1.单机模式
1.解压2.bin/spark-shell3.sc.textFile("file:///export/data/mr/wordcount/input/1.txt").flatMap(_.split(" ")).map(_- >1).reduceByKey(_+_).collect;启动成功 http://node1:4040
2.StandaloneHA
StandAlone就是将Spark的角色,以独立的进程的形式运行在服务器上,其中包含2个角色:master和worker
表现形式:
1.伪分布式:Master进程和Worker进程在一台机器内运行
2.完全分布式(测试开发用):将Master进程和Worker进程分开
3.高可用的完全分布式模式: 将Master进程和Worker进程分开在不同的机器上运行,同时,拥有多个Master做备份
2.1Standalone 架构
Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。
Spark Standalone集群类似yarn 管理集群和调度资源
主节点Master:
管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
从节点Workers:
管理机器的资源,分配资源运行相应的task任务另外需要上报资源的信息比如men和cpu数等
HistoryServer:
可选可以将日志保存在hdfs上
2.2配置
集群规划:node1:masternode2:slave/workernode3:slave/worker1.修改conf目录下的slaves.template为slaves并增加work的配置node2node32.修改spark-env.sh## 设置JAVA安装目录JAVA_HOME=/export/server/jdk1.8.0_241## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群HADOOP_CONF_DIR=/export/server/hadoop2.7/etc/hadoopYARN_CONF_DIR=/export/server/hadoop2.7/etc/hadoop## 指定spark老大Master的IP和提交任务的通信端口export SPARK_MASTER_HOST=node1export SPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080SPARK_WORKER_CORES=1SPARK_WORKER_MEMORY=1g3分到到其他机器4.mastar集群 /export/server/spark-2.4.5-bin-hadoop2.7/sbin/start-all.sh5.bin/spark-shell --master spark://node1:7077连接测试发现sc' (master = spark://node1:7077, app id = app-20210325235415-0000)页面查看http://node1:8080/
2.3架构
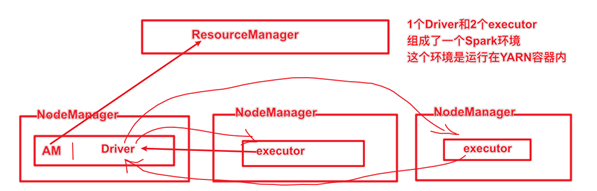
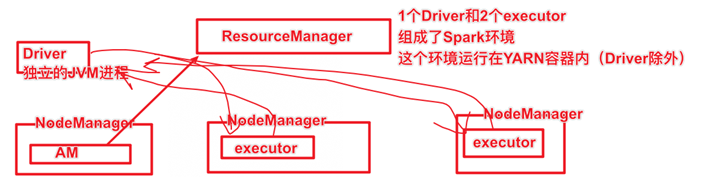
spark Application运行到集群上时,由两部分组成:Driver Program和Executors1.Driver Program相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;运行JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;一个SparkApplication仅有一个2.Executors相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,一个Task运行需要1 Core CPU,所有可以认为Executor中线程数就等于CPU Core核数.一个Spark Application可以有多个
3.Spark on YARN
Spark运行在YARN上是有2个模式的, 1个叫 Client模式 一个叫Cluster模式
3.1Cluster模式
3.2Client模式
Yarn是一个成熟稳定且强大的资源管理和任务调度的大数据框架,在企业中市场占有率很高,意味着有很多公司都在用Yarn,将公司的资源交给Yarn做统一的管理!并支持对任务做多种模式的调度,如FIFO/Capacity/Fair等多种调度模式! 参考文档
3.3总结
1.Spark On Yarn的本质
其实就是将Spark任务的class字节码文件打成jar包,提交到Yarn的JVM中去运行
2.Spark On Yarn需要啥
1.需要Yarn集群:已经安装了
2.需要提交工具:spark-submit命令—在spark/bin目录
3.需要被提交的jar:Spark任务的jar包(如spark/example/jars中有示例程序,或我们后续自己开发的Spark任务)
4.需要其他依赖jar:Yarn的JVM运行Spark的字节码需要Spark的jar包支持!Spark安装目录中有jar包,在spark/jars/中
3.修改配置
当Spark Application运行到YARN上时,在提交应用时指定master为yarn即可,同时需要告知YARN集群配置信息(比如ResourceManager地址信息),此外需要监控Spark Application,配置历史服务器相关属性。
1.修改spark-env.sh## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群HADOOP_CONF_DIR=/export/server/hadoop2.7/etc/hadoopYARN_CONF_DIR=/export/server/hadoop2.7/etc/hadoop2.修改 hadoop/yarn-site.xml指定MRHistoryServer地址信息3.修改spark-defaults.conf配置文件spark.eventLog.enabled truespark.eventLog.dir hdfs://ns/sparklog/spark.eventLog.compress truespark.yarn.historyServer.address node2:180804.hadoop fs -mkdir -p /sparklog5.修改日志级别6.当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。## hdfs上创建存储spark相关jar包目录hadoop fs -mkdir -p /spark/jars/## 上传$SPARK_HOME/jars所有jar包hadoop fs -put /export/server/spark-2.4.5-bin-hadoop2.7/jars/* /spark/jars/7.spark-defaults.confspark.yarn.jars hdfs://ns/spark/jars/*8验证bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.4.5.jar 10注意使用的是cluster模式的话 --deploy-mode cluster 结果的查看yarn logs -applicationId application_1616837584760_0001

若有收获,就点个赞吧
0 人点赞
