v1.0功能列表
正如在1.需求研究这一篇文章所说,我们第一个版本先解决kano模型的基础需求:
- 功能
- 识别手指单词,展示单词释义、发音(基础型);
- 跟读单词,并进行评测(期望型)
- 内容
- 覆盖小学+的单词量(基础型);
- 技术
- 识别准确率(基础型);
- 识别反应速度(基础型);

看起来已经是最基础的功能了,但是因为我们是一个自研的项目,所以实现起来一点也不容易。
问题以及方案
1.边缘计算
没有做这个项目,我没体会到边缘计算的重要性。比如大力台灯能够把指尖识别和OCR识别两种状态分开,就在于他们在台灯端部署了指尖识别算法,识别到手指后才把该图片放到OCR识别流程,没有识别到手指则不动。

所以大力的识别步骤应该是这样的: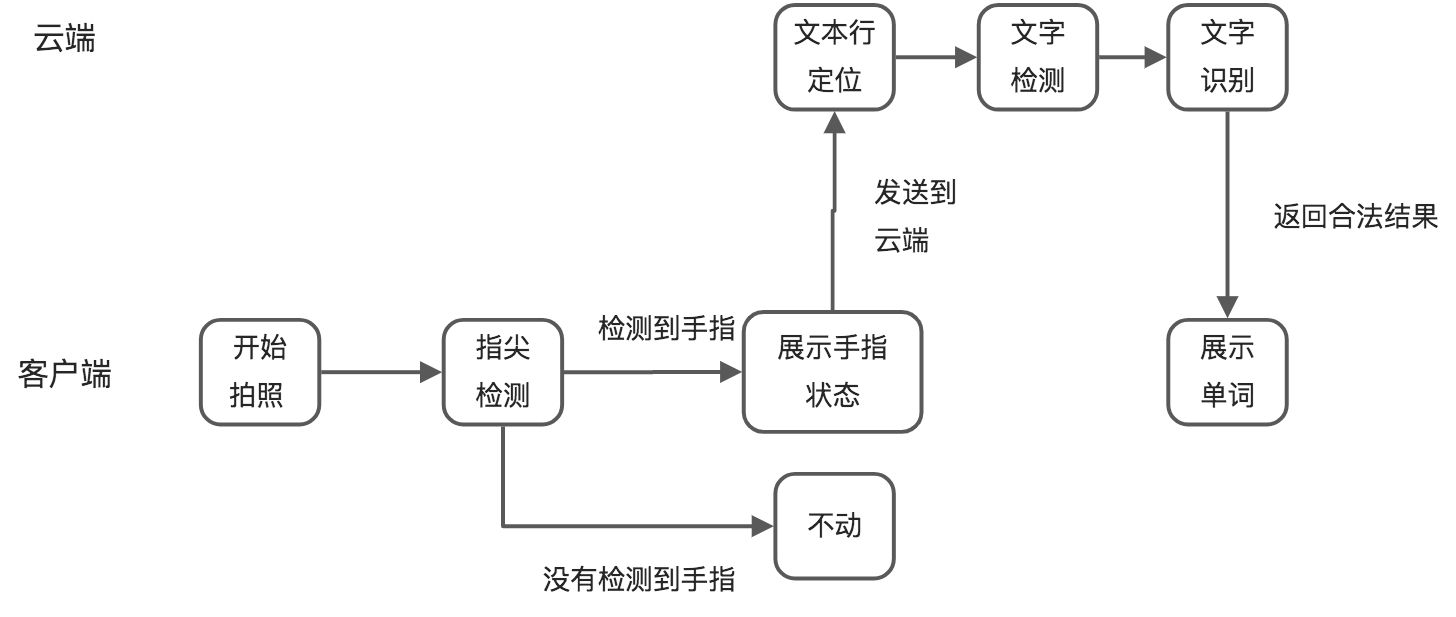
由于我们项目硬件端采用了是有点古早的芯片,导致我们没有边缘计算能力,只能所有的图片都上传到云端进行识别。如果识别到图片里面有手指,则返回识别到手指的状态。
所以我们的识别步骤是这样的: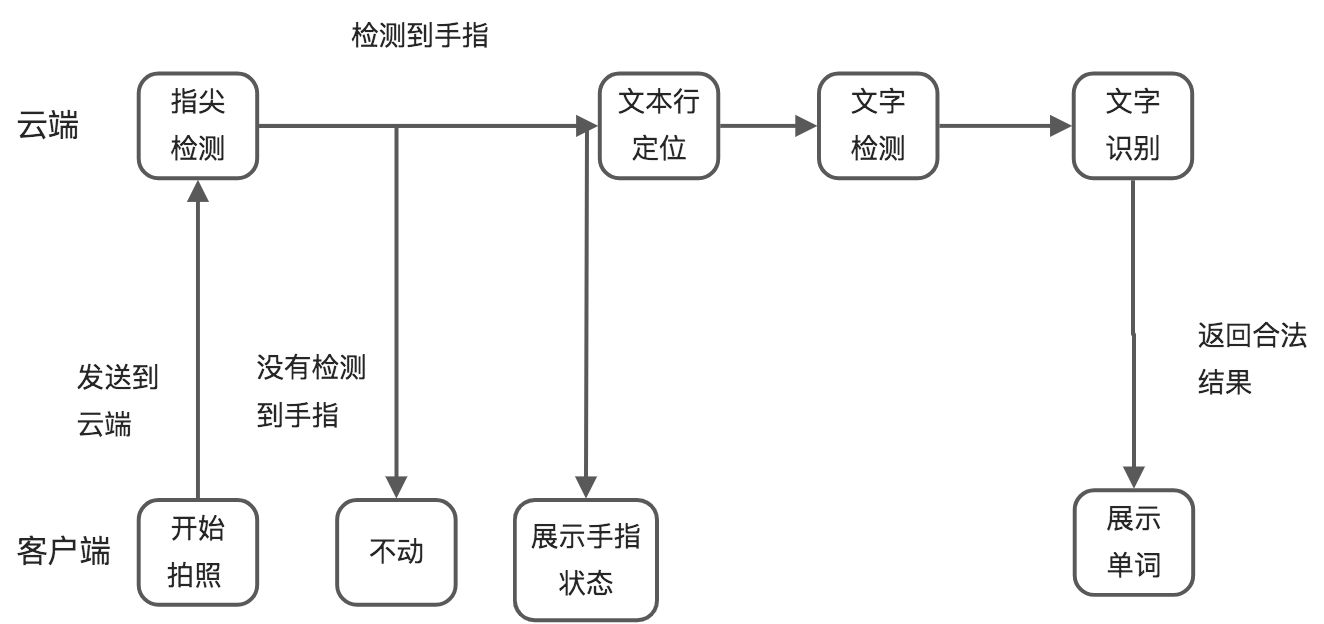
相比于大力的三种状态,我们只能有两种状态。第二种状态就是,我们识别到手指, 就立刻进行指尖+OCR的识别, 同时返回手指状态和识别结果。
我们后续通过实验发现,90%通过摄像头收集到云端来的照片都是没有手指的图片,即:这种方案造成了9倍的计算资源浪费,同时识别速度也几乎慢了一倍。
边缘计算除了能够更细颗粒度的区分识别状态,还能够有效提升识别速度。有道号称0.5秒超快查询,估计他们不仅仅在终端部署了指尖识别算法,也有可能部署了OCR识别算法,这样他们就不需要进行云端的计算,大大节省了时间。
纸上世界提到了手指轨迹识别,要求每秒摄像头拍摄20s,这些拍摄和处理都是终端的边缘计算来搞定的。
2.识别准确率
我们的指尖和OCR算法是自研的,所以我们的准确率刚开始是比较低的。为了满足教育场景的需求,我们做了以下几件事情:
1)算法先行
我们在还未开发指尖查词产品时,就开始准备验证集,推进算法同学的双周迭代。
2)聚焦核心场景
less is more。我们聚焦在低年级学生在绘本和书本指读的场景,所以验证集没有包括小字体、中英混合、封面等场景。
3)报错功能
考虑到我们目前算法的能力,我们在产品层面做了降低用户预期的方案。
- 算法准确率差会导致识别错误,我们给予报错提示

- 算法把手指A单词,识别成书本的另外一个B单词:用户可以点击右下角进行反馈

3.词库建设
因为项目之前没有在词库层面有积累,所以我们也做了聚焦,爬取了小学生级别词汇量的单词,大概在4万个左右。
上线后的优化
上线后,我们自己初步体验了功能,发现一些影响用户体验但是相对容易优化的问题。
1.识别速度优化
识别速度是个大问题,尤其是我们本身的硬件性能很差的情况。我们主要针对以下几个场景做优化:
1)首次启动速度慢
我们发现了首次启动速度慢的问题,对客户端上传的流程进行拆解:
- 打开摄像头
- 获取到第一帧数据
- 数据转码压缩
- 图片上传
我们优化了流程,把原来首个单词的识别耗时从5.5s 减少到 4.5s。大力台灯当时我们测的首个单词耗时在4.2s。
2)整体耗时长
我们在后端进行流程拆解之后,发现图里面的7.调用语音合成和8.下载语音文件耗时比较长,大概需要1s。这里面的语音文件主要是单词释义的TTS语音合成文件。
我们做了优化,主要是预先合成了这8万个单词的释义语音文件,并保存下来,方便及时调用。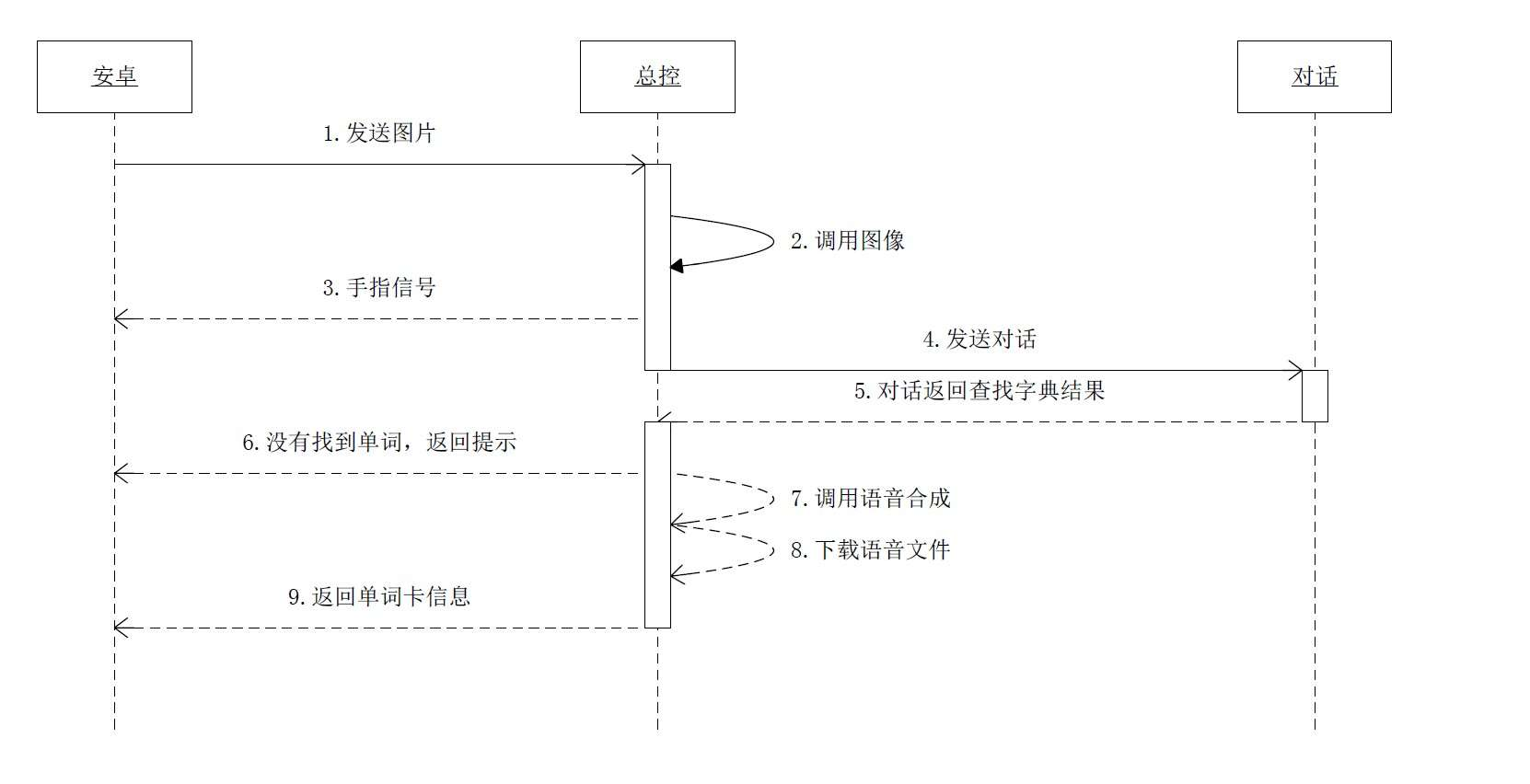
3)信息堵塞
我们后来发现拍照频率也是非常关键的一个参数。我们之前的拍照频率是500ms拍一张,但是处理一张图片要1~2s,所以会发生信息堆积。所以我们调整了拍照频率到1s,整个体验更稳定一些。
2.识别准确率优化
通过我们的努力,我们把算法的识别率从最初的70%提升到了95%。这个问题,我将在后续AI相关的文章中分享我们做算法迭代的一些实践。
3.词库优化
我们发现很多类型的单词,不是新的单词,但是在课文中的比例也非常大,我们称之为衍生此, 包括以下几个类型:
- 复数(apples)
- 过去分词 (worked)
- 现在进行时 (working)
- 第三人称单数 (works)
- 缩写词 (it’s)
我们就把4万个单词通过爱词霸去爬取他们的衍生词,如下图所示:
后面发现,这些爬完后的衍生词数量也是4万左右,所以我们最终总共词汇量在8万左右。衍生词上线后,单词不存在的报错大幅减少。
后续迭代思考
1.发音跟读问题
除了上面我们自查提到的问题,我们进行了用户回访,发现用户最主要提到的是发音跟读的问题。
发音比较机械 单词引导发音的速度过快,尤其是长单词,听得不是很清楚 跟读的时候可以慢一点,如果领读语速太快,则小朋友跟不上。 跟读评测不是很准
我理解是,小朋友自学新单词的步骤是这样的:
- 先听音频
- 再跟读
- 最后自己读
对于低年级小朋友来说,学英语单词最重要的是模仿产品的标准发音开口读,读了之后进行跟读评测,并进一步矫正。所以识别只是第一步,后续还有很多的点可以展开,比如:
- 高质量的单词发音视频;
- 慢速领读,最好配有口型发音视频;

- 跟读评测,最好还有针对性的矫正;
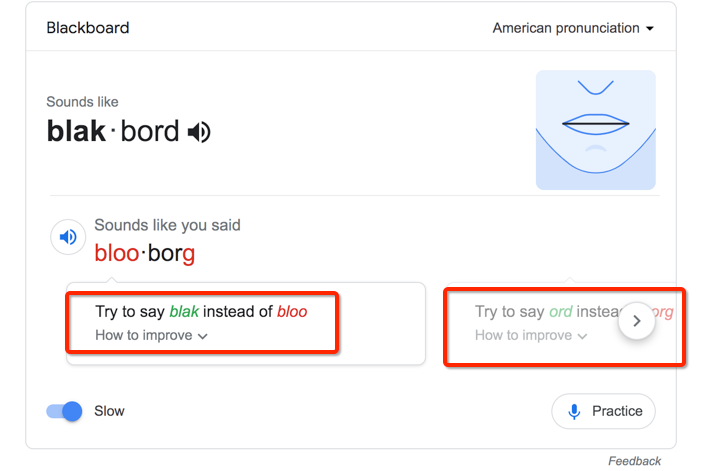
- ……..
2.场景问题
1.需求研究这篇文档我们提到了用户可能存在两个场景,绘本阅读和课本复习。后续的产品需要对这两个场景做优化。比如,有道的方案是这样的:
- 针对绘本阅读场景:出有道点读版

- 针对课本复习场景:听教材原音

3.家长管理问题
很多双职工家庭晚上要加班,普遍有通过硬件进行远程指导的需求,这就要求帮助小朋友养成自学的习惯,并且产出学习报告,方便家长管理。

若有收获,就点个赞吧
0 人点赞
