102
yarn.log-aggregation-enable是配置是否启用日志聚集功能
yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多长时间。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
启动:
hadoop101: sbin/start-yarn.sh 在hadoop102启动nodemanager
sbin/start-dfs.sh 启动datenode,namenode,secondary namenode
hadoop102:sbin/start-yarn.sh#在hadoop102上启动ResourceManager
hadoop103: sbin/mr-jobhistory-daemon.sh start historyserver
验证:
yanr页面:http://hadoop102:8088/cluster
hdfs页面:http://hadoop101:50070/dfshealth.html#tab-datanode
高可用
高可用参考高可用篇
参考文档:
史上最详细、最全面的Hadoop环境搭建
相关问题

若有收获,就点个赞吧
0 人点赞
