目录
1 密度聚类
(1)大多数传统的聚类技术(例如K-Means,分层聚类和模糊聚类)可用于以无人监督的方式对数据进行分组。 但是,当应用于具有任意形状的群集或群集中的群集的任务时,传统技术可能无法获得良好的结果,也就是说,同一群集中的元素可能没有足够的相似性,或者性能可能很差。
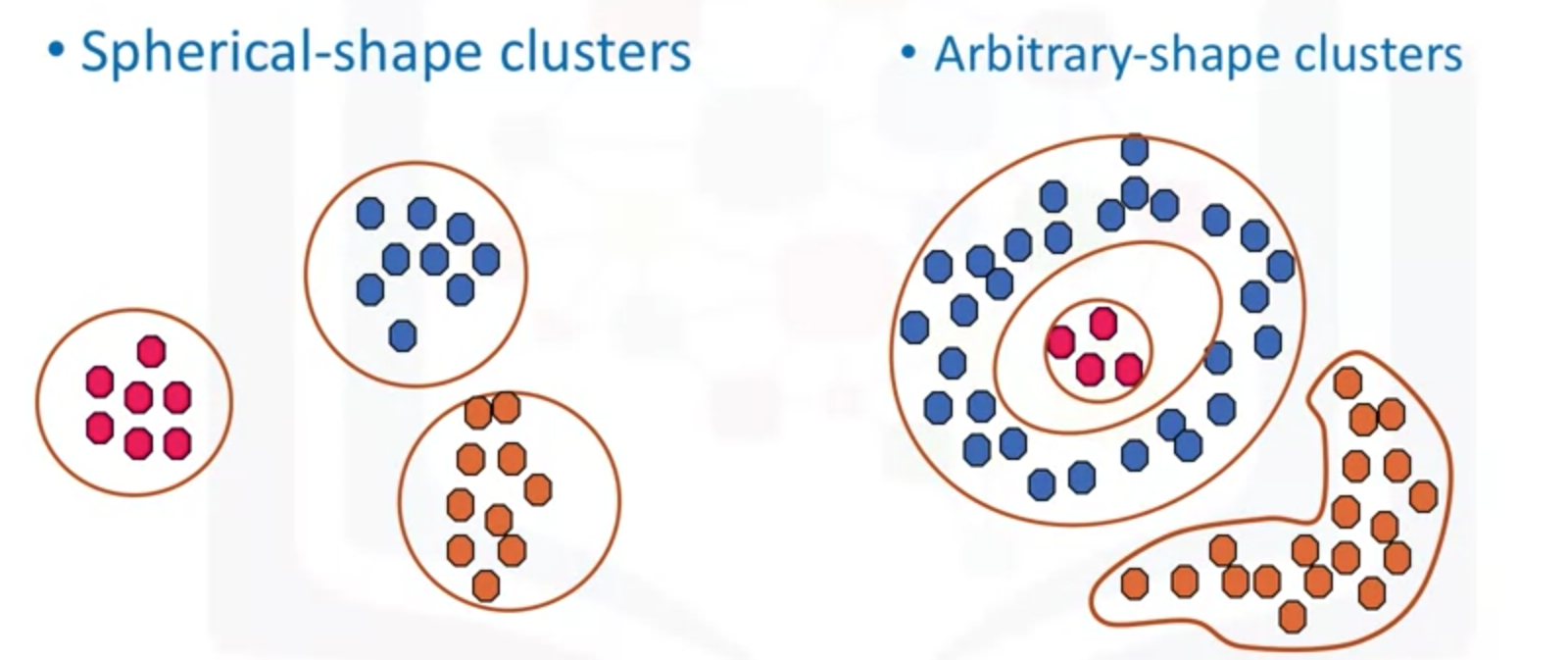
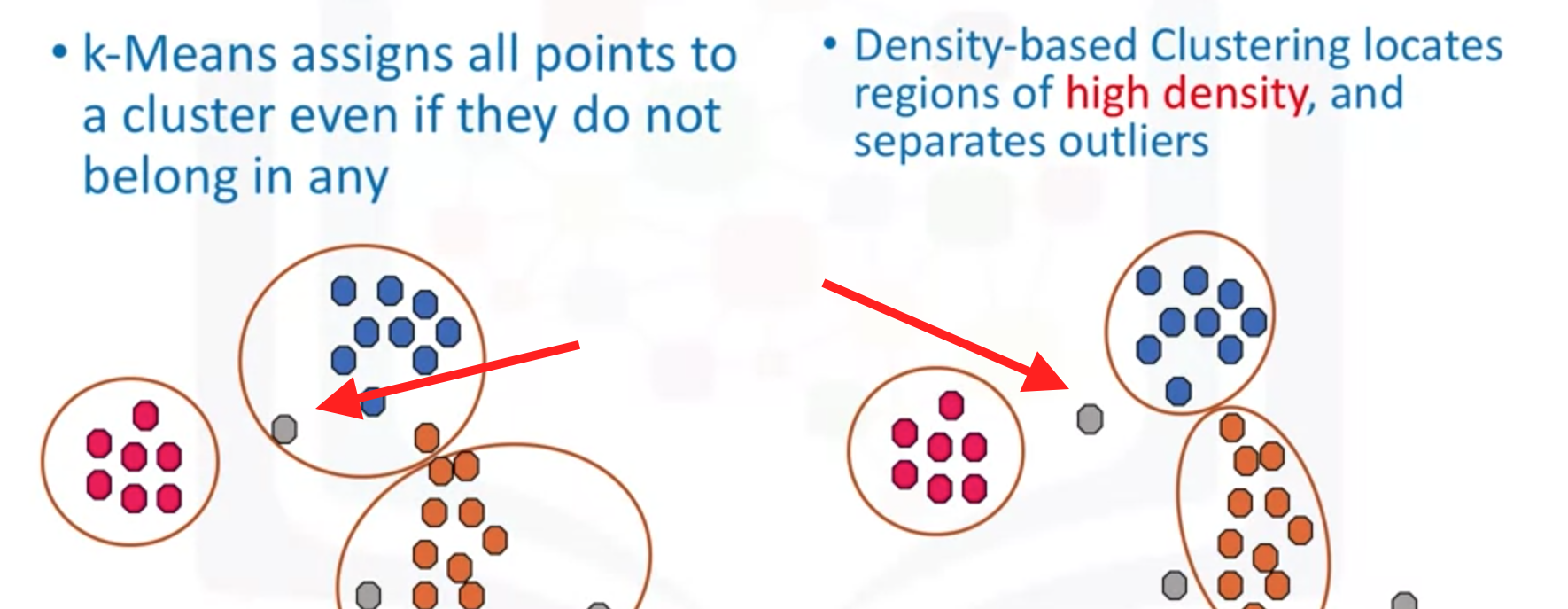
(2)在传统的聚类算法中,会把一些异常点也会分类进一个簇中,但是利用密度聚集算法,不在规定半径范围内的异常点,是能够区分开的。
2 DBSCAN
(1)对于上下文的分类非常有效,能够找到任意形状的聚类,而不会收到噪声的影响。比如以下气象台的数据例子,通过忽略不太密集的区域或噪声来找到以数据为中心的样本的密度成分。
(2)DBSCAN(Density-Based spatial Clustering of Applications with Noise)
- 是最常用的聚类算法
- 基于物体的密度工作的
- 有两个参数
- R(Radius of neighborhood)邻近点的半径:如果在半径范围你有足够的点,称这个以R为半径的圆区域是密度区域
- M(邻近点数量的最小值)
(3)举例说明工作原理
首先数据集中的点可以分为核心点(core point)、边界点(liner pointer)或异常点(outliner point)。
算法的思想是首先访问每个点并找到它的类型,然后根据它们的类型将点进行分组为聚类。举例半径为R,M=6.
任意如下选一个点,然后以这个半径计算圆内是否满足六个点,显然这点红色点是核心点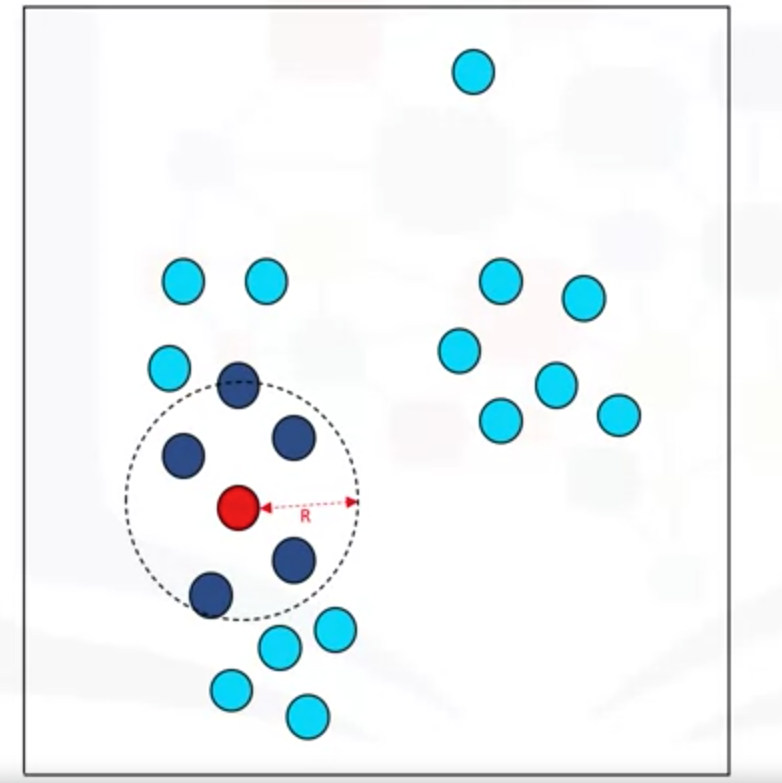
第二个点,R半径内圆内的点数量只有五个,不是核心点,属于边界点
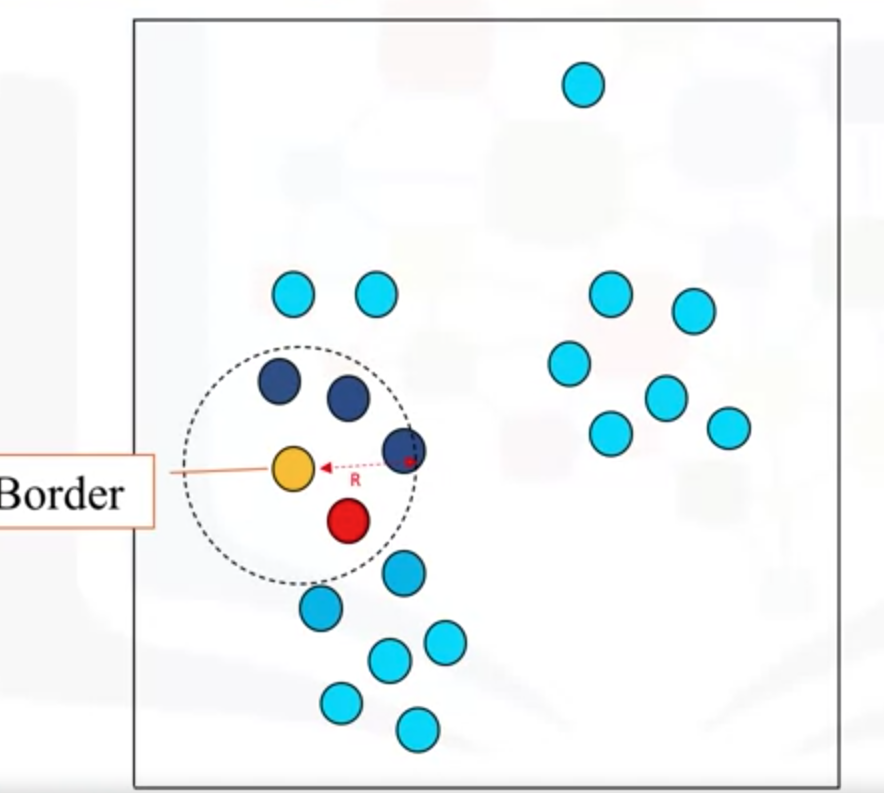
以下点是异常点,半径范围内,只有它本身一个点。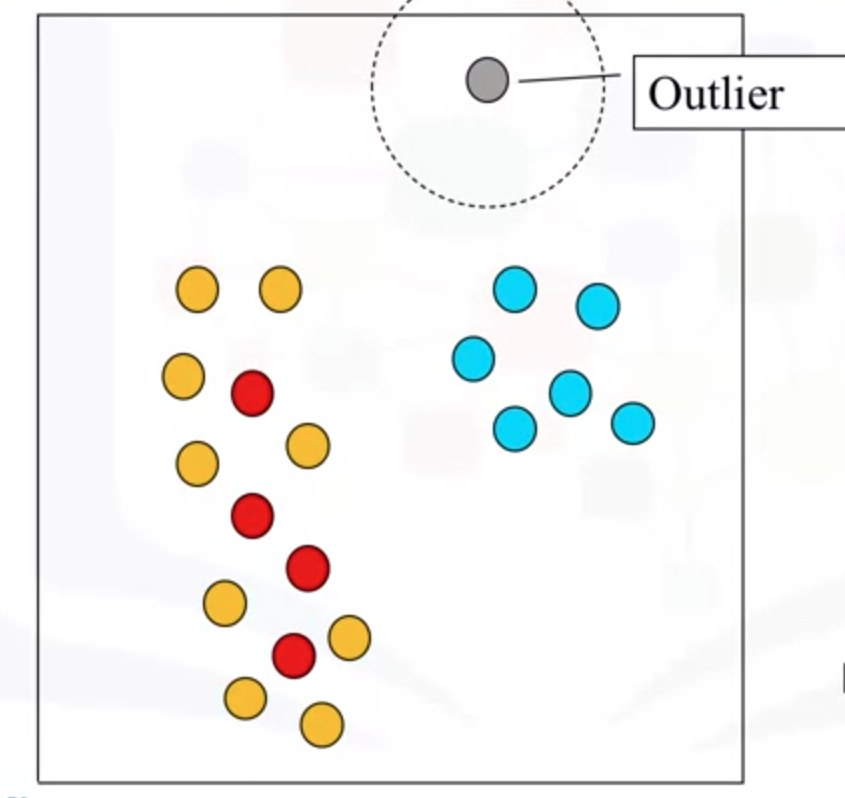
半径范围内有6个点,是核心点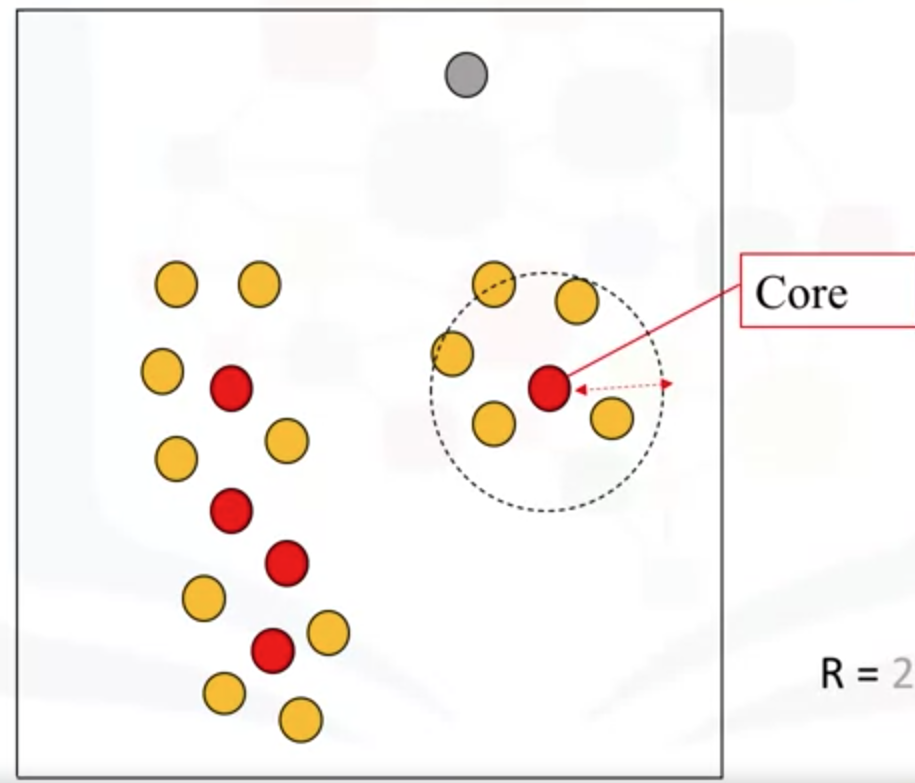
把同一类的点进行聚类
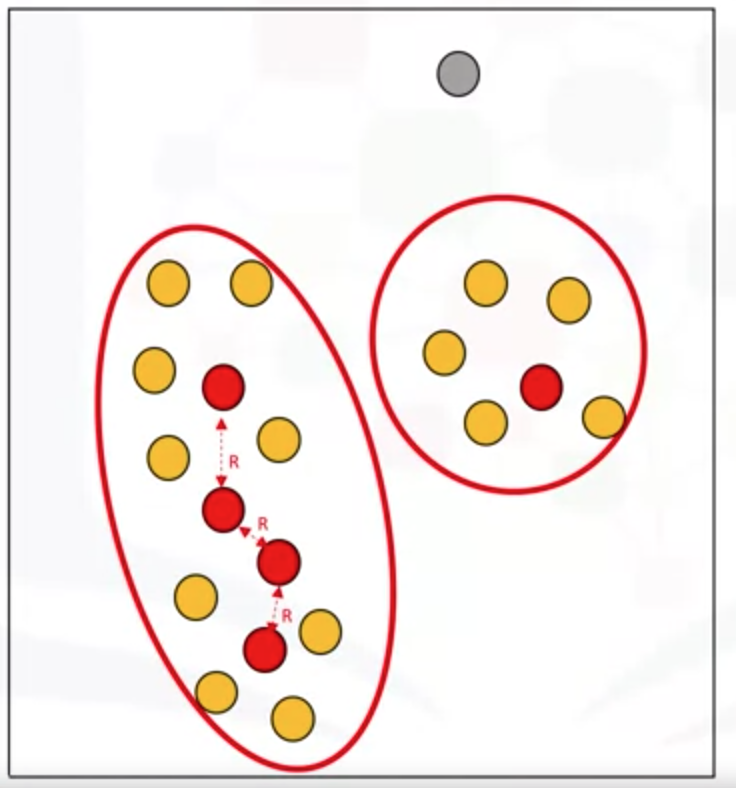
(4)DBSCAN的优点
- 可以划分任意形状的簇
- 可以划分出异常点
- 不要求指定簇的数量

若有收获,就点个赞吧
0 人点赞
