:::warning
什么是feed流?
:::
Feed,源自早期的RSS。
是一种呈现内容给用户并持续更新的方式,用户可以选择订阅多个资源,网站提供feed 网址 ,用户将feed网址登记到阅读器里,在阅读器里形成的聚合页就是feed流。
2006年 Facebook重新定义了feed,叫News Feed,我们如今广泛使用的模式和这个类似。它有几个特点:
订阅源不再是某个内容,而是生产内容的人/团体。订阅中通常夹杂非订阅内容,比如热门推荐,广告。
内容也不再严格按照timeline,广泛使用智能feed排序。新的feed流刻意不再需要主动搜索,而是主动呈现琳琅满目的内容。它对我们了如指掌,给我们想了解的,让我们不停的刷新沉溺于此。
对于用户来说这样一个超简单高效的了解内容方式,对于设计者来说,却是绞尽脑汁。
- Feed:Feed流中的每一条状态或者消息都是Feed,比如朋友圈中的一个状态就是一个Feed,微博中的一条微博就是一个Feed。
- Feed流:持续更新并呈现给用户内容的信息流。每个人的朋友圈,微博关注页等等都是一个Feed流。
- Timeline:Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流,但是由于Timeline类型出现最早,使用最广泛,最为人熟知,有时候也用Timeline来表示Feed流。
- 关注页Timeline:展示其他人Feed消息的页面,比如朋友圈,微博的首页等。
- 个人页Timeline:展示自己发送过的Feed消息的页面,比如微信中的相册,微博的个人页等。
:::warning Feed流的分类? ::: Feed流的分类有很多种,但最常见的分类有两种:
- Timeline:按发布的时间顺序排序,先发布的先看到,后发布的排列在最顶端,类似于微信朋友圈,微博等。这也是一种最常见的形式。产品如果选择Timeline类型,那么就是认为
Feed流中的Feed不多,但是每个Feed都很重要,都需要用户看到。 - Rank:按某个非时间的因子排序,一般是按照用户的喜好度排序,用户最喜欢的排在最前面,次喜欢的排在后面。这种一般假定用户可能看到的Feed非常多,而用户花费在这里的时间有限,那么就为用户选择出用户最想看的Top N结果,场景的应用场景有图片分享、新闻推荐类、商品推荐等。
:::warning 存储方案? :::
- 用户关系数据:分布式mysql
- 用户feed信息数据:分布式mysql
- 推模式的feed流数据:nosql
- 拉模式的feed流数据:redis
推模式(写扩散)
- 用户产生feed,保存到feed发信箱。
- 拉取该用户的粉丝列表。
- 异步向每个粉丝的feed收信箱推送数据。
优点:
- 用户拉取feed流的速度快,从feed收件箱查询即可。
缺点:
- 大V用户的粉丝量巨大,需要推送的粉丝量巨大,对存储空间的消耗巨大。
- 有很多僵尸粉,会造成空间浪费。
拉模式(读扩散)
- 用户产生feed
- 粉丝用户上线后触发动态获取,拉取用户的关注列表。
- 拉取每个关注对象的feed发信箱信息。
- 合并关注用户的feed列表。
- 为了提高性能还可以用redis对首次计算出来的feed信息进行缓存。
优点:
- 无空间浪费。
缺点:
-
推拉结合
结合上述两点优缺点,针对不同发送者和接受者进行维度拆分,采用不同推送方案:
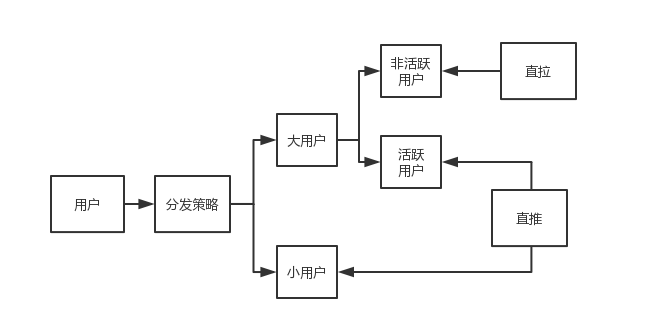
大V用户采用拉,普通用户采用推。
- 大V用户(微博)的粉丝量巨大,以及存在僵尸粉的问题。
- 普通用户(朋友圈)占比用户为绝大部分,推模式提高用户体验。
- 活跃用户采用推,非活跃用户采用拉。理由同上。
- 实际上微博的拆分维度和处理方式会更加复杂,包括用户注册时间、地理位置等维度进行拆分。
 :::warning
上述不管是哪种都很难解决一个问题:超大V发送极具话题性的feed(比如之前微博挂的几次)。
:::
:::warning
上述不管是哪种都很难解决一个问题:超大V发送极具话题性的feed(比如之前微博挂的几次)。
:::
原因:
- 超大V决定了粉丝量巨大,推模型压力很大,且推送后用户很可能点入大V主页查看。
- 极具话题决定了非活跃用户会变成活跃用户进行拉模式读取大V的feed。
- 极具话题决定了有大量非关注用户会进入大V主页进行信息查看。
以上3点导致大V的主页查询量暴增,从而导致系统load飙高无法提供服务。
处理:
- 做好性能压测,缓存节点和服务节点扩容。
- 做好降级,最好能细到uid维度的feed流读取降级,比如将该大V的feed获取接口降级(返回空数据等),保障系统其它用户的服务可用性。

若有收获,就点个赞吧
0 人点赞
