在这篇文章,我分享一下在指尖查词这个项目用到的计算机视觉技术。
算法框架
据我个人的理解,指尖查词的算法框架如下:
其中涉及到计算机视觉技术如下:
- 指尖检测
- 文字检测
- 文字识别
指尖检测
指尖检测就是识别用户的指尖,从分类上属于计算机视觉八大任务之一的目标检测。
目标检测任务的目标是给定一张图像或是一个视频帧,让计算机找出其中所有目标的位置,并给出每个目标的具体类别。指尖检测属于目标检测中的手势识别。
目标检测算法中,Yolo属于比较强的一种,数据对比如下图所示,目前Yolo已经进化到V5版本。

Yolov5的算法结构如下:
《Object Detection Algorithm — YOLO v5 Architecture》
OCR技术
OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的OCR一般面向扫描文档类对象,现在我们常说的OCR一般指场景文字识别(Scene Text Recognition,STR)。
OCR技术有着丰富的应用场景,以下面向垂类的结构化文本识别是目前ocr应用最广泛、并且技术相对较成熟的场景。
在指尖查词项目中,除了指尖检测属于目标检测外,文字检测和文字识别就属于OCR技术范畴。
文字检测
文字检测是指:给定输入图像或者视频,找出文本的区域,可以是单字符位置或者整个文本行位置。
文本检测有以下几种方法,分为回归和分割两类:

文字识别
文字识别其任务为识别一个固定区域的的文本内容,具体地,模型输入一张定位好的文本行,由模型预测出图片中的文字内容和置信度,可视化结果如下图所示:
规则文本的文字识别的主流算法分为两类,分别是基于 CTC (Conectionist Temporal Classification) 的算法和 Sequence2Sequence 算法,区别主要在解码阶段。
我们项目用的是CRNN,具体的结构如下: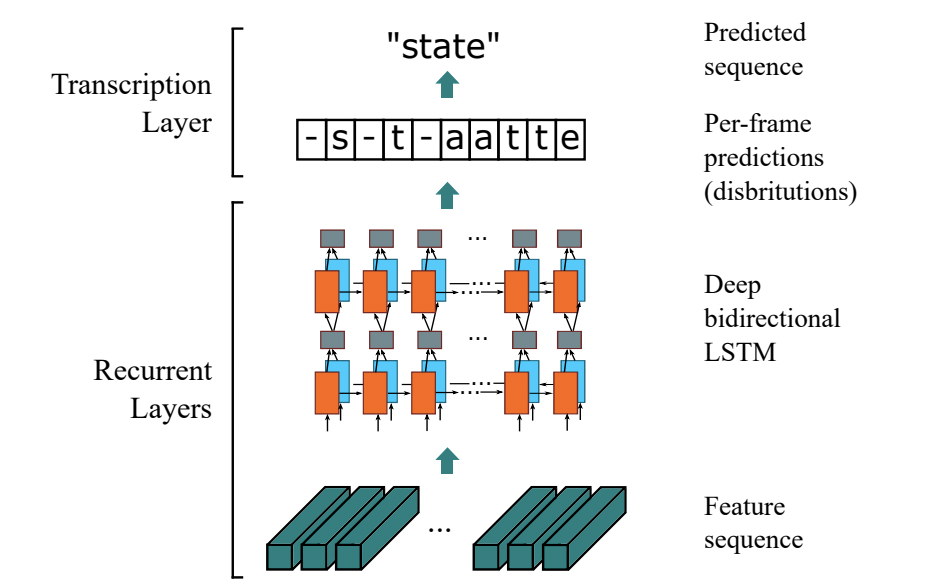

若有收获,就点个赞吧
0 人点赞
