1 引言
目前选取3个特征:
- 原本 text部分的所有字符
- 句子长度
- 每个句子的前10个高频字符(去除标点符号的)
2 步骤
2.1 导入工具包
```python import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns from scipy import stats
from sklearn.preprocessing import MultiLabelBinarizer from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse
<a name="ecLvf"></a>## 2.1 统计top10高词频作为一个特征```python# 统计句子中的前10个高频字符,添加到train_data组成新的特征def select_top10_highfrequency_word(data):text_Word_frequency = []from collections import Counterdatalen = len(data)for i in range(0,datalen):one_lines = ''.join(list(data['text'][i][1:-1]))all_word_count = Counter(one_lines.split(" "))all_word_count = sorted(all_word_count.items(), key=lambda d:d[1], reverse = True)# 删除693和328两个字符,根据数据分析阶段的词频统计,这两个字符可能是标点符号dict_word_count = dict(all_word_count)if dict_word_count.get('693') !=None:del dict_word_count['693']if dict_word_count.get('328') !=None:del dict_word_count['328']# 取前10个高频词word_count ={}if len(dict_word_count) > 9:for i,(k,v) in enumerate(dict_word_count.items()):word_count[k] = vif i ==9:breakelse:word_count =dict_word_countstring_top10_high_frequency_word = list(word_count.keys())if '' in string_top10_high_frequency_word:string_top10_high_frequency_word.remove('')list_to_str = " ".join(string_top10_high_frequency_word)text_Word_frequency.append(list_to_str)return text_Word_frequency
2.2 统计句子长度作为第二个特征
# 统计每行的句子长度并添加到train_data中组成新的一个特征def count_text_len(data):text_len =[]datalen = len(data)for i in range(0,datalen):one_lines = ''.join(list(data['text'][i][1:]))len_text = one_lines.split(" ")text_len.append(len(len_text))return text_len
2.3 原始数据text作为第三个特征
# 去除text中的|字符和首尾空格def modify_text(data):new_text =[]datalen = len(data)for i in range(0,datalen):one_lines = ''.join(list(data['text'][i][1:-1])).strip()new_text.append(one_lines)return new_text
2.4 label缺失值处理
# label缺失值处理,为空的label设置为字符串17,代表无异常def label_code(data):new_code_label =[]datalen = len(data)for i in range(0,datalen):one_lines = ''.join(list(data['label'][i][1:])).strip()if one_lines =='':#空labelnew_code_label.append('17')else:new_code_label.append(one_lines)return new_code_label# print()
2.5 IDTDF算法提取text和highfrequency两列数据的特征
def feature_extraction_tfidf_vectorizer(data,columns_list):TfidfVec = TfidfVectorizer(ngram_range=(1,1),max_features=100)for i,col in enumerate(columns_list):TfidfVec.fit(data[col])data_temp = TfidfVec.transform(data[col])if i==0 :data_cat = data_tempelse:data_cat = sparse.hstack((data_cat,data_temp))df_tfidf = pd.DataFrame(data_cat.toarray())return df_tfidf
3 Main函数
if __name__=="__main__":test_data = pd.read_csv('./data/track1_round1_testA_20210222.csv',header=None, names=['id', 'text'])#sep='\t',train_data = pd.read_csv('./data/track1_round1_train_20210222.csv',header=None, names=['id', 'text','label'])# 训练集的sample集和label集,测试集的sample集all_train_data_sample = pd.DataFrame(columns=['textlen'])all_train_data_label = pd.DataFrame(columns=['label'])all_test_data_sample = pd.DataFrame(columns=['textlen'])# 生成label集合,一个标签占一个表格,总共有18列,最后一列表示无异常train_data_label = pd.DataFrame(columns=['label'])train_data_label['label'] = label_code(train_data)mlb = MultiLabelBinarizer(classes=['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17'])#17表示无异常Ylist = []all_train_data_label = pd.DataFrame(columns=['f0','f1', 'f2', 'f3','f4','f5','f6','f7', 'f8', 'f9','f10','f11','f12','f13', 'f14', 'f15','f16','f17'],index=[])indexsize = 0for i in range(len(train_data_label)):templist = train_data_label['label'][i].split()# 转二值化编码label_code_list = list(mlb.fit_transform(templist)[0])print(indexsize)# 0,1表示,一个数字占一个表格# str_label_list = list(map(lambda x:str(x).encode('UTF-8'), label_code_list))byte_label = list(map(int, label_code_list))all_train_data_label.loc[indexsize] =byte_labelindexsize = indexsize + 1train_data_label.to_csv('./data/train_data_label.csv',index=False)print()# 生成三个特征的sample训练集train_data_sample = pd.DataFrame(columns=['text', 'textlen', 'highfrequency'])# 训练集中统计句子中的前10个高频字符,添加到train_data组成新的特征train_data_sample['highfrequency'] = select_top10_highfrequency_word(train_data)# 训练集中统计每行的句子长度并添加到train_data中组成新的一个特征train_data_sample['textlen'] = count_text_len(train_data)# 去除text中的|字符和首尾空格train_data_sample['text'] = modify_text(train_data)# train_data_sample.to_csv('./data/train_data_sample.csv',index=False)df_tfidf = feature_extraction_tfidf_vectorizer(train_data_sample,['text','highfrequency'])df_tfidf.columns = ['tfidf_'+str(i) for i in df_tfidf.columns]all_train_data_sample['textlen'] = train_data_sample['textlen']all_train_data_sample = pd.concat([all_train_data_sample,df_tfidf],axis = 1)all_train_data_sample.to_csv('./data/all_train_data_sample.csv')# 生成三个特征的测试集test_data_sample = pd.DataFrame(columns=['text', 'textlen', 'highfrequency'])# 测试集中统计句子中的前10个高频字符,添加到test_data组成新的特征test_data_sample['highfrequency'] = select_top10_highfrequency_word(test_data)# 测试集中统计每行的句子长度并添加到test_data中组成新的一个特征test_data_sample['textlen'] = count_text_len(test_data)# 去除text中的|字符和首尾空格test_data_sample['text'] = modify_text(test_data)df_tfidf = feature_extraction_tfidf_vectorizer(test_data_sample,['text','highfrequency'])df_tfidf.columns = ['tfidf_'+str(i) for i in df_tfidf.columns]all_test_data_sample['textlen'] = test_data_sample['textlen']all_test_data_sample = pd.concat([all_test_data_sample,df_tfidf],axis = 1)all_test_data_sample.to_csv('./data/all_test_data_sample.csv')print()
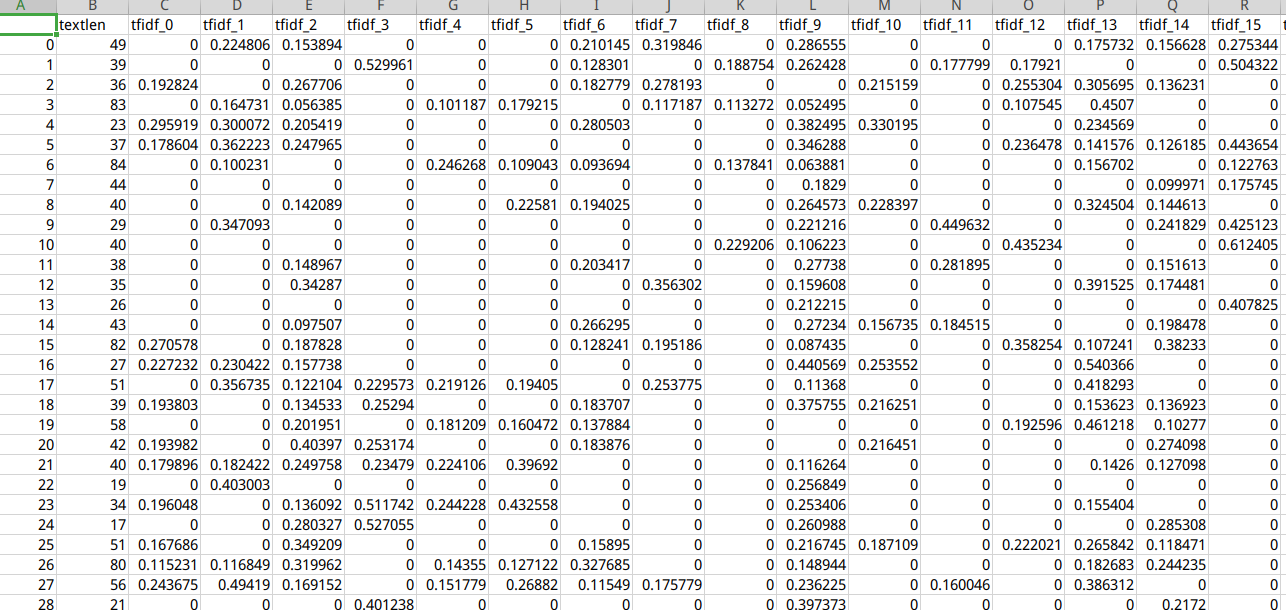
4 数据格式展示
4.1 训练样本集
train_data_sample = pd.read_csv('./data/all_train_data_sample.csv')print(train_data_sample.info())
RangeIndex: 10000 entries, 0 to 9999 Data columns (total 82 columns): Column Non-Null Count Dtype
0 Unnamed: 0 10000 non-null int64
1 textlen 10000 non-null int64
2 tfidf_0 10000 non-null float64
3 tfidf_1 10000 non-null float64
4 tfidf_2 10000 non-null float64
5 tfidf_3 10000 non-null float64
6 tfidf_4 10000 non-null float64
7 tfidf_5 10000 non-null float64
8 tfidf_6 10000 non-null float64
9 tfidf_7 10000 non-null float64
10 tfidf_8 10000 non-null float64
11 tfidf_9 10000 non-null float64
12 tfidf_10 10000 non-null float64
13 tfidf_11 10000 non-null float64
14 tfidf_12 10000 non-null float64
15 tfidf_13 10000 non-null float64
16 tfidf_14 10000 non-null float64
17 tfidf_15 10000 non-null float64
18 tfidf_16 10000 non-null float64
19 tfidf_17 10000 non-null float64
20 tfidf_18 10000 non-null float64
21 tfidf_19 10000 non-null float64
22 tfidf_20 10000 non-null float64
23 tfidf_21 10000 non-null float64
24 tfidf_22 10000 non-null float64
25 tfidf_23 10000 non-null float64
26 tfidf_24 10000 non-null float64
27 tfidf_25 10000 non-null float64
28 tfidf_26 10000 non-null float64
29 tfidf_27 10000 non-null float64
30 tfidf_28 10000 non-null float64
31 tfidf_29 10000 non-null float64
32 tfidf_30 10000 non-null float64
33 tfidf_31 10000 non-null float64
34 tfidf_32 10000 non-null float64
35 tfidf_33 10000 non-null float64
36 tfidf_34 10000 non-null float64
37 tfidf_35 10000 non-null float64
38 tfidf_36 10000 non-null float64
39 tfidf_37 10000 non-null float64
40 tfidf_38 10000 non-null float64
41 tfidf_39 10000 non-null float64
42 tfidf_40 10000 non-null float64
43 tfidf_41 10000 non-null float64
44 tfidf_42 10000 non-null float64
45 tfidf_43 10000 non-null float64
46 tfidf_44 10000 non-null float64
47 tfidf_45 10000 non-null float64
48 tfidf_46 10000 non-null float64
49 tfidf_47 10000 non-null float64
50 tfidf_48 10000 non-null float64
51 tfidf_49 10000 non-null float64
52 tfidf_50 10000 non-null float64
53 tfidf_51 10000 non-null float64
54 tfidf_52 10000 non-null float64
55 tfidf_53 10000 non-null float64
56 tfidf_54 10000 non-null float64
57 tfidf_55 10000 non-null float64
58 tfidf_56 10000 non-null float64
59 tfidf_57 10000 non-null float64
60 tfidf_58 10000 non-null float64
61 tfidf_59 10000 non-null float64
62 tfidf_60 10000 non-null float64
63 tfidf_61 10000 non-null float64
64 tfidf_62 10000 non-null float64
65 tfidf_63 10000 non-null float64
66 tfidf_64 10000 non-null float64
67 tfidf_65 10000 non-null float64
68 tfidf_66 10000 non-null float64
69 tfidf_67 10000 non-null float64
70 tfidf_68 10000 non-null float64
71 tfidf_69 10000 non-null float64
72 tfidf_70 10000 non-null float64
73 tfidf_71 10000 non-null float64
74 tfidf_72 10000 non-null float64
75 tfidf_73 10000 non-null float64
76 tfidf_74 10000 non-null float64
77 tfidf_75 10000 non-null float64
78 tfidf_76 10000 non-null float64
79 tfidf_77 10000 non-null float64
80 tfidf_78 10000 non-null float64
81 tfidf_79 10000 non-null float64
dtypes: float64(80), int64(2)
memory usage: 6.3 MB
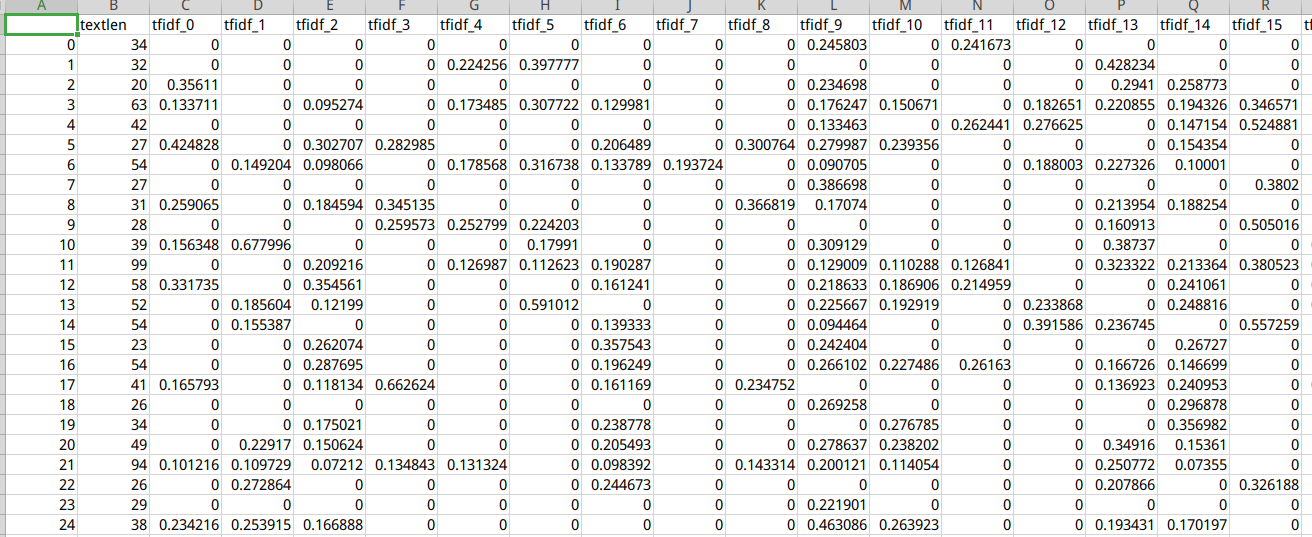
4.2 训练label集
train_data_label= pd.read_csv('./data/all_train_data_label.csv')print(train_data_label.info())
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 18 columns):
Column Non-Null Count Dtype
0 f0 10000 non-null int64
1 f1 10000 non-null int64
2 f2 10000 non-null int64
3 f3 10000 non-null int64
4 f4 10000 non-null int64
5 f5 10000 non-null int64
6 f6 10000 non-null int64
7 f7 10000 non-null int64
8 f8 10000 non-null int64
9 f9 10000 non-null int64
10 f10 10000 non-null int64
11 f11 10000 non-null int64
12 f12 10000 non-null int64
13 f13 10000 non-null int64
14 f14 10000 non-null int64
15 f15 10000 non-null int64
16 f16 10000 non-null int64
17 f17 10000 non-null int64
dtypes: int64(18)
memory usage: 1.4 MB
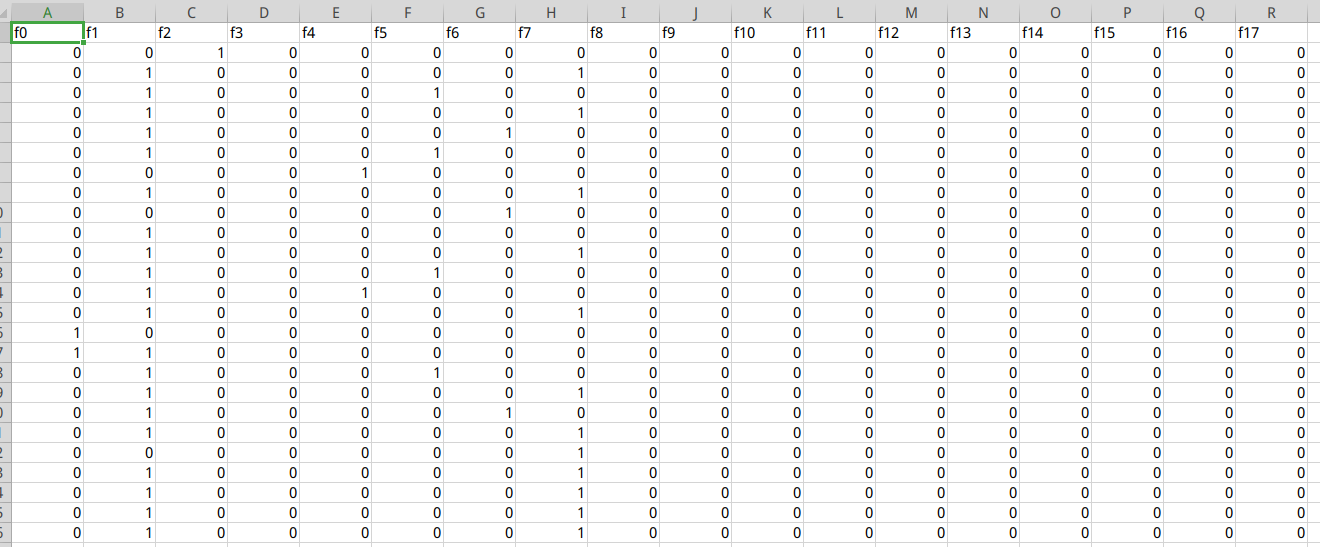
4.4 测试样本集
test_data_sample = pd.read_csv('./data/all_test_data_sample.csv')print(test_data_sample.info())
RangeIndex: 3000 entries, 0 to 2999
Data columns (total 82 columns):
Column Non-Null Count Dtype
0 Unnamed: 0 3000 non-null int64
1 textlen 3000 non-null int64
2 tfidf_0 3000 non-null float64
3 tfidf_1 3000 non-null float64
4 tfidf_2 3000 non-null float64
5 tfidf_3 3000 non-null float64
6 tfidf_4 3000 non-null float64
7 tfidf_5 3000 non-null float64
8 tfidf_6 3000 non-null float64
9 tfidf_7 3000 non-null float64
10 tfidf_8 3000 non-null float64
11 tfidf_9 3000 non-null float64
12 tfidf_10 3000 non-null float64
13 tfidf_11 3000 non-null float64
14 tfidf_12 3000 non-null float64
15 tfidf_13 3000 non-null float64
16 tfidf_14 3000 non-null float64
17 tfidf_15 3000 non-null float64
18 tfidf_16 3000 non-null float64
19 tfidf_17 3000 non-null float64
20 tfidf_18 3000 non-null float64
21 tfidf_19 3000 non-null float64
22 tfidf_20 3000 non-null float64
23 tfidf_21 3000 non-null float64
24 tfidf_22 3000 non-null float64
25 tfidf_23 3000 non-null float64
26 tfidf_24 3000 non-null float64
27 tfidf_25 3000 non-null float64
28 tfidf_26 3000 non-null float64
29 tfidf_27 3000 non-null float64
30 tfidf_28 3000 non-null float64
31 tfidf_29 3000 non-null float64
32 tfidf_30 3000 non-null float64
33 tfidf_31 3000 non-null float64
34 tfidf_32 3000 non-null float64
35 tfidf_33 3000 non-null float64
36 tfidf_34 3000 non-null float64
37 tfidf_35 3000 non-null float64
38 tfidf_36 3000 non-null float64
39 tfidf_37 3000 non-null float64
40 tfidf_38 3000 non-null float64
41 tfidf_39 3000 non-null float64
42 tfidf_40 3000 non-null float64
43 tfidf_41 3000 non-null float64
44 tfidf_42 3000 non-null float64
45 tfidf_43 3000 non-null float64
46 tfidf_44 3000 non-null float64
47 tfidf_45 3000 non-null float64
48 tfidf_46 3000 non-null float64
49 tfidf_47 3000 non-null float64
50 tfidf_48 3000 non-null float64
51 tfidf_49 3000 non-null float64
52 tfidf_50 3000 non-null float64
53 tfidf_51 3000 non-null float64
54 tfidf_52 3000 non-null float64
55 tfidf_53 3000 non-null float64
56 tfidf_54 3000 non-null float64
57 tfidf_55 3000 non-null float64
58 tfidf_56 3000 non-null float64
59 tfidf_57 3000 non-null float64
60 tfidf_58 3000 non-null float64
61 tfidf_59 3000 non-null float64
62 tfidf_60 3000 non-null float64
63 tfidf_61 3000 non-null float64
64 tfidf_62 3000 non-null float64
65 tfidf_63 3000 non-null float64
66 tfidf_64 3000 non-null float64
67 tfidf_65 3000 non-null float64
68 tfidf_66 3000 non-null float64
69 tfidf_67 3000 non-null float64
70 tfidf_68 3000 non-null float64
71 tfidf_69 3000 non-null float64
72 tfidf_70 3000 non-null float64
73 tfidf_71 3000 non-null float64
74 tfidf_72 3000 non-null float64
75 tfidf_73 3000 non-null float64
76 tfidf_74 3000 non-null float64
77 tfidf_75 3000 non-null float64
78 tfidf_76 3000 non-null float64
79 tfidf_77 3000 non-null float64
80 tfidf_78 3000 non-null float64
81 tfidf_79 3000 non-null float64
dtypes: float64(80), int64(2)
memory usage: 1.9 MB

若有收获,就点个赞吧
0 人点赞
