B+树
B+树只能找到数据所在页,然后对页中数据进行二分查找拿到具体行数据。
根据数据页(叶子节点)和索引页(非叶子节点)的存放上下限,在表实际插入、删除的过程中存在页拆分和页合并的情况,而这种情况需要磁盘IO。所以说建立太多的索引会导致增删性能急剧下降。
聚集索引&普通索引
聚集索引是将表的主键建立一颗B+树,叶子节点存放完整行数据。
非聚集索引是将表的普通索引建立B+树,叶子节点存放主键数据,然后通过再查一次聚集索引获取行数据。
由于聚集索引的叶子节点直接存储行数据的特性,再加上B+树的叶子节点通过双向链表进行关联,所以通过主键进行排序查询和范围查询的效率是非常高的。
而非聚集索引的范围查询则不一定是主键的顺序,所以在查到范围数据之后会需要逐条且离散回表查询行数据。
但是非聚集索引由于不存储行数据,所以整颗B+树的大小是相比聚集索引是非常小的,所以单个叶子节点能存放更多索引数据,也就是可以减少磁盘IO提高性能。
:::warning
为什么聚集索引只能有一个,而非聚集索引可以有多个?
:::
因为innodb的表是索引组织表,因为行数据只会存一份,既然存哪里都是存,不如按某种顺序进行存储,便于后续查询,既然B+树适合查询,那当然就会用B+树来存,那么顺序怎么定,就需要一个规则。那么适合这种规则的就聚集索引,满足这种规则的字段叫主键。所以也就是说,并不是主键是聚集索引,而是聚集索引恰好需要一个主键。
换句话说,主键会影响行数据的存放顺序,而行数据只能存一份,所以聚集索引只能有一个,而非聚集索引不影响行数据存放顺序,所以可以有多个。
这里也可以推断出来一个结论:主键索引是必须有的。
关于联合索引
对多个列建立索引,本质上也是一颗B+树,顺序是根据联合的col的顺序来定,也就是先按第一个col的顺序来排,再按第二个col的顺序来排,以此类推,如下结构: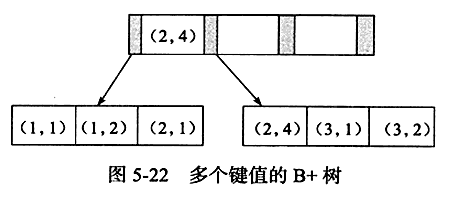
从a的视角来看,遵循1、2、3的顺序,从ab的视角来看,遵循11、12、21、24、31、32的顺序,从b的视角看1、2、1、4、1、2显然是无序的,这也是前缀匹配的规则的原因。
联合索引的最后一个字段还可以用于提高order by的效率,也就是在col1确定的情况下的, col2已经有序。也就是idx_c1_c2(col1, col2)这个联合索引适用于 where col1 = ? order by col2这种sql。
关于覆盖索引
在非聚集索引场景下需要进行回表,这个开销是非常大的,比如查询非聚集的后命中100条聚集索引,聚集索引的B+树分为3层,极端点来说,这100个聚集索引都在不同的数据页中,那么需要300次的磁盘IO,每次4ms,至少需要1s以上的执行时间。
覆盖索引就是如果索引本身的数据就是业务需要的数据,那么就无需回表,直接返回。性能提升可想而知。结合上面的红色部分描述,覆盖索引的性能是高于主键索引的。
但是命中覆盖索引的条件对满足业务需求和建立索引的要求是非常苛刻的。但是count()场景下是非常适合的,由于不需要获取行数据,也就是说select count() from table where col = ?,这里如果col列有建立普通索引,那么性能是非常好的。
关于倒排索引
一般我们都是通过索引找内容,倒排就是通过内容找索引。详细不表。

若有收获,就点个赞吧
0 人点赞
