1 概述
任务目标:人脸表情识别
数据来源:kaggle
模型设计:Lenet7和CliqueNet
度量标准:准确率
实验分类:8类(愤怒 恶心 害怕 快乐 悲伤 惊讶 蔑视 面无表情)
2 数据集
2.1 数据集下载
由Microsoft对kaggle提出的数据集进行重新标注的数据集
数据集下载
2.2 数据规模
训练集:测试集:验证集 = 8:1:1
1P = 48 * 48 = 2304像素 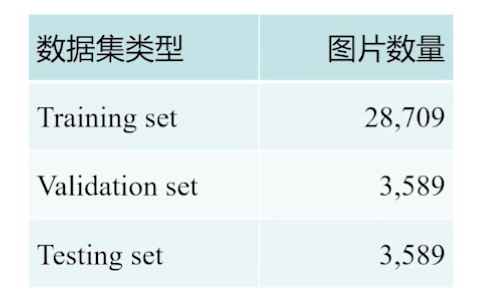
2.3 数据格式
-csv -3个属性:Label Pixels Usage
实际内容:人脸(灰度)
8中表情:愤怒 恶心 害怕 快乐 悲伤 惊讶 蔑视 面无表情(No Expression)
面部基本居中,大小相似
预处理数据下载

3 模型说明
3.1 Lenet7
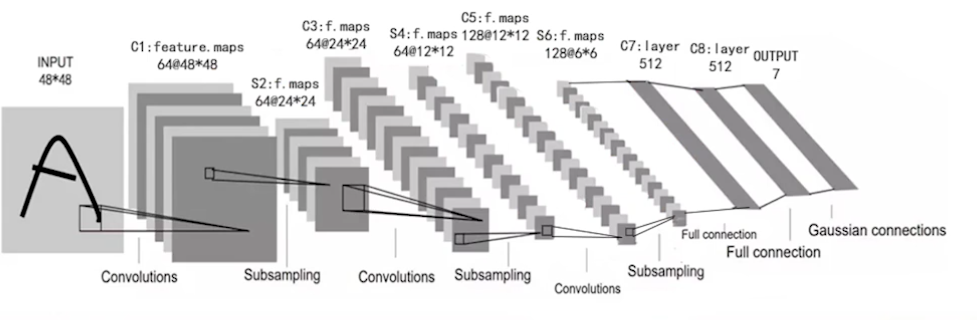
Lenet7原来的网络使用两层卷积层和两层池化层,在实践中增大了模型深度,更好的适应当前数据特征
增加一个卷积和池化层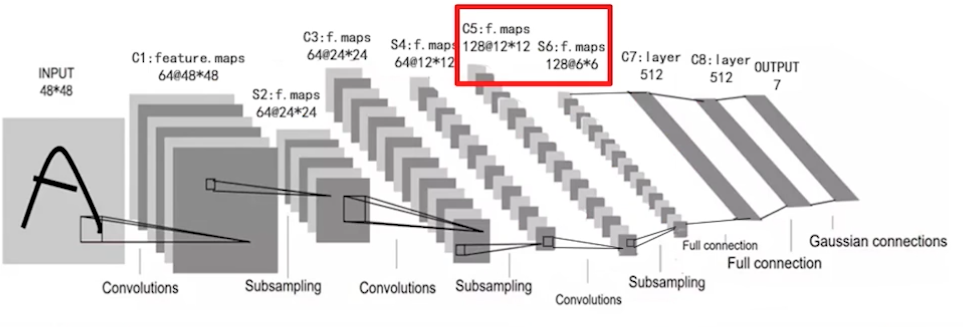
增加一层全连接层。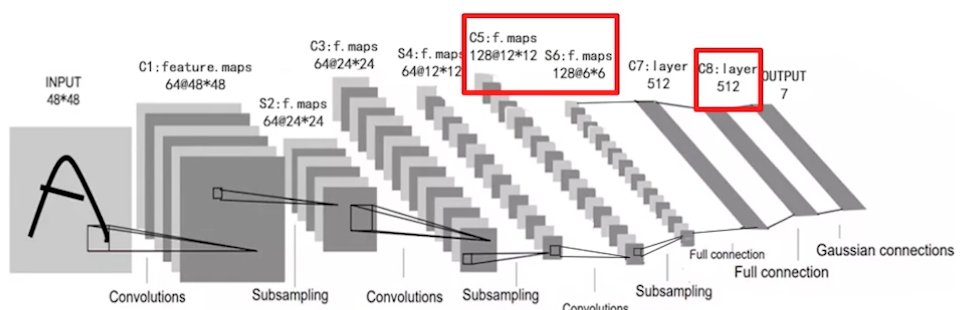
3.2 CliqueNet
(1)简介
由DenseNet启发
各Layer间双向连接
stage1: 浅层—>高层特征
stage2: 近层更新远层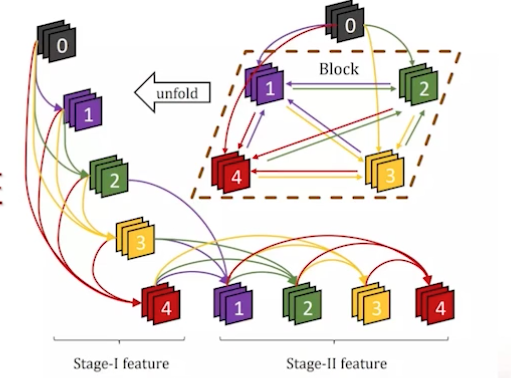
(2)网络结构
本项目中由于数据集复杂程度不高,使用l三个block,每个block提取特征进行预测。浅层提取到了细节特征,深层提取到了全局信息。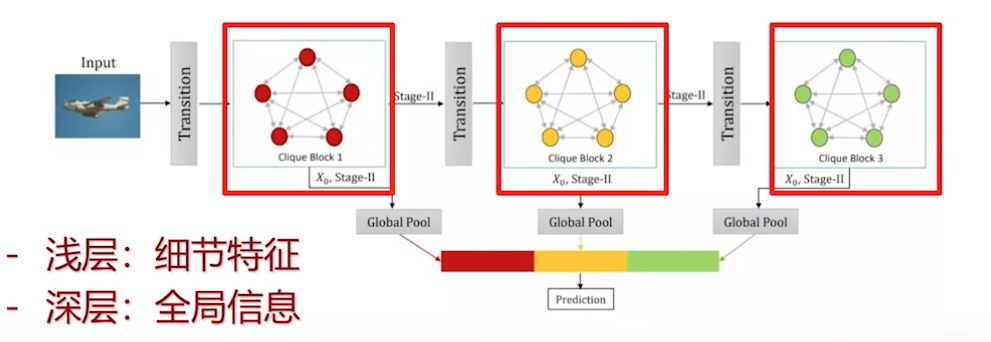
此外在网络中使用Transition模块,使用channel-wise attention来给不同的channel赋予不同的权重。
4 代码分析
4.1 cliquenet.py中forward函数
其中block模块主要对一维和高维图像特征进行提取
transition模块主要通过channel-wise attention机制对cannel的结构进行优化,以使得channel都获得所有维度的特征信息,有益于后面过程的学习。
# 定义了cliquenet的前向传播函数def forward(x, train=True, regularizer=None):# 得到之后进行卷积的卷积核张量,输入channel为1,输出channel为64,kernel size为3w = get_weight([3, 3, 1, 64], 0.1, regularizer)# 先进行一次卷积,步长为2,使得feature map维度减半,使得模型提取到浅层特征x = conv2d(x, w, 2)# 对数据进行批归一化,加快网络训练,减轻梯度消失x = bn(x, train)# 使用ReLU激活函数使得模型非线性x = tf.nn.relu(x)# 对数据进行最大池化,使得feature map的维度减半x = tf.nn.max_pool(x, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME')## block1# 将数据送入clique block,block内每一个结点的channel数设为36,一个block内除输入结点外有5个结点x, feature1 = clique_block(x, regularizer, 64, 36, 3, 5, train)# 对第一个block提取到的特征信息进行global poolingfeature1 = tf.nn.avg_pool(feature1, ksize=[1, 12, 12, 1], strides=[1, 12, 12, 1], padding='SAME')# 将上一层的五个更新后结点作为输入,经过transition调整feature map的维度,并利用attention强化特征信息更优的channel,使得下一个block可以更好地利用前层特征信息x = transition(x, regularizer, 180, 180, 12, train)## block 2# 将数据送入clique block,block内每一个结点的channel数设为36,一个block内除输入结点外有5个结点x, feature2 = clique_block(x, regularizer, 180, 36, 3, 5, train)# 对第二个block提取到的特征信息进行global poolingfeature2 = tf.nn.avg_pool(feature2, ksize=[1, 6, 6, 1], strides=[1, 6, 6, 1], padding='SAME')# 将上一层的五个更新后结点作为输入,经过transition调整feature map的维度,并利用attention强化特征信息更优的channel,使得下一个block可以更好地利用前层特征信息x = transition(x, regularizer, 180, 180, 6, train)## block3# 将数据送入clique block,block内每一个结点的channel数设为36,一个block内除输入结点外有5个结点_, feature3 = clique_block(x, regularizer, 180, 36, 3, 5, train)# 对第三个block提取到的特征信息进行global poolingfeature3 = tf.nn.avg_pool(feature3, ksize=[1, 3, 3, 1], strides=[1, 3, 3, 1], padding='SAME')# 将不同层间获取的不同特征进行融合,浅层的特征包含更多的细节信息,而深层特征则包含更多的全局信息out = tf.concat([feature1, feature2, feature3], axis=3)# 将张量转换为一个长向量,以用于之后的全连接层x = tf.reshape(out, [-1, 964])# 将向量输入全连接层,从而输出对每一个分类的预测分数x = fc(x, 964, 7, 0.01, regularizer)# 返回该神经网络的预测结果return x
4.2 cliquenet.py中stage1和stage2函数
stage1的公式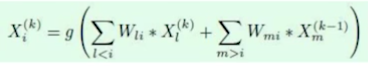
代码结构是
layer1 = encoding(input)
layer2 =encoding(layer1,input)
layer3 = encoding(layer2,input)
…
layer5 = encoding(layer4,input)
因此layer5中存在提取的高维提取特征,并且有很多重复的获取的低维特征。以使得低维和高维的特征共同被利用,加强了information flow,能有效避免梯度消失。
# 定义了stage1阶段def stage1(x0, w0, w, in_channel, filters, layers=5, train=True):# 使用输入结点对每一个之外的结点进行初始化for i in range(layers):# 如果是第一个结点if i == 0:# 就取w0中的第一个张量作为连接输入结点与第一个结点的卷积核weight = w0[i]# 第一个结点在stage1只与输入结点相连接data = x0# 如果不是第一个结点else:# 就取w0中对应的结点以及w中对应的结点拼成之后使用的卷积核weight = tf.concat([w0[i]] + [w[4 * num + i - 1] for num in range(i)], axis=2)# 使用拼出的卷积核与前面的结点生成一个新的结点x = conv2d(data, weight)# 对数据进行批归一化,加快网络训练,减轻梯度消失x = bn(x, train)# 使用ReLU激活函数使得模型非线性x = tf.nn.relu(x)# 使用dropout随机使部分结点归零,从而使得模型不易过拟合x = dropout(x, train)# 将已经生成的结点concat在一起用于生成下一个结点data = tf.concat([data, x], axis=3)# 除去输入结点与第一个结点(第一个结点在stage2的第一步即需要被更新,因此不需要传入下一阶段)_, x = tf.split(data, [in_channel + filters, filters * (layers - 1)], axis=3)# 将得到的后面若干个结点传入stage2return x
stage2:迭代更新layers
layer1 = encoding(layer2~5)
layer2 =encoding(layer1,3,4,5)
layer3 = encoding(layer1,2,4,5)
…
layer5 = encoding(layer1,2,3,4)
# 定义了stage2模块def stage2(x, w, in_channel, filters, layers=5, train=True):# 对block内每一个结点进行更新for i in range(layers):# 取w中对应的结点拼成卷积核weight = tf.concat([w[4 * num + i - 1] for num in range(i)] + [w[4 * num + i] for num in range(i + 1, layers)], axis=2)# 使用拼出的卷积核与最近更新的结点更新最早的结点data = conv2d(x, weight)# 对数据进行批归一化,加快网络训练,减轻梯度消失data = bn(data, train)# 使用ReLU激活函数使得模型非线性data = tf.nn.relu(data)# 使用dropout随机使部分结点归零,从而使得模型不易过拟合data = dropout(data, train)# 若不为更新最后一个结点if i != layers - 1:# 则将更新最早的结点去除_, x = tf.split(x, [filters, filters * (layers - 2)], axis=3)# 将最新更新的结点同其他结点concat在一起,对于非最后结点相当于替换最早更新的结点x = tf.concat([data, x], axis=3)# 返回经过stage2后的所有经过更新的结点return x
4.3 cliquenet.py中transition函数
将layer在channel层面做attention,使得整个layer都学习到上下文的信息。
# 定义了在多个block之间的转换模块def transition(x, regularizer, in_channel, out_channel, size, train, use_attention=True):# 得到之后进行的1✖1卷积的卷积核张量,输入channel与输出channel为给定值,在该网络中由于较浅,因此暂不使用compression机制,输入channel与输出channel数相等w = get_weight([1, 1, in_channel, out_channel], 0.1, regularizer)# 根据上述卷积核进行卷积,步长为1,使得feature map维度不变x = conv2d(x, w, 1)# 对数据进行批归一化,加快网络训练,减轻梯度消失x = bn(x, train)# 使用ReLU激活函数使得模型非线性x = tf.nn.relu(x)# 使用dropout随机使部分结点归零,从而使得模型不易过拟合x = dropout(x, train)# 选择是否使用attention机制,这里采用了channel-wise的attention机制来在转化过程赋予不同channel不同权重,从而使得下一个block的学习效果更好if use_attention:# 对数据进行global pooling,从而对于对于每一个channel得到一个值attention = tf.nn.avg_pool(x, ksize=[1, size, size, 1], strides=[1, size, size, 1], padding='SAME')# 将得到的每一个张量转换为一个长度为channel数的长向量attention = tf.reshape(attention, [-1, out_channel])# 将获得的权重输入一个全连接层,从而对权重进行学习attention = fc(attention, out_channel, out_channel // 2, 0.01, regularizer)# 使用ReLU激活函数使得attention的学习模块非线性attention = tf.nn.relu(attention)# 将获得的权重输入一个全连接层,从而对权重进行更深的学习attention = fc(attention, out_channel // 2, out_channel, 0.01, regularizer)# 使用sigmoid激活函数使得学习到的权重处于0-1的范围内attention = tf.sigmoid(attention)# 增大张量维度以方便数据与attention的权重的相乘attention = tf.expand_dims(attention, 1)# 增大张量维度以方便数据与attention的权重的相乘attention = tf.expand_dims(attention, 1)# 将学习到的channel-wise attention权重分别乘以各自的channelx = tf.multiply(x, attention)# 对数据进行最大池化,使得feature map的维度减半,使得下一个block可以学习到更深层的信息x = tf.nn.avg_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')# 返回经过transition转换后的数据,用于传入下一个blockreturn x
5 结果分析
5.1 使用cliqueNet网络优点
增强information flow
减少内存
加速训练
避免网络退化
保证实时性
5.2 参数优化
进行了数据增强
使用了Validation调整优化器与超参数
比较了Adam、Momentum、SGD优化器,其中Momentum收敛较慢,SGD容易梯度消失。最终选择Adam优化器
Dropout = 0.95
5.3 实验环境
操作系统:Ubuntu 16.04LTS
GPU:GTX 1080TI
Python版本: Python3.5
TensorFlow版本:1.11.0
5.4 模型效果
fer2013 Rank最好成绩是0.71。以下是实验结果,最高准确率只有0.653.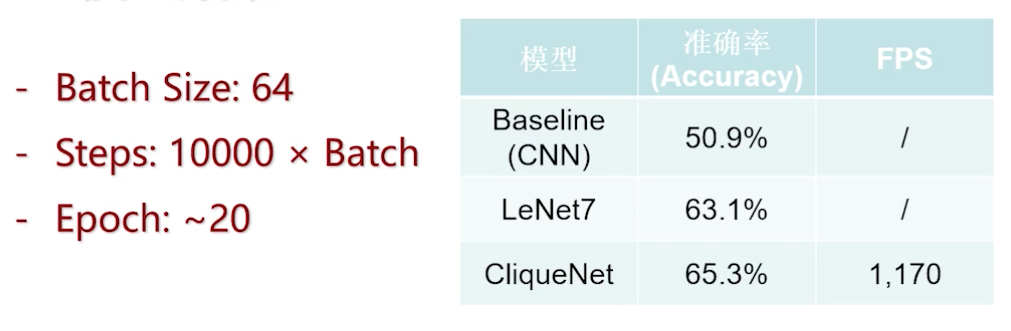
真实数据测试如下,比如周星驰图片中的泪光不够明显,影响了模型的预测结果,得出结论:如何增加标志性特征的对比度是非常重要的。
以下是表情包的测试,图片中没有一个标准的人脸形状时,模型的准确率也不高。

5.5 总结
通过预训练的方式来找到较好的收敛特征。fine-tune:增光数据集上学习率较大的coarse预训练
使用图像分割的方式,矫正面部位置
6 源码下载

若有收获,就点个赞吧
0 人点赞
