视觉处理信息原理
1981年的诺贝尔将颁发给了David Hubel和Torsten Wiesel,以及Roger Sperry。他们发现了人的视觉系统处理信息是分级的。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
在6.深度学习101文章我们聊到,深度学习仿造人的神经系统,也是分级的。卷积神经网络(CNN,Convolutional Neural Net)是计算机视觉的主流深度神经网络技术,在图像识别和分类领域中取得了非常好的效果。CNN的浅层的神经网络提取横、竖的线条,最深层的神经网络提取整体的人脸。
2013年ImageNet分类任务的冠军ZFNet,首次系统化地对卷积神经网络做了可视化的研究,这些研究结果就支持了上述观点。
- 从Layer 1、Layer 2学习到的特征基本上是颜色、边缘等低层特征;
- Layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;

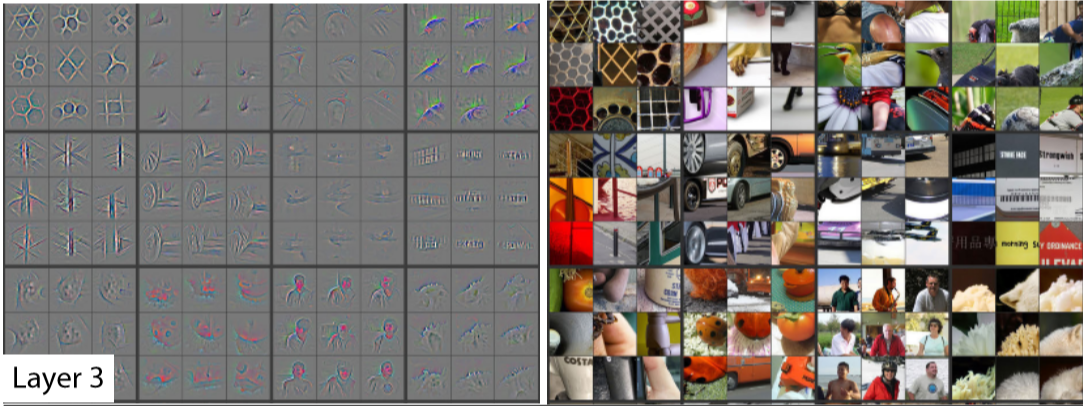
卷积神经网络(CNN)
1.卷积核
卷积网络之所以能工作,完全是卷积核的功劳。卷积核存在于浅层神经网络中,主要的功能是进行边缘特征(类似颜色、横竖)提取。
卷积核的工作原理如下图所示,最左边是图片的信息矩阵,中间是卷积核的矩阵,最右边是卷积运算后的结果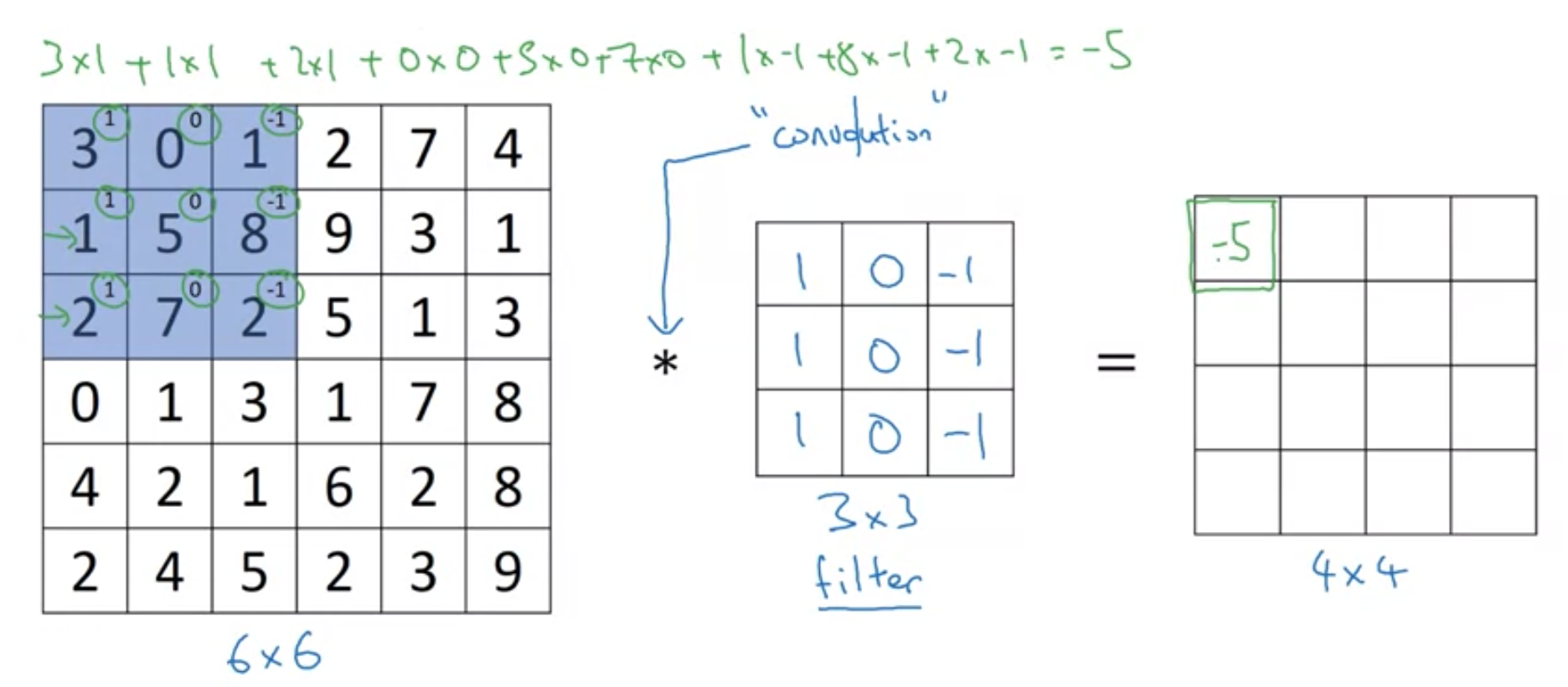
最终最右边的矩阵会填完,整个过程如下图所示。
如下图所示,通过卷积运算,我们可以快速捕捉到图片的边缘特征。更具体而言,下图最右边的白色部分,就是识别到了最左边图片的中间分界线。
目前有很多类型的卷积核,分别完成不同的边缘检测:
2.CNN结构
除了卷积模块,整个CNN的结构如下:
大概分为三种类型:
- 卷积层(convolutions):提取图像中的边缘特征
- 池化层(pooling):用来大幅降低参数量级(降维);
- 全连接层(fc):类似传统神经网络的部分,用来输出想要的结果。
吴恩达在其课程中分析,为什么卷积神经网络比传统神经网络在计算机视觉领域更好,是因为前者需要更少的参数,但是达到的效果不差。比如在以下的场景中,使用传统神经网络需要1400万个参数,而使用卷积神经网络只需要156个,是十万分之一。
3.经典模型
卷积神经网络是在计算机视觉领域是一枝独秀,从90年代的LeNet开始,沉寂了10年,也孵化了10年,直到2012年AlexNet开始再次崛起。
《经典的卷积神经网络模型》这篇文章非常好的总结了,从Alexnet(2012)到DenseNet (2017)突飞猛进的发展,值得一看。
4.算法组件
卷积神经网络是计算机视觉算法的重要组件,除此之外还有其他部分。以目标算法的Yolov4为例,该计算机视觉算法整体又分为三个组件:
- 首先,对于backbone就是主干网络,主要用于特征提取,并且基本在大型数据集(ImageNet,COCO,VOC等)上完成训练,拥有预训练参数的卷积神经网络,例如:ResNet50,Darknet53等等。
- 然后Head,翻译为头,检测头,主要用于预测目标的种类的位置(bounding boxes)
- 在backbone和head之间,会添加一些用于收集不同阶段特征的网络层,简单理解为提取的特殊特征,称为Neck。
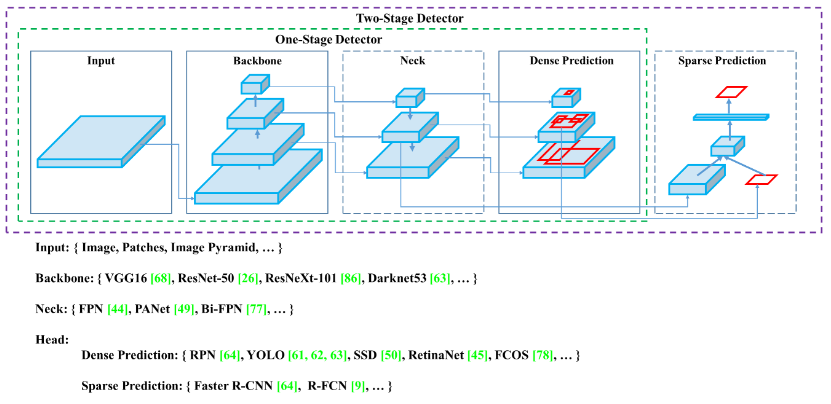
计算机视觉八大任务
计算机视觉应用的潜力非常之大。
从需求端来讲:
- 人的大脑皮层, 有差不多 70% 都是在处理视觉信息。 是人类获取信息最主要的渠道,没有之一。
- 在网络世界,照片和视频(图像的集合)也正在发生爆炸式的增长!
从供给端来看:
- 目前计算机视觉是最成熟的深度学习甚至是人工智能技术之一。
计算机视觉可以解决以下8大任务:
- 图像分类
- 目标检测
- 语义分割
- 实例分割
- 视频分类
- 人体关键点检测
- 场景文字识别
- 目标跟踪
具体案例,可以看百度图像识别的应用案例,我觉得是整理的比较好的。

若有收获,就点个赞吧
0 人点赞
