1 简介
图像风格融合与快速迁移分为风格融合和风格快速迁移两步
B站图像风格融合与快速迁移讲解视频
1.1 图像风格快速迁移
将一个图像的风格迁移到另一张图片上。
原始图像风格迁移技术与快速图像风格迁移技术对比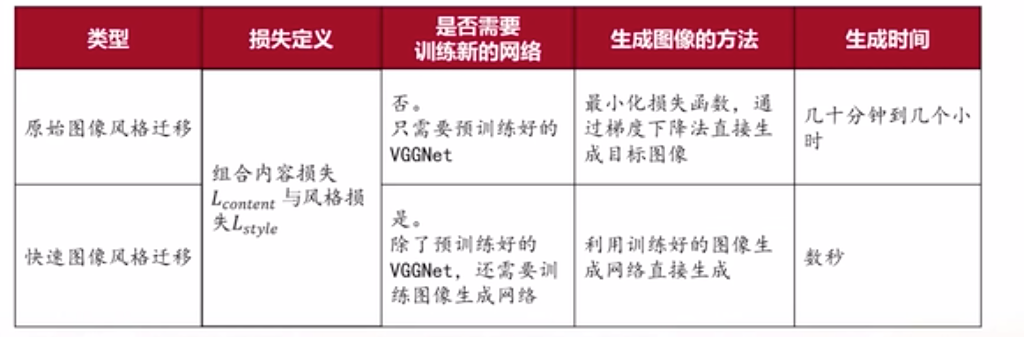
1.2 图像风格融合
是将多种风格的图像进行融合后,迁移到一张图片上。如下所示,生成了黄蓝色图像且具有特殊纹理的图片。
1.3 图像风格融合与快速迁移
是对于给定的多个风格图像和对应的风格标签,训练一个图像生成模型,在这个模型中,多个风格共享模型结构和参数,大大的节约训练时间和减小了模型大小。
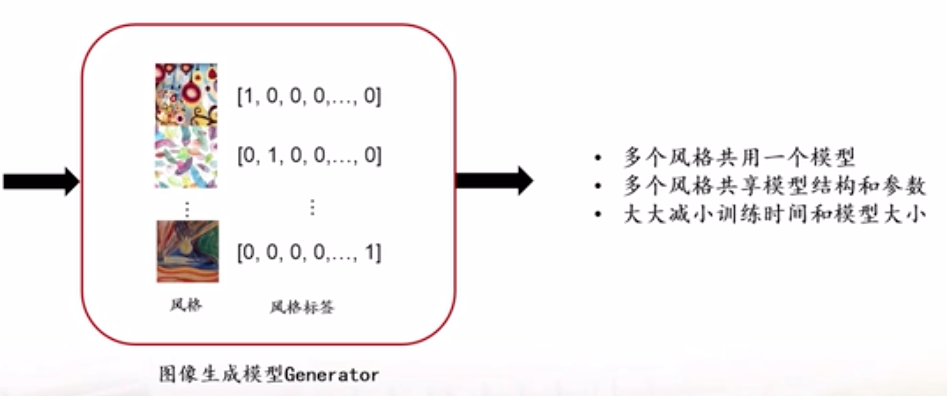
在图片生成过程中,可以通过查看训练图片的生成效果来决定是否停止训练。
2 数据集
采用MSCOCO(Common Objects in Context)数据集2014版本
(1)原用于图像识别领域,包含20G的图像文件和500M的标签数据
(2)仅使用其图像文件,共82783张
通过筛选选择了20张具有明显风格色彩的图片作为模型训练的风格图片。包括油画、水墨画、素描、动漫等
3 模型结构
主要包括图像生成网络和损失函数网络。内容图片通过图像生成网络输出生成图片,生成图片与内容图片、风格图片通过损失网络计算总损失。通过最小化总损失函数对图像生成网络进行梯度下降,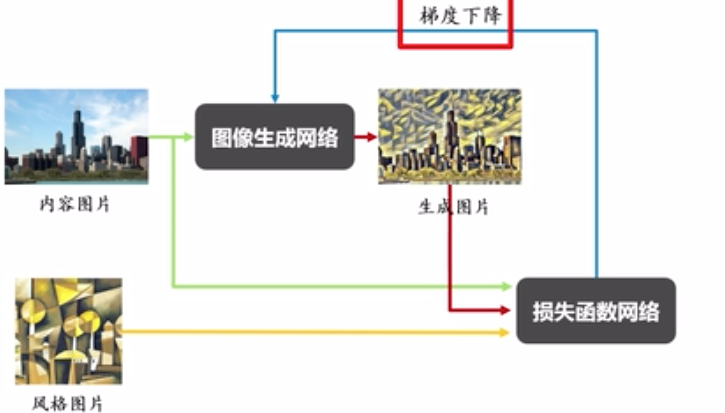
3.1 损失函数网络
来源于Gatys 2015年提出的风格迁移损失函数,就是前面提到的原始图像生成模型,生成速度慢。该网络中输入图片在深层卷积神经网络不同中间层的输出可以看成作是其风格特征和内容特征。取内容图片和生成图片的内容特征的差作为内容损失函数。取风格图片和生成图片的风格特征的差作为风格损失函数。内容损失函数与风格损失函数加权综合就得到风格迁移的总损失函数。在该实验中,损失函数使用了Gatys论文中的VGG16损失函数网络,取VGG16第2层卷积特征来计算内容损失,取1、2、3、4层的卷积特征来计算风格损失.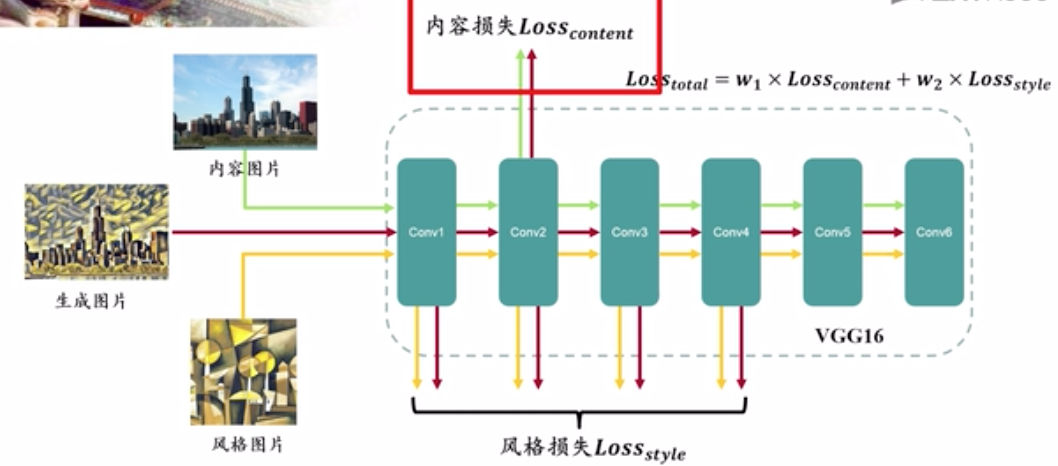
3.2 图像生成网络
(1)DCGAN经典模型简介
DCGAN是图像生成网络中的经典网络。是把一个正态分布向量z作为输入,经过多次反卷积后就会变成一张图片,这张图片和真实输入的图片如果能在判别器D下得到几乎相同的值,我们就可以认为图片几乎是真实的。在经过反复训练后,任意一个白噪声经过生成器G后,就可以生成一张几乎真实的图片。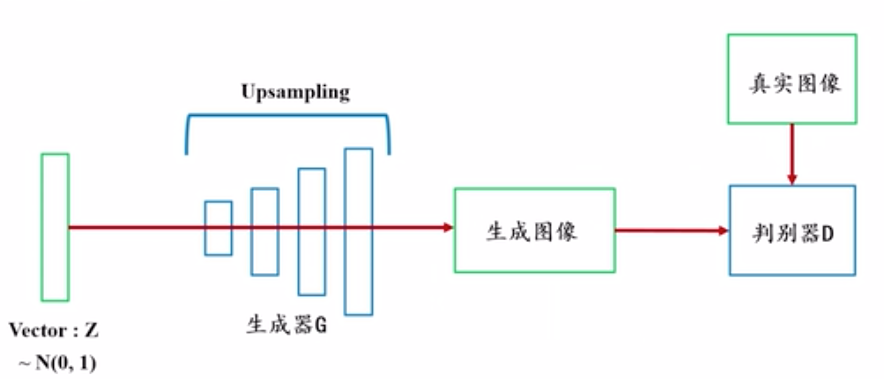
(2)本实验的图像生成网络模型
在该实验中,图像生成网络使用了DCGAN生成器的上采样,具体来说,实现的生成器是一个图到图的过程。对于输入的内容图片首先进行下采样,也就是通过卷积进行特征提取,接着是5个残差网络块,然后是上采样,最后是一个卷积层和归一化后以sigmoid函数收尾,并将目标缩放到(0,255)内从而生成图片。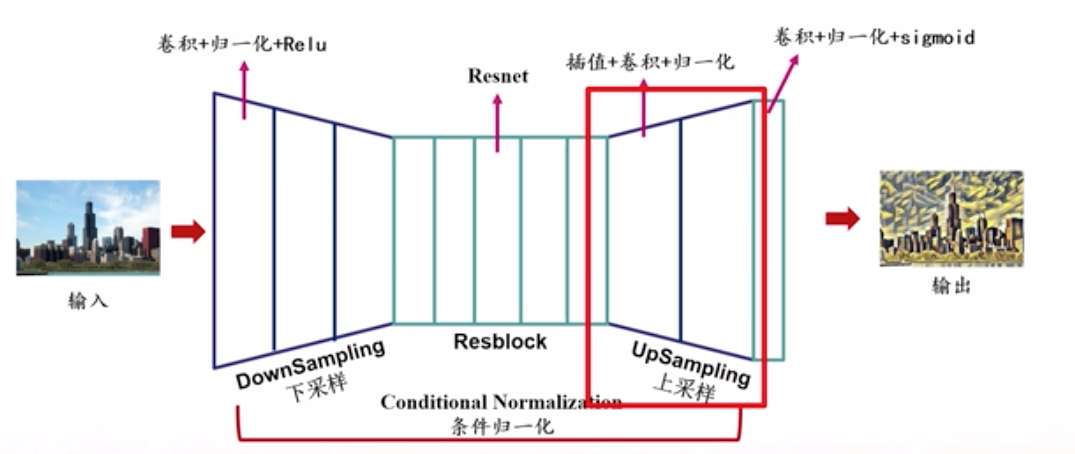
起哄下采样包括卷积核归一化以及Rele激活函数,上采样包括两次的插值算法、卷积和归一化。中间涉及的残差网络如下图。主要特点是跨卷积层做加法操作,目的是为了避免梯度消失。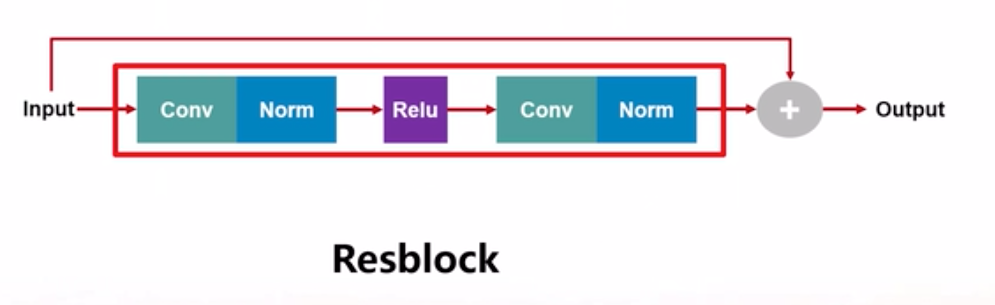
(3)融合的关键—条件归一化
Dumoulin在2017年的论文中使用了条件归一化,把输入分布映射到服从beta、gamma的正态分布上。对上述生成器网络的每一层,都加入条件归一化,并将beta、gamma当做可训练的变量,不同的风格共享网络结构和卷积参,但是使用不同的beta、gamma。图像风格的融合其实就是对不同的beta、gamma的加权融合。
(4)参考文献
4 代码讲解
4.1 代码结构
(1)generateds.py
将MSCOCO数据集经过裁剪、resize等预处理后,制作成tfrecords训练集;并提供训练集和风格图片的读取方法
(2)forward.py
实现了前向传播过程,定义了网络的核心结构。主要分为三大部分,图像生成网络、损失函数网络及loss函数的计算
(3)backward.py
实现了反向传播过程,调用了generateds进行数据的读取,调用forward函数进行前向传播、损失函数计算,使用adam优化器进行损失函数最小化,并提供模型的断点续训功能。
(4)test.py
实现图像融合与迁移,用于输入内容图片,制定4中风格图片,通过调用forward函数,进行风格融合后,即可得到25张不同风格不同权重融合后的图片。
(5)app.py
应用程序调用test.py的接口文件
generateds forward backward test 和app
4.2 核心代码
forward.py文件
(1)图像生成网络
def forward(inputs, weight):# 预处理'BGR'->'RGB',同时减去vgg_mean,以契合"vgg"模型。inputs = tf.reverse(inputs, [-1]) - np.array([103.939, 116.779, 123.68])# 3层卷积 ,每次卷积后均 +条件归一化并使用rule激活函数,也就是三次 downsample 操作inputs = conv("conv1", inputs, 9, 3, 32, 1) # 卷积inputs = conditional_normalization(inputs, "cin1", weight) # 条件归一化inputs = tf.nn.relu(inputs) # reluinputs = conv("conv2", inputs, 3, 32, 64, 2)inputs = conditional_normalization(inputs, "cin2", weight)inputs = tf.nn.relu(inputs)inputs = conv("conv3", inputs, 3, 64, 128, 2)inputs = conditional_normalization(inputs, "cin3", weight)inputs = tf.nn.relu(inputs)# 5层resBlockinputs = res_block("res1", inputs, 3, 128, 128, weight)inputs = res_block("res2", inputs, 3, 128, 128, weight)inputs = res_block("res3", inputs, 3, 128, 128, weight)inputs = res_block("res4", inputs, 3, 128, 128, weight)inputs = res_block("res5", inputs, 3, 128, 128, weight)# 2层upsamplinginputs = upsampling("up1", inputs, 128, 64, weight)inputs = upsampling("up2", inputs, 64, 32, weight)# 最后一层卷积将channel限制在3inputs = conv("last", inputs, 9, 32, 3, 1)inputs = conditional_normalization(inputs, "cinout", weight)# 并使用255* sigmoid函数保证结果在 ( 0,255 ) 内inputs = tf.nn.sigmoid(inputs) * 255return inputs
(2)归一化操作
在实验中beta gamma矩阵都是20*3
训练时,传入一个one-hot编码的weight。weight代表两层含义,第一我们选择了这个风格,并且该风格的权重为1。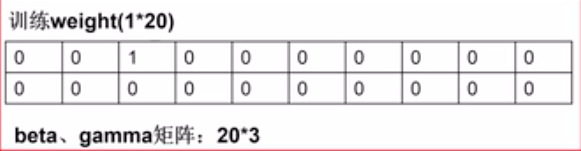
在测试时,选择四个风格,那就有四个位置上有权重。且权重都是0.25。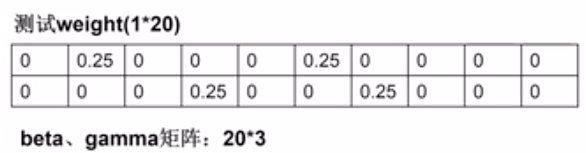
这个conditional_normalization操作贯穿了图像生成网络的每一层,所以图像风格融合和快速迁移是一个整体,而不是割裂开来的,是一个边生成变融合的过程。
def conditional_normalization(x, scope_bn, weight=None):# 获取beta、gamma参数变量beta_matrix = tf.get_variable(name=scope_bn + 'beta',shape=[weight.shape[-1], x.shape[-1]],initializer=tf.constant_initializer([0.]),trainable=True) # label_nums x Cgamma_matrix = tf.get_variable(name=scope_bn + 'gamma',shape=[weight.shape[-1], x.shape[-1]],initializer=tf.constant_initializer([1.]),trainable=True) # label_nums x C# 根据输入权重获取instance normalization beta、gamma值# 在train过程当中weight为one hot编码用于抽取当前训练风格beta、gamma# 在test过程当中weight可以融合多个风格的参数,从而达到特征融合效果(具体可参考上述论文)beta = tf.matmul(weight, beta_matrix)gamma = tf.matmul(weight, gamma_matrix)# 获取单个feature map上mean和variance用作instance normalizationmean, var = tf.nn.moments(x, axes=[1, 2], keep_dims=True)# 按照beta、gamma做归一化x = tf.nn.batch_normalization(x, mean, var, beta, gamma, 1e-10)return x
(3)损失函数网络
使用的是训练好的VGG16.VGGNet定义网络的结构,我们只计算到了第四层卷积,因为在此实验中最多只需要第四层卷积的特征。在每一层卷积之后,都会将其层数以及对应的特征存在字典F中。供之后的内容损失和风格损失时进行提取。
def vggnet(inputs, vgg_path):# VGG16卷积操作def vgg_conv(inputs, w, b):# 卷积函数,inputs:输入,卷积核,步长,前后形状相同return tf.nn.conv2d(inputs, w, [1, 1, 1, 1], "SAME") + b# VGG16池化操作def vgg_max_pooling(inputs):# 池化函数:输入,池化窗口大小,滑动步长,前后形状return tf.nn.max_pool(inputs, [1, 2, 2, 1], [1, 2, 2, 1], "SAME")inputs = tf.reverse(inputs, [-1]) - np.array([103.939, 116.779, 123.68]) # 处理输入图片para = np.load(vgg_path + "vgg16.npy", encoding="latin1").item() # 从vgg模型路径获得vgg模型F = {} # 定义返回值为字典Finputs = vgg_conv(inputs, para["conv1_1"][0], para["conv1_1"][1]) # 第一层卷积提取特征inputs = tf.nn.relu(inputs) # 激活函数relu,即将矩阵中每行的非最大值置0。inputs = vgg_conv(inputs, para["conv1_2"][0], para["conv1_2"][1])inputs = tf.nn.relu(inputs)F["conv1_2"] = inputsinputs = vgg_max_pooling(inputs) # 池化inputs = vgg_conv(inputs, para["conv2_1"][0], para["conv2_1"][1]) # 第二层卷积提取特征inputs = tf.nn.relu(inputs) # 激活函数reluinputs = vgg_conv(inputs, para["conv2_2"][0], para["conv2_2"][1])inputs = tf.nn.relu(inputs)F["conv2_2"] = inputsinputs = vgg_max_pooling(inputs) # 池化inputs = vgg_conv(inputs, para["conv3_1"][0], para["conv3_1"][1]) # 第三层卷积提取特征inputs = tf.nn.relu(inputs) # relu激活函数inputs = vgg_conv(inputs, para["conv3_2"][0], para["conv3_2"][1])inputs = tf.nn.relu(inputs)inputs = vgg_conv(inputs, para["conv3_3"][0], para["conv3_3"][1])inputs = tf.nn.relu(inputs)F["conv3_3"] = inputsinputs = vgg_max_pooling(inputs) # 池化inputs = vgg_conv(inputs, para["conv4_1"][0], para["conv4_1"][1]) # 第四层卷积提取特征inputs = tf.nn.relu(inputs) # relu激活函数inputs = vgg_conv(inputs, para["conv4_2"][0], para["conv4_2"][1])inputs = tf.nn.relu(inputs)inputs = vgg_conv(inputs, para["conv4_3"][0], para["conv4_3"][1])inputs = tf.nn.relu(inputs)F["conv4_3"] = inputsreturn F
(4)内容损失函数
使用的是内容图像和生成图像的第二层卷积特征来计算l2损失函数。
def get_content_loss(content_img, target_img):return tf.nn.l2_loss(content_img["conv2_2"] - target_img["conv2_2"]) * 2 /tf.cast(tf.size(content_img["conv2_2"]),dtype=tf.float32)
(5)风格损失函数
用到了Gram矩阵,是用来衡量风格特征的一种方法,计算方法是矩阵乘以其转置矩阵。在风格损失函数中分别提取1、2、3、4层的卷积特征,分别计算每层卷积特征的Gram矩阵。然后计算风格图像和生成图像gram矩阵的l2损失函数。最后加总得到最后的风格损失。
def get_style_loss(style_img, target_img):# 声明一个字典layers = ["conv1_2", "conv2_2", "conv3_3", "conv4_3"]# 初始化lossloss = 0for layer in layers:# 取style_outputstyle_layer = style_img[layer]style_gram = get_gram_matrix(style_layer)# 取target_outputtarget_layer = target_img[layer]target_gram = get_gram_matrix(target_layer)# 计算mseloss += tf.nn.l2_loss(style_gram - target_gram) * 2 / tf.cast(tf.size(target_gram), dtype=tf.float32)return loss
(6)Gram矩阵计算
每一个传进来的卷积特征有四个维度,batch_size、宽、长、通道数。我们只在宽和长两个维度上计算gram。所以先把1和4维度提到最前,然后徐对最后两维做矩阵乘法。
def get_gram_matrix(layer):shape = tf.shape(layer)# 第一维是batch_sizebatch_size = shape[0]# 宽width = shape[1]# 长height = shape[2]# 通道数channel_num = shape[3]# 只对 第二三维度进行点乘,因此把1,4维度提前filters = tf.reshape(layer, tf.stack([batch_size, -1, channel_num]))# 点乘得到grams矩阵, 仅在维度宽和长上做点乘grams = tf.matmul(filters, filters, transpose_a=True) / tf.to_float(width * height * channel_num)return grams
backward.py文件
定义了反向传播过程,也就是训练过程。首先是对内容图像和风格图像定义了两个占位符,然后定义训练风格的标签为1*20的向量,采用One-hot的编码方式,然后将此内容图片和标签传入网络,生成我们需要的目标图像。
之后目标图像和内容图像、风格图像均通过损失函数网络vggnet进行特征提取,之后便是定义损失函数的计算。分别计算内容损失函数和风格损失函数,并加权得到总损失函数。
之后定义训练轮数,使用adam优化器最小化损失函数。
def backward(img_h=args.IMG_H, img_w=args.IMG_W, img_c=args.IMG_C, style_h=args.STYLE_H, style_w=args.STYLE_W,c_nums=args.LABELS_NUMS, batch_size=args.BATCH_SIZE, learning_rate=args.LEARNING_RATE,content_weight=args.CONTENT_WEIGHT, style_weight=args.STYLE_WEIGHT, path_style=args.PATH_STYLE,model_path=args.PATH_MODEL, vgg_path=args.PATH_VGG16, path_data=args.PATH_DATA,dataset_name=args.DATASET_NAME):# 内容图像:batch为2,图像大小为256*256*3content = tf.placeholder(tf.float32, [batch_size, img_h, img_w, img_c])# 风格图像:batch为2,图像大小为512*512*3style = tf.placeholder(tf.float32, [batch_size, style_h, style_w, img_c])# 风格1:训练风格的标签weight = tf.placeholder(tf.float32, [1, c_nums])# 图像生成网络:前向传播target = forward(content, weight)# 生成图像、内容图像、风格图像特征提取vgg_target = vggnet(target, vgg_path)vgg_content = vggnet(content, vgg_path)vgg_style = vggnet(style, vgg_path)# Loss计算# 内容Losscontent_loss = get_content_loss(vgg_content, vgg_target)# 风格Lossstyle_loss = get_style_loss(vgg_style, vgg_target)# 总Lossloss = content_loss * content_weight + style_loss * style_weight# 定义当前训练轮数变量global_step = tf.Variable(0, trainable=False)# 优化器:Adam优化器,损失最小化opt = tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step=global_step)# 读取训练数据content_batch = get_content_tfrecord(batch_size, os.path.join(path_data, dataset_name), img_h)# 实例化saver对象,便于之后保存模型saver = tf.train.Saver()# 开始计时time_start = time.time()with tf.Session() as sess:# 初始化全局变量init_op = tf.global_variables_initializer()sess.run(init_op)# 在路径中查询有无checkpointckpt = tf.train.get_checkpoint_state(model_path)# 从checkpoint恢复模型if ckpt and ckpt.model_checkpoint_path:saver.restore(sess, ckpt.model_checkpoint_path)print('Restore Model Successfully')else:print('No Checkpoint Found')# 开启多线程coord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)# 开始训练,共进行5万轮for itr in range(args.steps):# 计时time_step_start = time.time()# 读取tfrecords训练集,并进行reshape,尺寸为(batch_size*h*w*c)batch_content = sess.run(content_batch)batch_content = np.reshape(batch_content, [batch_size, img_w, img_h, img_c])# 随机选择1个风格图片,并返回风格图片存储矩阵(batch_size*h*w*c,每个h*w*c都相同),y_labels为风格标签batch_style, y_labels = random_select_style(path_style, batch_size, [style_h, style_w, img_c], c_nums)# 喂数据,开始训练sess.run(opt, feed_dict={content: batch_content, style: batch_style, weight: y_labels})step = sess.run(global_step)# 打印相关信息if itr % 100 == 0:# 为之后打印信息进行相关计算[loss_p, target_p, content_loss_res, style_loss_res] = sess.run([loss, target, content_loss, style_loss],feed_dict={content: batch_content,style: batch_style,weight: y_labels})# 连接3张图片(内容图片、风格图片、生成图片)save_img = np.concatenate((batch_content[0, :, :, :],misc.imresize(batch_style[0, :, :, :], [img_h, img_w]),target_p[0, :, :, :]), axis=1)# 打印轮数、总loss、内容loss、风格lossprint("Iteration: %d, Loss: %e, Content_loss: %e, Style_loss: %e" %(step, loss_p, content_loss_res, style_loss_res))# 展示训练效果:打印3张图片,内容图+风格图+风格迁移图Image.fromarray(np.uint8(save_img)).save("save_training_imgs/" + str(step) + "_" + str(np.argmax(y_labels[0, :])) + ".jpg")time_step_stop = time.time()# 存储模型a = 200if itr % a == 0:saver.save(sess, model_path + "model", global_step=global_step)print('Iteration: %d, Save Model Successfully, single step time = %.2fs, total time = %.2fs' % (step, time_step_stop - time_step_start, time_step_stop - time_start))# 关闭多线程coord.request_stop()coord.join(threads)
test.py文件
图像风格融合与迁移
(1)初始化
对测试图片、风格权重向量、生成图片等变量进行初始化。
def __init__(self, stylizer_arg):self.stylizer_arg = stylizer_argself.content = tf.placeholder(tf.float32, [1, None, None, 3]) # 图片输入定义self.weight = tf.placeholder(tf.float32, [1, stylizer_arg.LABELS_NUMS]) # 风格权重向量,用于存储用户选择的风格self.target = forward(self.content, self.weight) # 定义将要生成的图片self.img_path = stylizer_arg.PATH_IMGself.img = Noneself.label_list = Noneself.input_weight = Noneself.img25 = Noneself.img25_4 = Noneself.sess = tf.Session() # 定义一个sessself.sess.run(tf.global_variables_initializer()) # 变量初始化saver = tf.train.Saver() # 定义模型saverckpt = tf.train.get_checkpoint_state(stylizer_arg.PATH_MODEL) # 从模型存储路径中获取模型if ckpt and ckpt.model_checkpoint_path: # 从检查点中恢复模型saver.restore(self.sess, ckpt.model_checkpoint_path)
(2)read_image读取测试图片
因为图片如果太大,生成速度将会非常慢,将其限制在700*700以下,所以进行reshape
def read_image(self):# 读取图像img_input = Image.open(self.img_path).convert('RGB')# 不断对图片进行缩小,直到符合尺寸限制# 若图片太大,生成速度将会非常慢,若需生成原图,可将此段注释掉while img_input.width * img_input.height > 500000:img_input = img_input.resize((int(img_input.width / 1.5), int(img_input.height / 1.5)))# 转成数组self.img = np.array(img_input)
(3)设置风格
将用户选取的四个风格存在tuple中。
def set_style(self):# 将用户选取的4个风格存储在tuple中self.label_list = (self.stylizer_arg.LABEL_1, self.stylizer_arg.LABEL_2,self.stylizer_arg.LABEL_3, self.stylizer_arg.LABEL_4)
(4)set_weight
将风格权重放在一个1*20的向量里
def set_weight(self, weight_dict):# 初始化input_weightself.input_weight = np.zeros([1, self.stylizer_arg.LABELS_NUMS])# 传入权重字典,键为权重编号,键值为权重,并存到input_weight中for k, v in weight_dict.items():self.input_weight[0, k] = v
(5)Stylize函数
调用set_weight函数得到权重向量,然后喂数据,得到风格融合后的图片并保存下来。
def stylize(self, alpha_list=None):# 将风格列表及对应的权重放入字典中weight_dict = dict(zip(self.label_list, alpha_list))self.set_weight(weight_dict)# 打印提示信息print('Generating', self.img_path.split('/')[-1], '--style:', str(self.label_list),'--alpha:', str(alpha_list), )# 进行风格融合与迁移img = self.sess.run(self.target,feed_dict={self.content: self.img[np.newaxis, :, :, :], self.weight: self.input_weight})# 保存单张图片# 直接str(tuple)会产生空格,js无法读取file_name = self.stylizer_arg.PATH_RESULTS + self.img_path.split('/')[-1].split('.')[0] + '_' + str(self.label_list) + '_' + str(alpha_list) + '.jpg'file_name = file_name.replace(' ','')Image.fromarray(np.uint8(img[0, :, :, :])).save(file_name)return img
(6)generate_result函数
是通过一个两层的循环,生成25个权重向量,通过调用sylize函数生成25张融合后的图片。如下表格所示。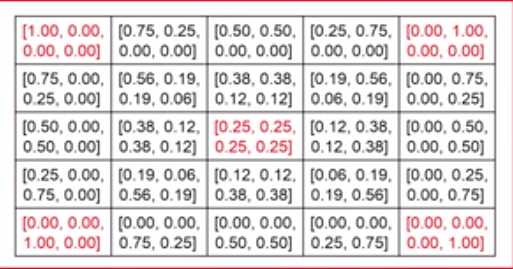
四个直角的向量为四个风格权重分别为1,其他权重为0的权重。中间向量为4个风格权重同时为0.25的权重向量。
def generate_result(self):size = 5i = 0# 按行生成while i < size:# 1、2风格权重之和x_sum = 100 - i * 25.0# 3、4风格权重之和y_sum = i * 25# 1、2风格之和进行五等分,计算权重step值x_step = x_sum / 4.0# 3、4风格之和进行五等分,计算权重step值y_step = y_sum / 4.0# 按列生成j = 0while j < size:# 计算1、2风格的权重ap1 = x_sum - j * x_stepap2 = j * x_step# 计算3风格权重ap3 = y_sum - j * y_stepap4 = j * y_step# 归一化后存到alphas中alphas = (float('%.2f' % (ap1 / 100.0)),float('%.2f' % (ap2 / 100.0)),float('%.2f' % (ap3 / 100.0)),float('%.2f' % (ap4 / 100.0)))# 返回融合后图像img_return = self.stylize(alphas)# array转IMGimg_return = Image.fromarray(np.uint8(img_return[0, :, :, :]))# 将5个图像按行拼接if j == 0:width, height = img_return.sizeimg_5 = Image.new(img_return.mode, (width * 5, height))img_5.paste(img_return, (width * j, 0, width * (j + 1), height))j = j + 1# 将多个行拼接图像,拼接成5*5矩阵if i == 0:img_25 = Image.new(img_return.mode, (width * 5, height * 5))img_25.paste(img_5, (0, height * i, width * 5, height * (i + 1)))i = i + 1# 将5*5矩阵图像的4个角加上4个风格图像,以作对比img25_4 = Image.new(img_25.mode, (width * 7, height * 5))img25_4 = ImageOps.invert(img25_4)img25_4.paste(center_crop_img(Image.open(self.stylizer_arg.PATH_STYLE + str(self.label_list[0] + 1) + '.png')).resize((width, height)),(0, 0, width, height))img25_4.paste(center_crop_img(Image.open(self.stylizer_arg.PATH_STYLE + str(self.label_list[1] + 1) + '.png')).resize((width, height)),(width * 6, 0, width * 7, height))img25_4.paste(center_crop_img(Image.open(self.stylizer_arg.PATH_STYLE + str(self.label_list[2] + 1) + '.png')).resize((width, height)),(0, height * 4, width, height * 5))img25_4.paste(center_crop_img(Image.open(self.stylizer_arg.PATH_STYLE + str(self.label_list[3] + 1) + '.png')).resize((width, height)),(width * 6, height * 4, width * 7, height * 5))img25_4.paste(img_25, [width, 0, width * 6, height * 5])self.img25 = img_25self.img25_4 = img25_4def save_result(self):# 存储5*5图像矩阵self.img25.save(self.stylizer_arg.PATH_RESULTS + self.img_path.split('/')[-1].split('.')[0] + '_' + str(self.label_list) + '_result_25' + '.jpg')self.img25.show()# 存储5*5+4风格图像矩阵self.img25_4.save(self.stylizer_arg.PATH_RESULTS + self.img_path.split('/')[-1].split('.')[0] + '_' + str(self.label_list) + '_result_25_4' + '.jpg')self.img25_4.show()print('Image Matrix Saved Successfully!')def get_image_matrix():# 初始化stylizer0 = Stylizer(args)# 读取图像文件stylizer0.read_image()# 存储风格标签stylizer0.set_style()# 生成融合图片stylizer0.generate_result()# 保存融合图片stylizer0.save_result()# 释放对象del stylizer0# 重置图tf.reset_default_graph()# 主程序def main():get_image_matrix()# 主程序入口if __name__ == '__main__':main()
app.py文件
是网页应用程序调用test.py的接口.其次使用test中定义的syliezer类进行风格融合图片的生成。
# -*- coding: UTF-8 -*-import osfrom .test import *import randomdef deleteResult(path):ls = os.listdir(path)for i in ls:c_path = os.path.join(path, i)if ("jpg" in c_path):os.remove(c_path)def delte(path):ls = os.listdir(path)for i in ls:c_path = os.path.join(path, i)if ("result" in c_path):os.remove(c_path)def main(arg, result_path, data_path, style_path, model_path):# 初始化变量args.LABEL_1 = int(arg[0])args.LABEL_2 = int(arg[1])args.LABEL_3 = int(arg[2])args.LABEL_4 = int(arg[3])args.PATH_IMG = arg[4]args.PATH_RESULTS = result_pathargs.PATH_STYLE = style_pathargs.PATH_MODEL = model_path# 删除之前所产生的图片deleteResult(args.PATH_RESULTS)# 初始化Stylizer类stylizer = Stylizer(args)# 读取图片stylizer.read_image()# 设置风格参数stylizer.set_style()# 产生风格融合图片stylizer.generate_result()# 存储5*5图像矩阵stylizer.img25.save(args.PATH_RESULTS + 'result_25' + str(random.uniform(1, 10)) + '.jpg')# 删除之前所产生的图片delte(data_path)# 存储5*5+4风格图像矩阵url = data_path + "result25" + str(random.uniform(1, 10)) + ".jpg"stylizer.img25_4.save(url)del stylizertf.reset_default_graph()
5 实验环境及源码下载
(1)实验环境:
操作系统:windows10
GPU:GTX 1060
Python版本:python3.6
tensorflow:1.9.0
浏览器Edge
(2)源码下载
项目源码githu

若有收获,就点个赞吧
0 人点赞
