1.初识RDD
RDD:Resilient Distributed Datasets)弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
1.1RDD的5个特性
- A list of partitions一个数据集分成多个区提高了任务的并行度
- A function for computing each split: Spark中RDD都是以分片为单位的,每个单位实现compute函数
- A list of dependencies on other RDD: RDD之前相互依赖
- Optionally a Partitioner for key-value RDDs : key value 型数据包含分区信息
存储每个切片优先(preferred location)位置的列表也就是说spark会尽量将任务创建到数据的机器来达成计算向数据移动
1.2RDD特点
1.2.1弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分
1.2.2分区
RDD逻辑是分区的 。RDD列中定义compute函数由每个RDD实现,实现类通过该函数得到分区的数据。如果是textFile那么读取指定文件系统中的数据,如果是其他RDD而来那么会执行转换逻辑将其他RDD的数据进行转换1.2.3只读
RDD中的数据是只读的。如果想改变RDD中的数据只能创建一个新的RDD.主要包括两类 transformation(转换懒加载会生成一个新的RDD)和Action(行动算了触发计算)
1.2.4依赖
RDDs之间维护着这种血缘关系,也称之为依赖。一种是窄依赖,RDDs 之间分区是一一对应的。另一种是宽依赖,下游 RDD 的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。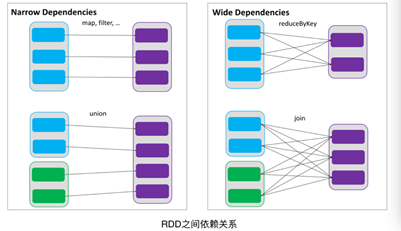
1.2.5缓存
如果程序中多次使用同一个RDD,那么可以将此RDD的结果缓存下来,这样只有第一次的时候会根据依赖得到分区的数据。这样后续在使用的时候可以直接使用缓存的数据1.2.5checkpoint
虽然rdd的血缘关系可以实现容错,即当程序运行出错的时候可以更具依赖关系重新计算。但是如果从头开始计算的那么迭代的时间越长,势必会影响性能。为此RDD支持checkpoint 将保存到持久化的存储中。这样就可以切断之前的血缘关系,因为checkpoint后的RDD可以直接从checkpoint中取数据1.3RDD分区
数据在 RDD 内部被切分为多个子集合,每个子集合可以被认为是一个分区,运算逻辑最小会被应用在每一个分区上,每个分区是由一个单独的任务(task)来运行的,所以分区数越多,整个应用的并行度也会越高。RDD的分区数据的决定因素:
RDD分区的原则是:分区数尽量等于机器的CPU核心数,这样可以充分发挥cpu的计算资源
并行度设置为cpu核数的2~3倍
RDD中指定的分区数,cpu数或者自身的分区数(如果没有指定默认时2,本地文件max(本地file的分片数,2) ,hdfs 文件 max(hdfs文件的block数目,2))**2.常见算子
2.1checkpoint会将数据保存到 指定的 CheckPoint的检查点路径去(通过setCheckpointDir 设置路径)2.2cache缓存到内存中, 不会被删除掉等同persist, 默认 调用的是 persist(StorageLevel.MEMORY_ONLY)2.3unpersist释放内存注意只有通过persist方式创建的才可以删除,调用cache方式的不能释放

若有收获,就点个赞吧
0 人点赞
