消费者
推模式
public class Consumer {public static void main(String[] args) throws InterruptedException, MQClientException {// 设定group并初始化DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name");// 指定namesrv地址(可以;分隔注册多个)consumer.setNamesrvAddr("localhost:9876;localhost2:9876");consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);// 订阅topic(第二个参数是消息tag,用于过滤更细化topic下的维度,用于*标识所有)consumer.subscribe("TopicTest", "*");// 注册callback,也就是消息handlerconsumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {System.out.println("%s Receive New Messages: " + Thread.currentThread().getName() +" , " + msgs);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});//启动消费者consumer.start();System.out.printf("Consumer Started.%n");}}}
group用于将多个consumer进行组合,提高并发处理能力(生产者的group同理),也就是对于某个topic来说,同一个group下的消费者可以并行消费这个topic下的消息。属于点对点的消息模式。还有一种广播模式,就是topic下的消息会被同一个group下的所有消费者消费(用处?)。如果需要多个group消费同一个topic,配置订阅即可。
在实际实现中,consumer通过和broker建立长轮询的方式达到Push的效果。长轮询是指consumer通过轮询的方式向broker拉消息,但是broker那边如果有消息就立即返回,如果没消息会hold一段时间(5s),如果这段时间内有消息过来就一并返回,如果没有就正常返回。这样做的好处是达到了push模式的消息即使下发的效果,但是缺点在于socket被hold住,占用了consumer和broker的连接资源。
通过ProcessQueue进行流量控制(并发场景下的任务下发),每次在拉取之前consumer会判断ProcessQueue中的消息数量、消息量、offset跨度等,任何一个维度超过配置值则放弃拉取,等待下一轮拉取。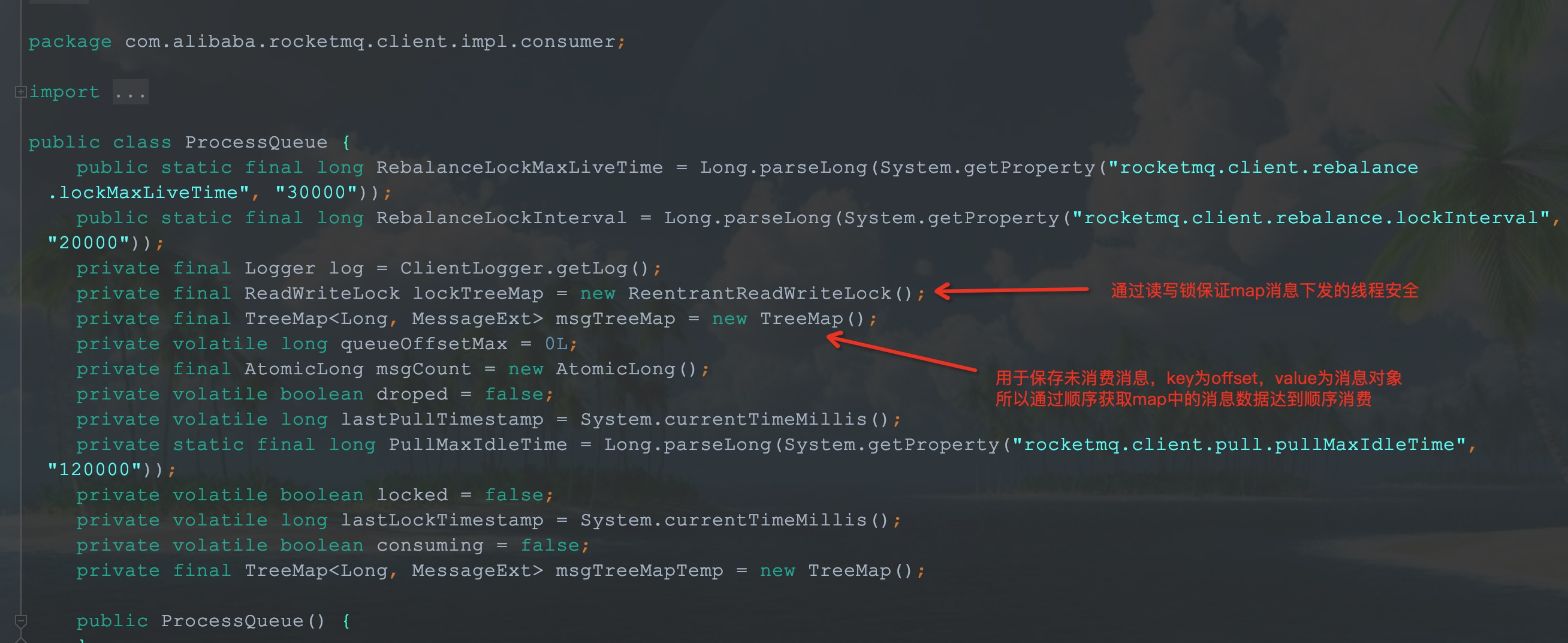
拉模式
拉模式下配置和上面一样(毕竟到底也是pull模式),区别在于DefaultMQPullConsumer需要额外做:
- 无限循环拉取
- 遍历MessageQueue
- 保存offset
生产者
普通生产者
public class Producer {public static void main(String[] args) throws Exception {//设定group并初始化DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");// 指定namesrvproducer.setNamesrvAddr("localhost:9876");// 设定实例名称,一般用于区分单个JVM启动多个producerproducer.setInstanceName("instance1");// 发送失败重试次数producer.setRetryTimesWhenSendFailed(3);// 启动生产者producer.start();for (int i = 0; i < 100; i++) {// 创建消息体要求给定topic+tag+payloadMessage msg = new Message("TopicTest", "TagA" , ("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));// 等级对应延迟时间:1s/5s/10s/30s/1m/2m/3m/4m/5m/6m/7m/8m/9m/10m/20m/30m/1h/2hmsg.setDelayTimeLevel(3);// 发送到broker// 同步方式SendResult sendResult = producer.send(msg);// 自定义路由到broker的规则,可以用于顺序消费的场景sendResult = producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> list, Message message, Object userId) {return list.get(userId.hashCode() % list.size());}}, "userId");System.out.printf("%s%n", sendResult);// 异步方式producer.send(msg, new SendCallback() {@Overridepublic void onSuccess(SendResult sendResult) {System.out.printf("send success, %s%n", sendResult);}@Overridepublic void onException(Throwable throwable) {System.out.printf("send failed, %s%n", throwable.getMessage());}});}// 关闭producerproducer.shutdown();}}
demo中体现了同步发送、异步发送、发送延迟消息、自定义路由发送等场景。
发送事务消息
- 生产者发送事务消息,mq会将其标记为【待确认】,订阅方无法消费。
- mq返回消息入列成功。
- 生产者执行本地逻辑。
- 生产者根据步骤3的执行结果如果为成功,这发送二次确认消息commit,mq将步骤1中的消息标记为正常消息,订阅方可以正常消息。
- 执行失败,发送二次确认消息rollback,mq将步骤1中的消息删除。
:::warning
如果步骤1之后生产者挂掉,如何处理?
如果mq未收到二次确认,经过固定时间后会针对【待确认】消息进行回查。
回查时如果生产者已恢复,则继续按步骤4的逻辑执行,如果没恢复回查请求会发送到同一个group的其他producer中执行。 :::
offset如何存储和调整
DefaultMQPushConsumer:
上述的消费者点对点方式的offset由broker存储,因为组内其他进程消费的offset影响本进程的下一次获取offset。
上述的消费者广播方式的offset由本地存储,因为组内其他进程消费的offset不影响本进程下一次获取offset。
DefaultMQPullConsumer:
DefaultMQPushConsumer中不管是哪种方式,都不需要在业务代码中显示处理offset的存储,但是DefaultMQPullConsumer需要自己来存储offset,也就是上面提到的第三点。如何存储呢?
- jvm内存,不推荐,一旦机器重启就可能导致丢失。
- 持久化到磁盘,推荐。
- 通过中间件比如mysql、redis,推荐。
如何调整offset呢?
// 从最早的offset开始消费,如果消息非常多,就比较不适合了。consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);// 从最近的offset开始消费,一般使用方式consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);// 指定时间戳(精度秒)开始消费consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_TIMESTAMP);
:::warning 主从服务器都在运行过程中,消息消费者是从主拉取消息还是从从拉取? ::: 答:默认情况下,RocketMQ消息消费者从主服务器拉取,当主服务器积压的消息超过了物理内存的40%,则建议从从服务器拉取。但如果slaveReadEnable为false,表示从服务器不可读,从服务器也不会接管消息拉取。
:::warning
当消息消费者向从服务器拉取消息后,会一直从从服务器拉取?
:::
答:不是的。分如下情况:
1)如果从服务器的slaveReadEnable设置为false,则下次拉取,从主服务器拉取。
2)如果从服务器允许读取并且从服务器积压的消息未超过其物理内存的40%,下次拉取使用的Broker为订阅组的brokerId指定的Broker服务器,该值默认为0,代表主服务器。
3)如果从服务器允许读取并且从服务器积压的消息超过了其物理内存的40%,下次拉取使用的Broker为订阅组的whichBrokerWhenConsumeSlowly指定的Broker服务器,该值默认为1,代表从服务器。
:::warning 主从服务消息消费进度是如何同步的? ::: 答:消息消费进度的同步时单向的,从服务器开启一个定时任务,定时从主服务器同步消息消费进度;无论消息消费者是从主服务器拉的消息还是从从服务器拉取的消息,在向Broker反馈消息消费进度时,优先向主服务器汇报;消息消费者向主服务器拉取消息时,如果消息消费者内存中存在消息消费进度时,主会尝试跟新消息消费进度。

若有收获,就点个赞吧
0 人点赞
