1.马尔可夫决策过程MDP
1.1背景
- 随机变量
 :研究对象是一个或多个随机变量,探索其是一维还是多维、分布函数、类型(连续or离散)、(多维)随机变量之间关系(是否独立)、随机变量数字特征(期望、方差、协方差、矩等)
:研究对象是一个或多个随机变量,探索其是一维还是多维、分布函数、类型(连续or离散)、(多维)随机变量之间关系(是否独立)、随机变量数字特征(期望、方差、协方差、矩等) - 随机过程
 :研究一组特殊的随机变量
:研究一组特殊的随机变量
- 马尔科夫链/过程
 :具备马尔可夫性质的随机过程
:具备马尔可夫性质的随机过程 
- 状态空间模型
 :(HMM, Kalman Filter, Particle Filter)
:(HMM, Kalman Filter, Particle Filter)
 :
:
 :
:
符号说明



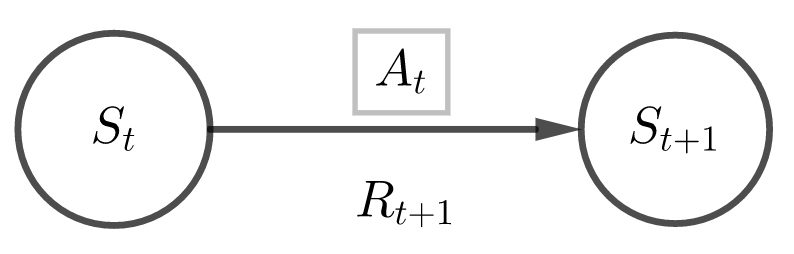
1.2动态特性
MDP是“从与环境的交互中学习来达成目标”这一问题的框架。学习器及决策者称为智能体 ;由代理之外的一切组成的并与代理所交互的事物被称为环境
;由代理之外的一切组成的并与代理所交互的事物被称为环境 。二者持续交互:代理选择动作,环境对动作做出反馈并更新环境,代理希望选择一个最优的动作策略来获得最大化奖励的积累量。
。二者持续交互:代理选择动作,环境对动作做出反馈并更新环境,代理希望选择一个最优的动作策略来获得最大化奖励的积累量。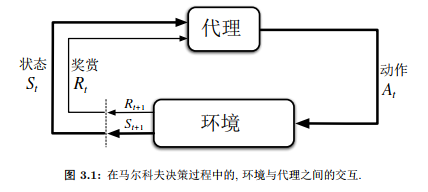
定义:动态函数

注1:这里的 其实也具有随机性,只是在现实中大多数情形下表现并不明显,比如采取了同样的
其实也具有随机性,只是在现实中大多数情形下表现并不明显,比如采取了同样的 和
和 ,
, 可能会取0.8,也有可能会取0.9
可能会取0.8,也有可能会取0.9
注2:动态函数是一个条件概率,满足归一性:
通过状态函数,我们可以计算出任何与环境相关的信息,如:状态转移概率,状态-动作对的期望奖赏、状态-动作-下一状态的期望奖赏。
- 状态转移函数


- 状态-动作期望奖赏


- 状态-动作-下一状态期望奖赏


1.3策略与价值函数
决策函数集
强化学习目的是为了能够通过智能体与环境的交互学习到某种最优的的策略。
定义:策略 是从状态到动作的一个映射,分为确定性策略和随机性策略,
是从状态到动作的一个映射,分为确定性策略和随机性策略,
- 确定性策略:

-
表现度量
为了学习到最优的策略,需要确定一个表现度量,对于强化学习来说,这种度量就是极大化回报。
定义:回报是奖赏序列的某一具体函数 最简单的情况-奖赏之和:

- 未来奖赏在当前值:
 ,其中
,其中 称为折扣因子,决定了未来奖赏的当前值 。
称为折扣因子,决定了未来奖赏的当前值 。

注:由于策略是随机的, 仅仅代表一种可能,并不能充分反映该策略的好坏,因此我们希望能用一个期望回报来作为表现度量。
仅仅代表一种可能,并不能充分反映该策略的好坏,因此我们希望能用一个期望回报来作为表现度量。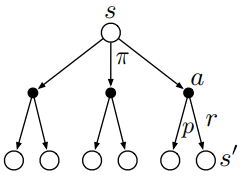
定义:值函数
- 状态值函数:

- 动作值函数:

注:在 里
里 对
对 有约束,而在
有约束,而在 里没有约束。
里没有约束。
二者关系:
- 状态值函数是动作值函数的加权平均:

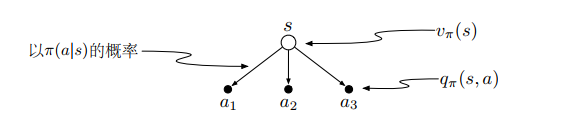
- 动作值函数是状态值函数的加权平均

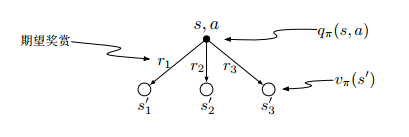
所以,可以推出贝尔曼期望方程



若有收获,就点个赞吧
0 人点赞
