目录
- 1 简介
- 2 决策树学习算法步骤
- 3 建立决策树
1 简介
决策树是依据树的结构来进行决策的,这恰好也是人类在面临决策问题时候很自然的处理机制。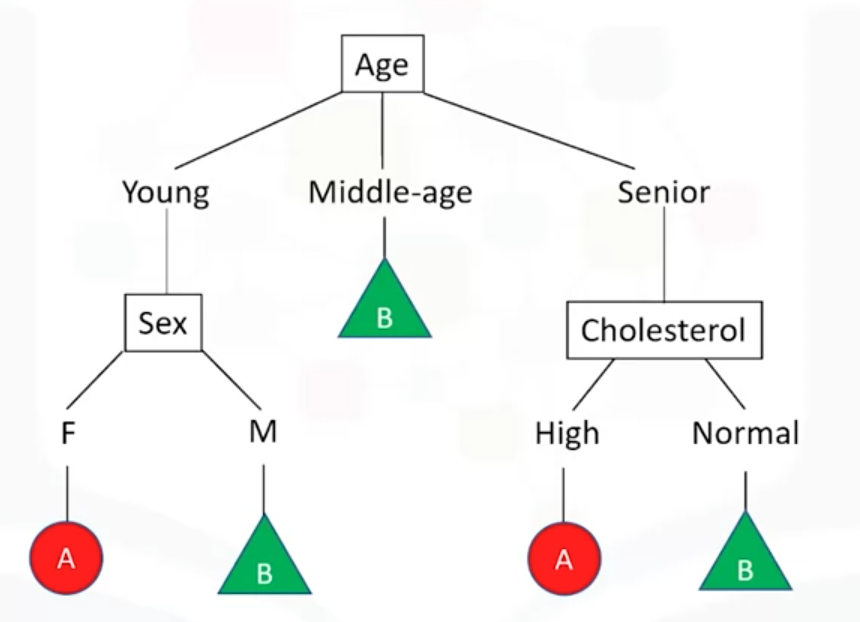
2 决策树学习算法步骤
(1)选择一个数据集中的属性choose an attribute from your dataset
(2)计算划分属性重要性Calculate the significance of attribute in splitting of data
(3)根据最佳属性划分数据Split data based on the value of the best attribute
(4)回到第一步重复Go to step 1
3 建立决策树
(1)选择最好的属性,需要引入熵
熵Entropy:它表示一个系系统在不受外部干扰时,其内部最稳定的状态.是随机性和不确定性的度量。熵越小,越是不均匀分布,节点更好。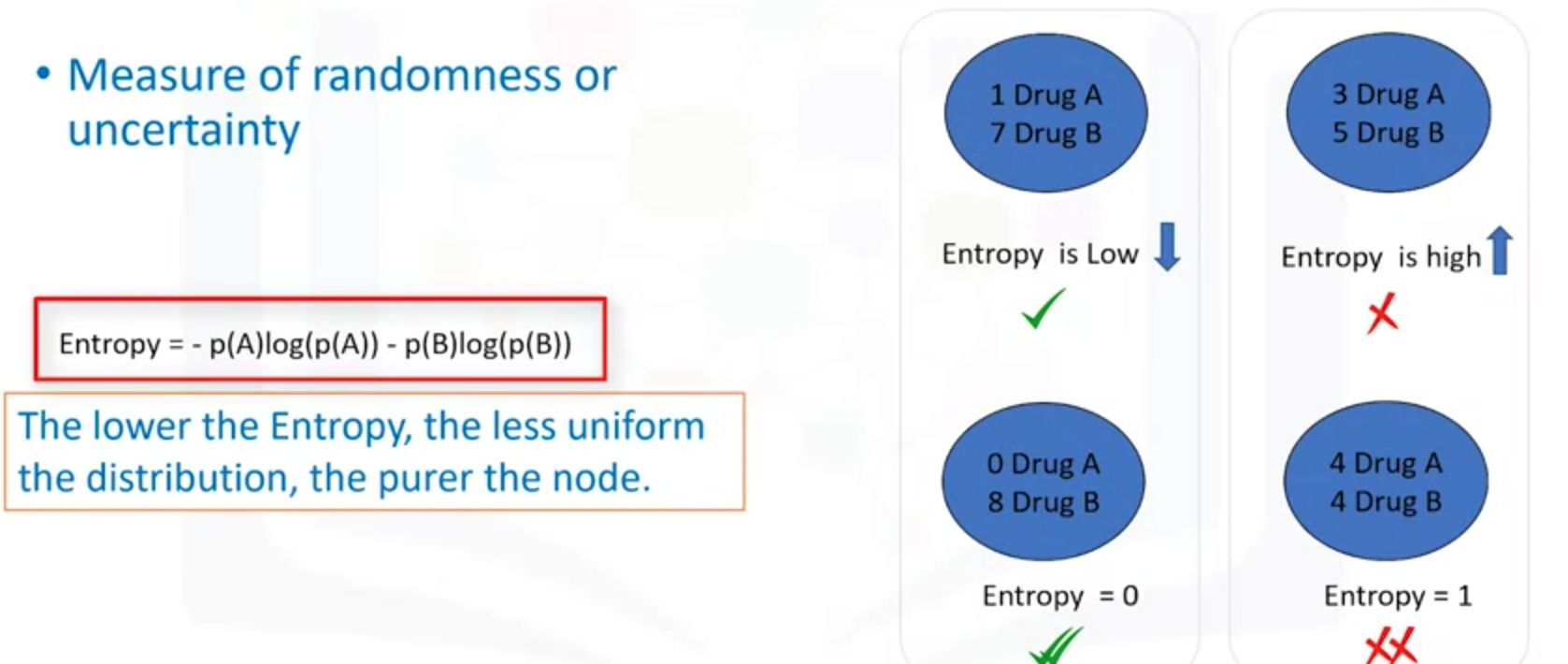
(2)计算每个属性划分下的熵值,再引入信息增益
当选择Choleserol属性作为划分时,分别计算熵值。Nomal 和High的熵值分别是0.811、1。熵的计算是有专门的工具箱计算的。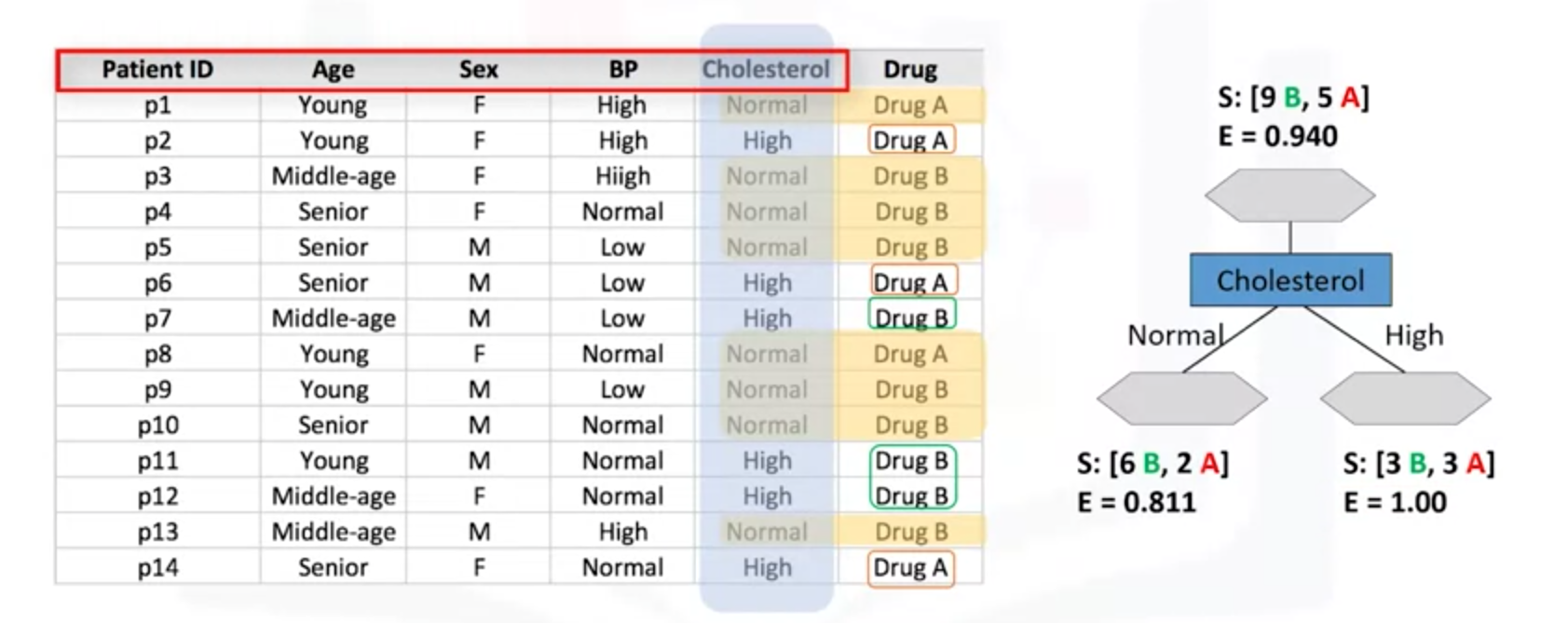
当选择Sex属性作为划分时,Fmale和Male的熵值分别是0.985、0.592。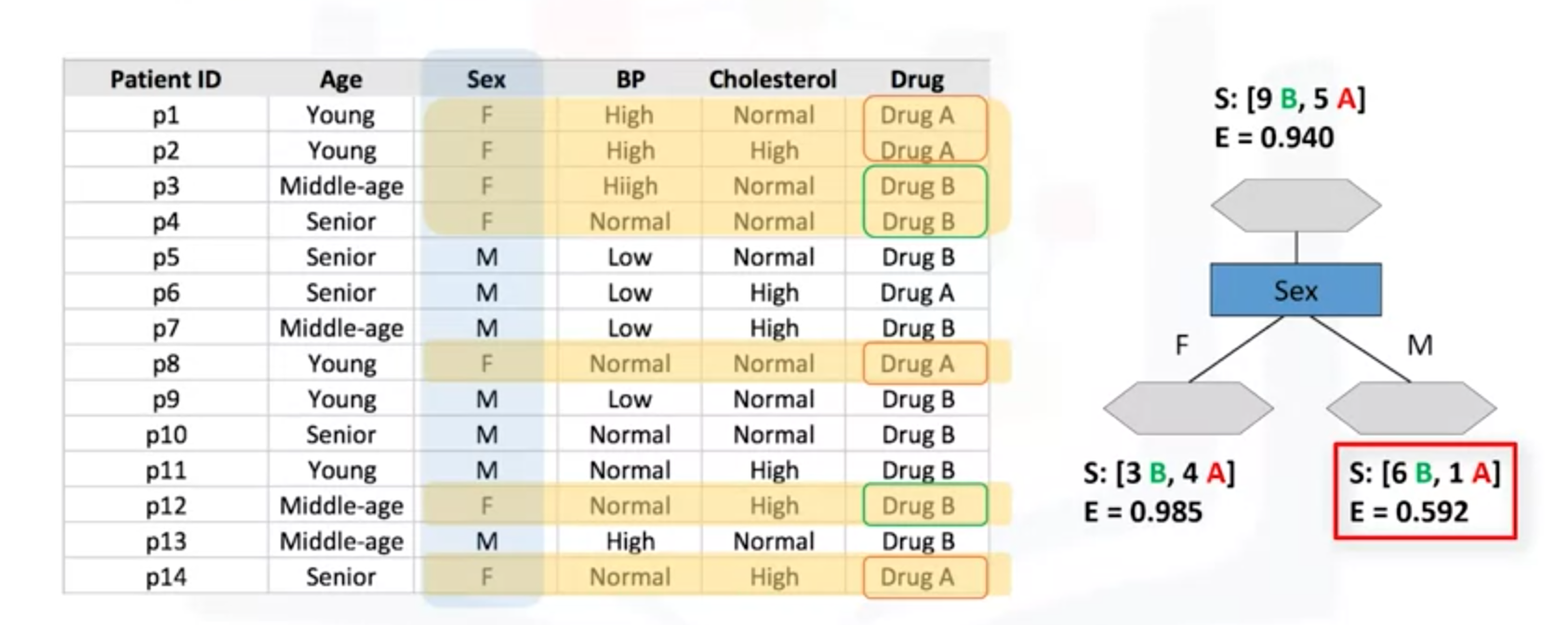
如何根据熵值选择属性,需要引入信息增益(Information Gain)
信息增益:是在划分属性后能够增加确定性的信息。信息增益 = (划分前熵值)-(划分后熵)
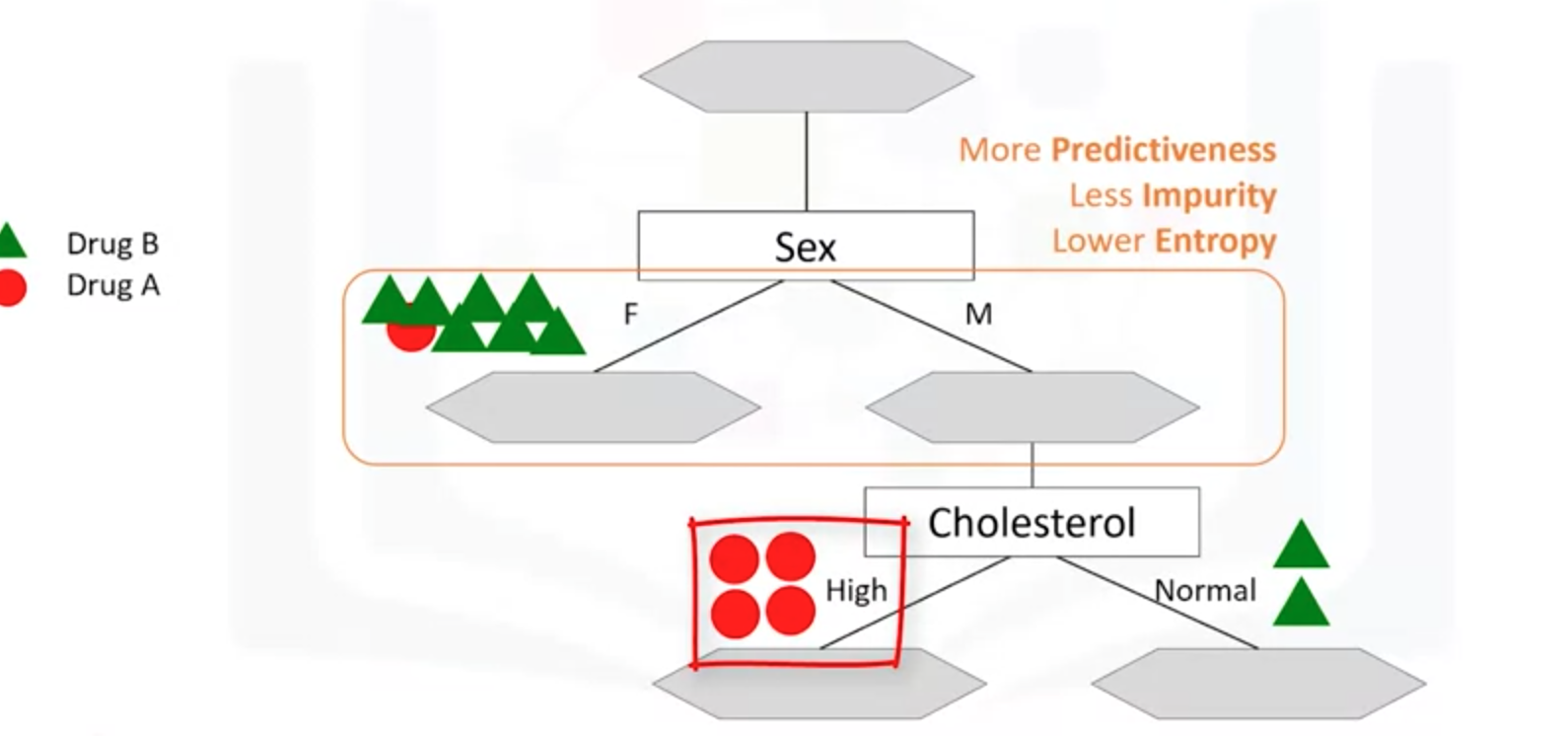
(3)计算信息增益,选择信息增益较大的作为划分属性。以下sex属性划分时候的信息增益是0.151,Cholesterol的信息增益是0.048。选择较大增益Sex的属性作为决策树的下一个节点。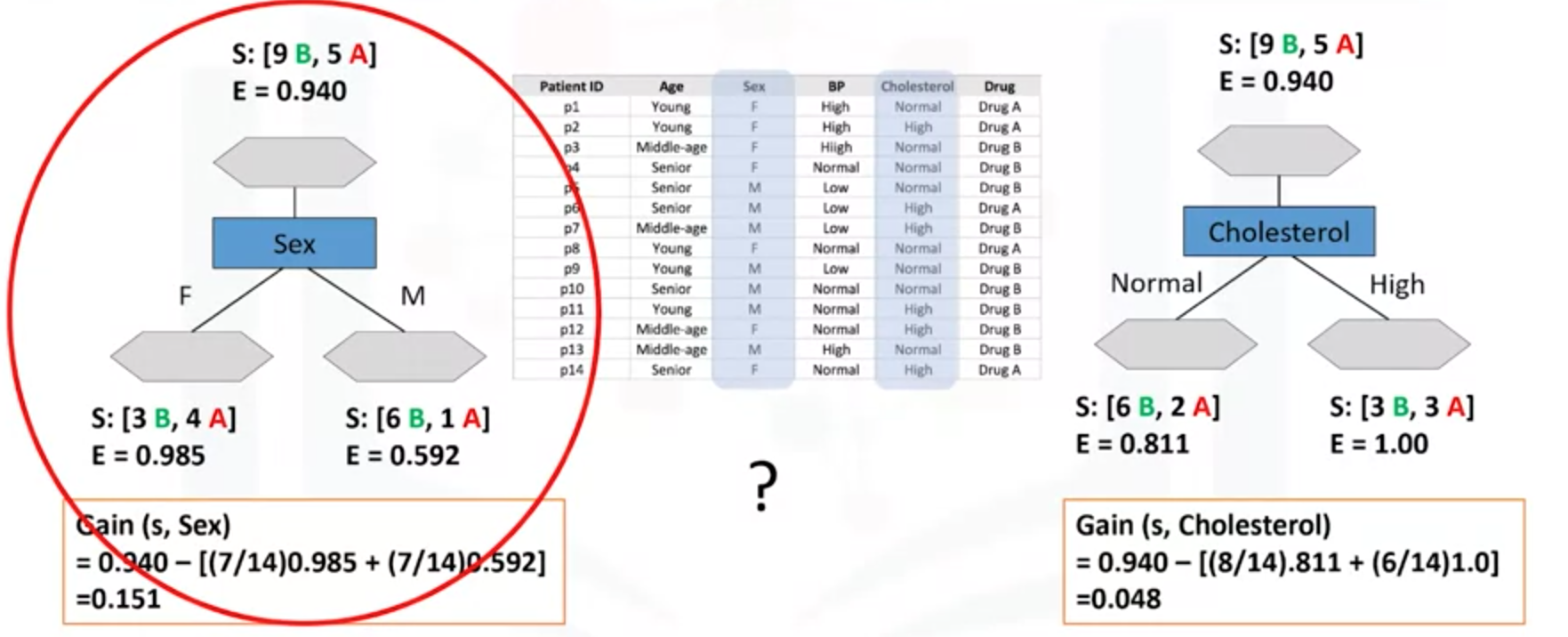

若有收获,就点个赞吧
0 人点赞
