深度学习崛起
1.标志型事件
从这张图中,我们可以看到AI的突破来自于深度学习方法的突破。
标志性事件是在2012年Imagetnet计算机视觉比赛中,AlexNet以超过第二名(特征点匹配分类算法:SHIFT+FVs)Top-1分类精度近10个绝对百分点的精度提升宣告了计算机视觉深度学习时代的到来。
The ImageNet Large Scale Visual Recognition Challenge
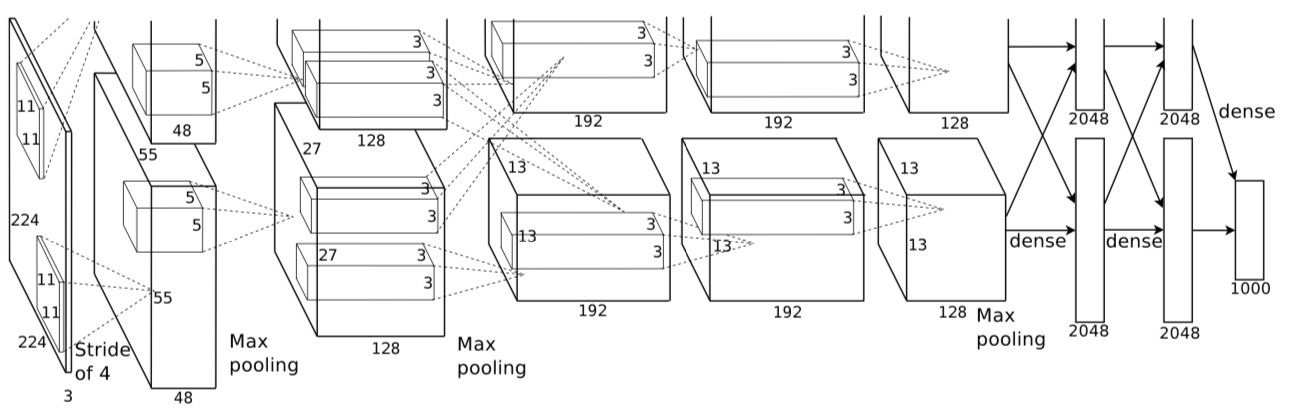
Alexnet框架
从2012年到2022年的当下,基本上主流的计算机视觉、自然语言处理等工业应用的场景,深度学习已成主流。这主要归功于以下几个层面的飞跃:
- 深度学习算法的出现
- 海量互联网数据
- 计算性能提升
2.深度学习优劣势
斯坦福教授吴恩达在其课程中给出一张图,红色曲线是传统机器学习,绿色曲线是大型神经网络。我们可以看到深度学习在数据量大的场景有非常明显的优势,在数据量小的情况则跟传统机器学习的效果差不多。所以在大数据时代,深度学习胜出。
从原理层面,深度学习比起传统机器学习牛逼的地方在于,我们只需要把原始数据给到它,它可以自动提取特征,然后达到很好的学习效果。
基于这一点,深度学习的劣势也比较明显:
- 需要的学习数据量特别大,imagenet训练集的量是百万张;
- 深度学习对算力要求很高,普通的 CPU 已经无法满足深度学习的要求。主流的算力都是使用 GPU 和 TPU,所以对于硬件的要求很高,成本也很高。
具体可以翻阅这篇文章《深度学习 – Deep learning | DL》。接下来,我们来了解一下深度学习的基础知识。
神经元
在5.AI 101这篇文章,我们可以看到,深度学习的学术流派属于联结主义,来自于神经元的模仿。以下就是一个神经元的数学/计算模型。
其有以下几个部分组成:
- 输入(x1/x2/x3)
- 比如,我们要预测一套房子的价格,那么在房屋价格数据样本中,x1 可能代表了面积,x2 可能代表地理位置,x3 可能代表朝向。
- 权重(w1/w2/w3)
- x1 的权重可能是 0.92,x2 的权重可能是 0.2,x3 的权重可能是 0.03。
- 偏移 (b)
- 从生物学上解释,在脑神经细胞中,一定是输入信号的电平/电流大于某个临界值时,神经元细胞才会处于兴奋状态,这个 b 实际就是那个临界值。
- 求和(z)
 w是指权重矩阵,x是指输入矩阵
w是指权重矩阵,x是指输入矩阵
- 激活函数 (
 )
)- 求和之后,神经细胞已经处于兴奋状态了,已经决定要向下一个神经元传递信号了,但是要传递多强烈的信号,要由激活函数来确定

- 输出(A)
- 向下一个神经元传递信号的值
深度神经网络
1.从单层到深度
实践证明,深度神经网络比浅层的神经网络,效果更好。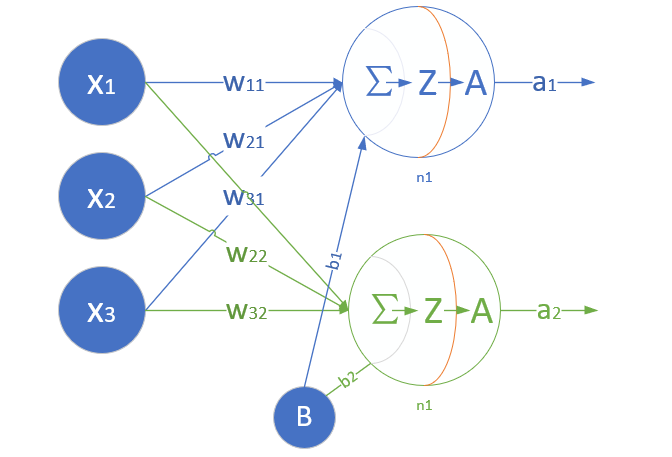
单层神经网络
深度神经网络
吴恩达教授在其课程中给出的解释,从以下两个方向去解释:
1)信息处理的分级
人的视觉系统处理信息是分级的。从视网膜(Retina)出发,经过低级的V1区提取边缘特征,到V2区的基本形状或目标的局部,再到高层的整个目标(如判定为一张人脸),以及到更高层的PFC(前额叶皮层)进行分类判断等。
同理,深度神经网络也是类似的分级处理策略。浅层级的神经网络提取边缘特征,深层的神经网络提取更复杂的信息。比如下图中,浅层的神经网络提取横、竖的线条,深层的神经网络提取整体的人脸。
所以深层神经网络模拟了人类视觉处理信息的方式,与浅层神经网络相比,更强大。
2)电路理论
如果你用浅一些的神经网络计算同样的函数,也就是说在我们不能用很多隐藏层时,你会需要成指数增长的单元数量才能达到同样的计算结果。
2.如何训练

神经网络训练流程:
- 初始化权重矩阵;
- 正向计算:拿一个或一批数据作为输入,带入权重矩阵中计算
- 通过激活函数传入下一层,最终得到预测值
- 损失计算:用均方差函数计算预测值和真实值的差距
- 梯度下降是在损失函数基础上向着损失最小的点靠近而指引了网络权重调整的方向;
- 反向传播把损失值反向传给神经网络的每一层,让每一层都根据损失值反向调整权重;
- Go to 2,直到精度足够好(比如损失函数值小于 0.001)。
具体的通俗解释可以看这篇文章《通俗地理解三大概念》

若有收获,就点个赞吧
0 人点赞
