从这篇文章开始,我将聊聊人工智能以及一些人工智能产品的思考。这一篇,先复习一下基本概念。
弱 vs 强人工智能
人工智能有很多维度进行分类,一个维度就是强弱之分。弱人工智能擅长处理垂直场景,强人工智能具有像人类一样的抽象思考能力。
弱人工智能的英文是Artific ial Narrow Intelligence,简称为ANI,弱人工智能是擅长于单个方面的人工智能。比如有能战胜象棋世界冠军的人工智能阿尔法狗,但是它只会下象棋,如果我们问它其他的问题那么它就不知道怎么回答了。只擅长单方面能力的人工智能就是弱人工智能。
强人工智能的英文是Artificial General Intelligence,简称AGI,这是一种类似于人类级别的人工智能。强人工智能是指在各方面都能和人类比肩的人工智能,人类能干的脑力活它都能干。强人工智能就是一种宽泛的心理能力,能够进行思考、计划、解决问题、抽象思维、理解复杂理念、快速学习和从经验中学习等操作。强人工智能在进行这些操作时应该和人类一样得心应手。
这个概念其实很重要,我们很多对人工智能不熟悉的朋友,对于人工智能的理解基本上是科幻片灌输的,而那些电影里面的人工智能基本上是强人工智能。但是,我们产业实践上,目前还处于弱人工智能的成熟和蓬勃发展期。
痴迷于强人工智能,只能提出一些产业界不能落地的空想。这种基础的认知偏差,会影响我们在项目实操上的策略以及落地可能性。
三大学术流派
从1956年人正式提出工智能开始,人工智能的研究到目前为止分为三个流派。
1.符号主义
符号主义,又称专家系统,认为人工智能源于数理逻辑。一般采用人工智能中的知识表示和知识推理技术来模拟通常由领域专家才能解决的复杂问题,专家系统=知识库+推理机。
2.联结主义
该学派把人的智能归结为人脑的高层活动,研究核心是神经元网络,仿造人的神经系统,把人的神经系统的模型用计算的方式呈现。目前深度学习的热潮实际上是联结主义的胜利。

3.行为主义
行为主义,又称控制论学派。该学派认为人工智能源于控制论,推崇控制、自适应与进化计算,主张利用机器对环境作用后的响应或反馈为原型来实现智能化。80年代诞生了智能控制和智能机器人系统,目前大热的强化学习属于行为主义学派。

4.人工智能研究的历史
我们人类对于技术的进步,短期高估,长期低估。人工智能起起伏伏发展了60多年,终于在2007年深度学习的崛起取得突破。
在网上搜到一个国科大《高级人工智能》的PPT,里面提到了三大学派和人工智能的发展阶段关系,可以看出目前我们处于数据驱动的不确定人工智能阶段,下一阶段重点是交互驱动的涌现智能。
机器学习 vs 深度学习
1.机器学习概念
从下图我们可以看到,(弱)人工智能 、机器学习、深度学习之间的关系。
机器学习的定义比较抽象,用人话讲是这样的:
机器学习指计算机使用大数据集训练机器去学习而不是硬编码规则来学习的能力。 机器学习使用算法来解析数据、学习数据,然后对现实世界中的某些内容做出预测或判断。它只是一种实现AI的技术,一种训练算法的模型。
2.机器学习例子
举个例子
假如我们正在教小朋友识字(一、二、三)。我们首先会拿出3张卡片,然后便让小朋友看卡片,一边说“一条横线的是一、两条横线的是二、三条横线的是三”。 不断重复上面的过程,小朋友的大脑就在不停的学习。 当重复的次数足够多时,小朋友就学会了一个新技能——认识汉字:一、二、三。
机器学习的过程跟上面人类学习的过程非常类似。
- 上面提到的认字的卡片在机器学习中叫——训练集
- 上面提到的“一条横线,两条横线”这种区分不同汉字的属性叫——特征
- 小朋友不断学习的过程叫——建模
- 学会了识字后总结出来的规律叫——模型
想要对机器学习有更多的了解,可以看此文《机器学习》。
2.神经网络基础
机器学习领域出现了各种训练算法的模型,包括决策树、支持向量机、朴素贝叶斯、随机森林等等。其中神经网络模型是一个重要的方法。
正如前面所说,神经网络是属于联结学派的,通过模拟生物神经网络中的神经元结构得到。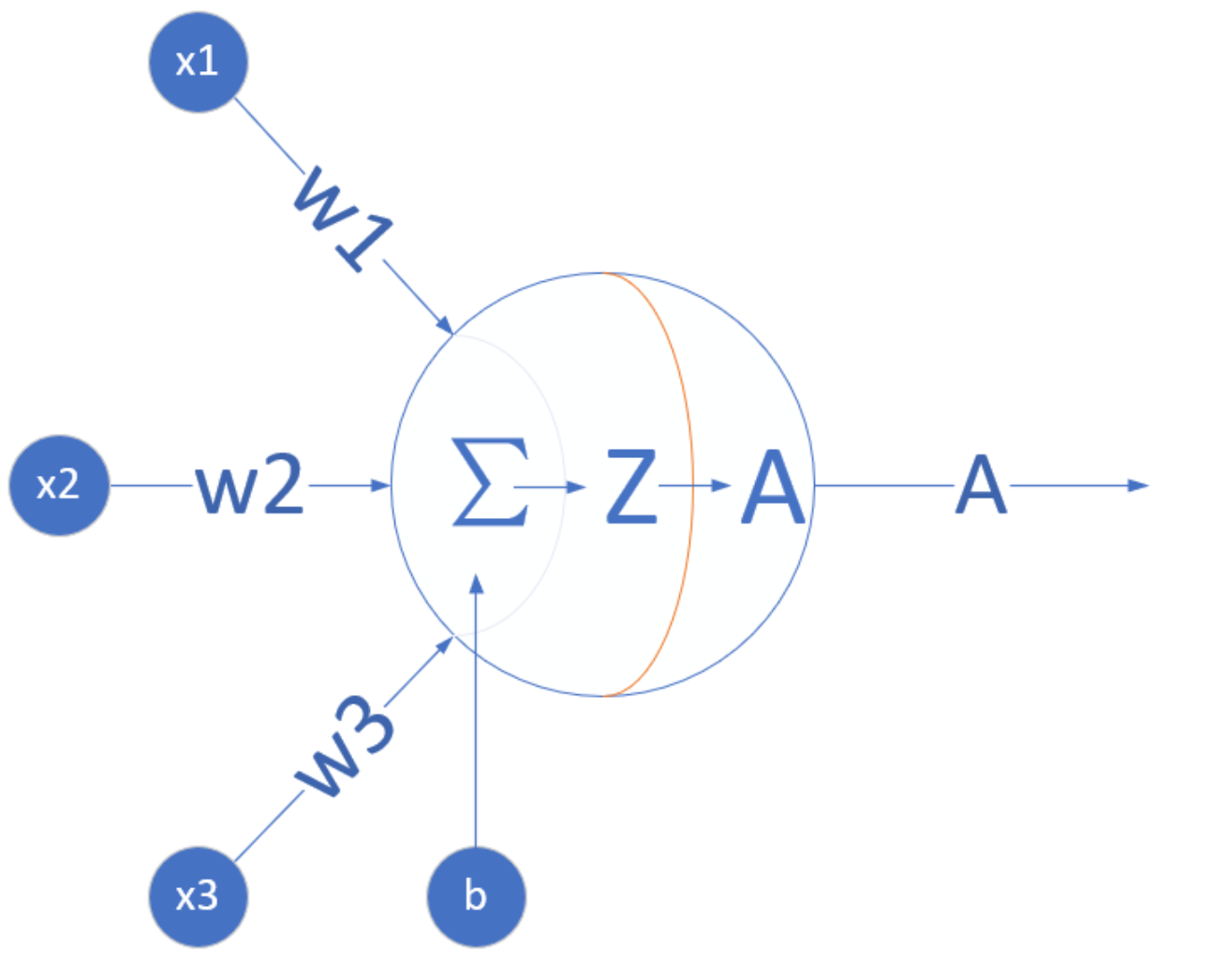
一个神经元的数学/计算模型
人们不断增加神经网络的层次数目,这就产生了DNN(深度神经网络)。DNN深度神经网络在最近十年给人工智能领域带来了新的生机,并在图像分类、语音识别、自然语言处理等方面取得了重大突破。我们将在后面的文章仔细聊聊这块。
监督学习
1.监督学习的概念
机器学习有很多算法,可以分为三大类:监督学习、非监督学习、强化学习
从图像分类、语音识别、自然语言处理领域的业界实战角度来,能够产生巨大商业价值的深度学习算法,很多都是用监督学习的方式进行。所谓监督学习,就是需要给到一堆经过人类标注或机器生成之后的正确数据集给到机器去学习。
1)传统机器学习的标注
传统机器学习需要人工标注特征。举个例子,下面的表格中,【城市】【地段】【新房价】都是需要人工收集的特征数据。
所谓的监督学习,就是我们要给到机器一堆标注了 房子特色(x矩阵) 和二手房房价(y)的房子数据(百万条~),这样机器就会建立房子特色和房价之间的关系。基于这个模型,就可以进行二手房价的预测了。
| 房子编号 | 房子特色(X) | 房价(Y) |
|---|---|---|
| 1 | (城市:杭州,地段:优,新房价格:2500…..) | 3000 |
| 2 | (城市:苏州,地段:差,新房价格:1500…..) | 1000 |
| ….. |
2)深度学习的标注
深度学习模型自己能提取特征。比如下图,我们只需要告诉机器,这张图片里面是狗,然后把标准答案给到机器去学习。机器学习了成百上千万张这种图片之后,给到一张类似的图片,它就能知道里面有什么东西了。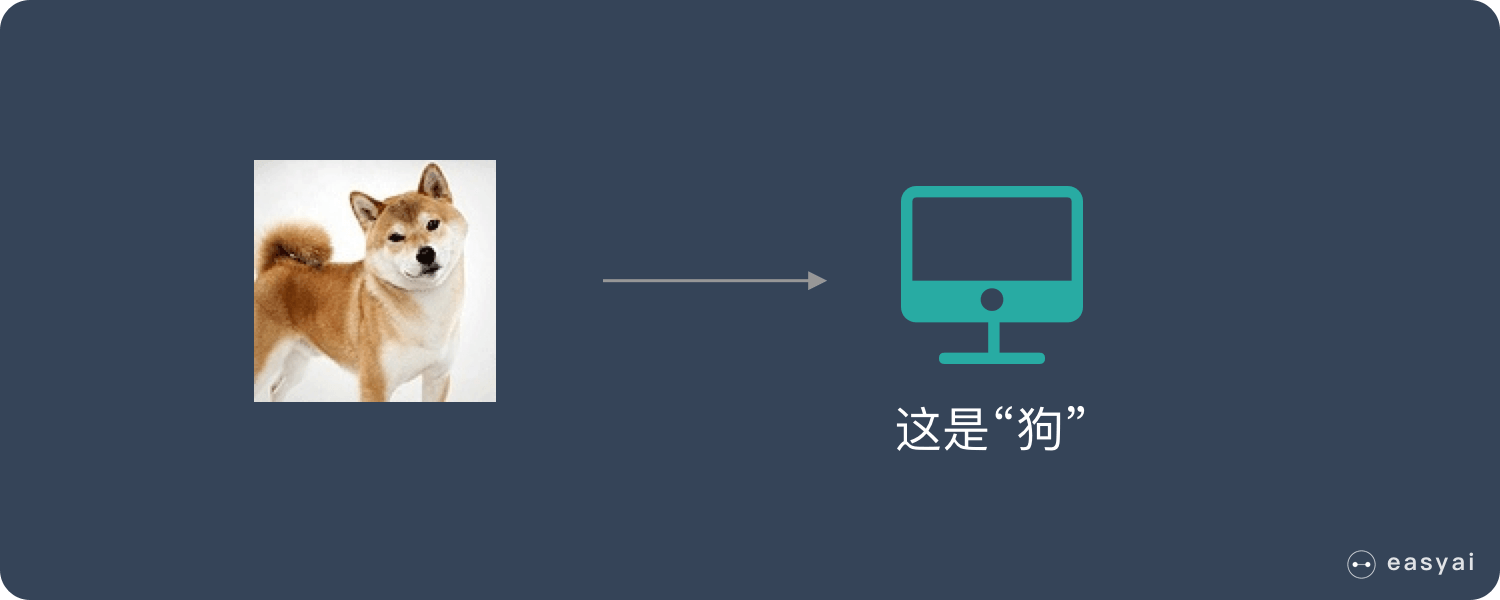
机器学习在很多监督学习场景都得到了广泛的应用,这些场景都要求进行标准答案的标注,这也是我们做AI产品的日常工作。
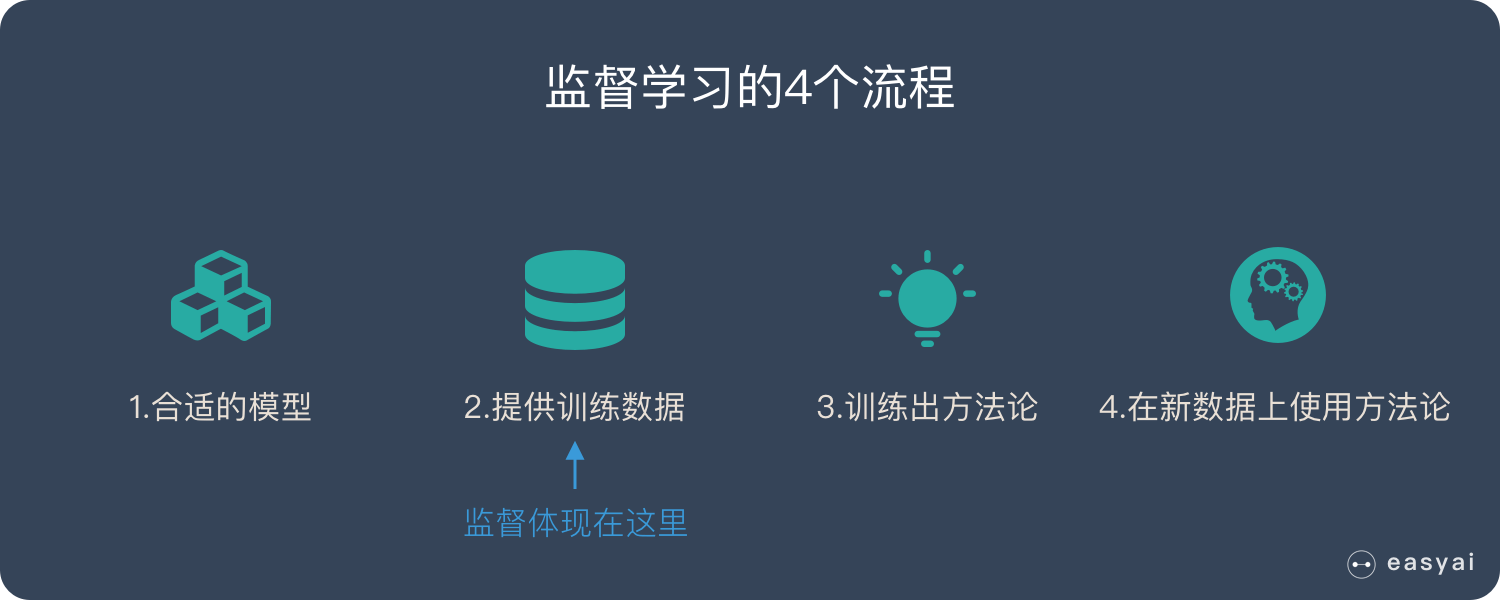
2.监督学习的流程
监督学习的流程,从下面的流程图可以看到,
- 选择合适的算法模型;
- 我们需要给深度神经网络以大量的训练数据,以供这些模型去学习
- 然后得到模型的参数(方法论)。
- 我们拿到这个模型以及参数后,就可以对新的样本数据进行预测。

3.数据!数据!
深度神经网络之所以能够在最近十年大放光彩,一个关键点在于互联网的崛起,为深度神经网络提供了巨量的监督学习所需要的训练数据,使得深度神经网络训练之后的能力得到飞跃,比如计算机视觉和自然语言处理,使得深度神经网络能够得到大规模的业界应用。
比如,吴恩达在谷歌做的AI识别猫的深度学习实验,学习了1000万个视频,在当时业界产生了很大的影响力,称之为“google cat”实验。
所以人们会越来越重视训练数据的质量,这也是监督学习的核心模块之一。甚至在某些场景,训练数据的质量要高于深度神经网络模型的结构优化本身。没有数据,对于AI工程师来说,就是“巧妇难为无米之炊”。
Andrew Ng:“与深度学习类似的是,火箭发动机是深度学习模型,燃料是我们可以提供给这些算法的海量数据。”

若有收获,就点个赞吧
0 人点赞
