- StringBuffer,StringBuilder区别是啥?什么是线程安全?如何保证线程安全?
- 功能一致一般都用于string连接,但前者通过在所有方法级别添加synchornized保证线程安全,后者线程不安全,但后者性能更好。也就是说,在方法内部申明局部变量的使用用StringBuilder,作为对象属性时使用StringBuffer。
- 线程安全是指:同一段代码,在单线程和多线程场景下,有可能出现不同且非预期的结果。那么这段代码就是线程不安全的。如何保证线程安全,对线程共享资源加锁。
- 什么是锁?死锁?
- 锁是一种保证线程安全的方式,从思想上分为乐观锁和悲观锁。各自都有实现,且在各个系统的中的表现方式不同。
- 乐观锁:获取共享资源后,认为共享资源不一定会被其他人篡改,所以不会对共享资源加锁,但使用时候会将预期值和实际值进行比较,如果一致认为假设成立,如果不一致则从头再走一遍逻辑,
- 如果共享资源冲突概率较少,那么乐观锁的效率会更高,极端情况下完全没有冲突,那么只比正常情况下多一次CAS比较而已。
- 如果冲突严重,那么乐观锁的效率会严重降低,极端情况下,每次CAS都导致重新执行。
- java中在unsafe类中,通过底层的cmpxchg指令实现了CAS机制,在其基础上,衍生出了juc包下的很多并发功能,包括Atomic类,ConcurrentHashMap类、AQS类以及基于其的ReentrantLock。
- mysql中,可以通过添加version字段自行实现CAS机制。
- 悲观锁:认为共享资源肯定会被人篡改,获取共享资源后加上独占锁,加锁之后即认为是单线程执行。
- 加悲观锁后,冲突概率就不影响锁的性能了,而需要关注的是加锁本身的消耗以及锁内代码执行的消耗。因为这两者消耗越大,锁外被hang住的线程就可能越多,系统吞吐量就越低。
- 加锁本身的消耗,我们无能为力,但可以知道的是在jdk7以后,java本身通过锁升级的方式进行了大量优化,然后第二点:锁内代码执行的消耗,是我们能控制的,所以需要我们在加锁时尽量减少锁内执行时间。
- java中悲观锁的实现是synchronized关键字,mysql的悲观锁实现是for update。
- 如何选择悲观锁和乐观锁,首先基于场景,锁冲突的概率高,用悲观锁,且尽量减少锁内消耗,否则用乐观锁,乐观锁比如ReentrantLock要注意的是finally释放。新手建议直接用synchronized。
synchronized的实现原理是什么?有了synchronized,还要volatile干什么?
- JVM分为两种实现方式,方法级别和代码块级别,前者通过ACC_SYNCHRONIZED修饰方法,后者通过指令monitorenter,monitorexit标记锁范围。但两者的底层机制是一致的。
- volatile的实现机制和synchronized完全不一样,开销更小,但特定场景下能达到synchronized一样的效果,所以他们的关系类似于,杀猪用杀猪刀(synchronized),切水果用水果刀(volatile),那么能不能用杀猪刀切水果,能的,但是没必要且成本更高。反过来水果刀能不能杀猪,不能,比如骨头怎么剁?所以特定场景下用volatile更合适。
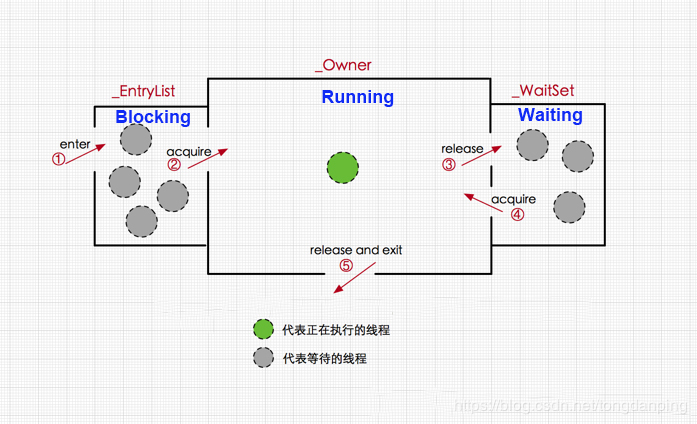
- synchronized机制:java中每个对象持有一个monitor(包括heap的对象和method area类对象),在执行monitorenter指令时,会获取该对象的monitor的持有线程_owner,如果为空:_owner=self,_recursions=1,如果获取到判断是否为自己,入是自己_recursions++,否则自旋一次(),如果还是没有获取到则调用part()方法挂起,进入waitSet(如果是公平锁则应该用queue结构保存),此外会有一个轮询机制不断获取该底线的monitor,一旦获取成功,从set中获取线程unpark继续执行。
- volatile机制:通过被volatile修饰的变量前后插入内存屏障(到达屏障前变量一定是最新值,从屏障出去之后数据一定已经更新到公共内存),从而保证各个线程之间的可见性。
此外volatile还有一个功能是synchronized做不到的:禁止指令重排序。什么叫指令重排序,意思就是jvm或者cpu在执行代码的顺序并不是我们写代码时候的顺序,如下两个场景,代码块1中,第一行和第二行在实际执行时可能存在互换,为什么可以互换,第三行能互换吗?答案显然是不能,为什么因为第三行依赖于前两行的结果。代码块2看起来只有一句看起开是原子的也存在重排序吗?存在的,jvm在执行new的时候需要的工作并不简单,至少分为三块:1、分配内存,2、对象初始化,3、将对象地址赋值给句柄。这三个操作中,23两步是可以互换的。
// 代码块1{int a = 1;int b = 2;int c = a + b;}// 代码块2{User user = new User();}
synchronized无法不能禁止指令重排序,那它是如何保证有序性的,这里就是概念上的误解,有序性是指可以保证多线程的有序执行,可以带来正确的结果,是从整体上来看的。
- synchronized的锁优化是怎么回事?
- 在jdk6之前,synchronized加锁和释放锁的机制都是通过原生操作系统来支持的,这里就涉及用户态(jvm)和内核态之间的切换,是非常耗时的操作(这里同理可以联想到线程创建也是耗时操作的原因也是如此),如果锁内逻辑很简单比如get、set之类的操作,那么可能加锁耗时比方法本身耗时还要高。
- 锁消除:通过JIT逃逸分析,如果认为该锁只有单线程执行,会进行锁消除,比如局部变量上使用synchronized或者使用StringBuffer、HashTable等线程安全类。
- 锁粗化:存在大量锁重入的时候,比如for循环或递归内加锁,jdk会进行锁粗化处理,防止不断对锁进行重入判断以及锁计数进行变更。
- 偏向锁:基于线程基本上不会出现冲突的实时,当线程获取对象的锁的时候,会在对象头中维护这个线程的ID,下一次获取锁时会比较当前线程ID和维护的ID是否一致,如果一致则取消在锁获取过程中执行不必要的CAS原子指令(cmpxchg也是内核操作),如果不一致则判断原线程是否存活,如果不存活,则更新对象头中的线程,偏向新的线程,如果存活,则升级到轻量级锁。
- 轻量级锁:类似于CAS的机制,如果线程没能抢到锁,不是立即阻塞,二是进行自旋不断获取锁,自旋和阻塞的区别在于:自旋优点是不调用syscall进行阻塞这种耗时操作,但持续占用cpu资源。自旋适用于锁冲突不严重的情况,不严重是指:竞争线程数量不多,锁内执行效率高。因为一旦冲突严重,就会造成不断自旋,且自旋期间持续占用cpu资源,导致系统性能下降。所以会设置一个自旋次数,比如100次,如果到次数依然获取不到锁,则升级到普通锁。
- 正常锁:见上面的synchronized的机制。
- 不考虑锁消除、锁粗化两个额外机制,偏向锁->自旋锁->正常锁,是一个不断升级的过程,且不会降级。
- Java并发包了解吗?
- 提供了很多并发工具
- Atomic系列:用于基础类型原子化的读写操作。
- ReentrantLock:可重入锁
- ConcurrentHashMap:通过CAS实现的线程安全的map
- CopyOnWriteArrayList:通过写时复制实现的线程安全list
- ExecutorService:线程池
- 那什么是fail-fast?什么是fail-safe?
- 快速失败:并发修改导致CME,机制:通过维护一个mode字段,每次添加或删除操作都会mode++,然后在hasNext会检查mode是否改变,比如HashMap、HashSet、ArrayList
- 失败安全:不会抛出CME,机制:每次修改复制一个集合。会导致生成大量无效对象。比如:CopyOnWriteArrayList、ConcurrentHashMap
- AQS是什么?
- AbstractQueuedSynchronizer,即队列同步器。它是构建锁或者其他同步组件的基础框架(如ReentrantLock、ReentrantReadWriteLock、Semaphore等),JUC并发包的作者(Doug Lea)期望它能够成为实现大部分同步需求的基础。它是JUC并发包中的核心基础组件。
- 数据库锁有了解么?行级锁?表级锁?共享锁?排他锁?gap锁?next-key lock?
- 行级锁、表级锁:被锁对象无法并行操作,锁作用的粒度不同。
- 共享锁、排他锁:锁的作用机制不同,共享锁也叫读锁,可读读并发,禁止读写并发。排它锁也叫独占锁、也叫写锁,禁止任何并发操作。
- gap锁:间隙锁,
- next-key lock:临键锁,
- 数据库锁和隔离级别有什么关系?
- 三读问题:
- 脏读:事务可以看到其他事务未提交的数据,而其他事务可能回滚,而导致不一致。
- 不可重复读:事务在多次获取同一行数据,有可能不一致。
- 幻读:事务在多次获取同一区间的数据,有可能不一致。
- Read Uncommit:
- 存在问题:三读问题都存在。
- 问题原因:读不加任何锁,写加X锁(整个事务周期)。
- Read Committed:
- 存在问题:存在不可重复读+幻读
- 问题原因:读的那一刻加S锁(解决脏读的原因:因为写操作会在整个事务周期内加X锁,所以一旦事务能获取到S锁说明该行数据没有其他事务在修改,所以也就不会读到其他事务未提交的数据),写加X锁(整个事务周期)。
- Repetable Read:
- 存在问题:不存在
- 问题原因:整个事务周期读加S锁(解决不可重复读的原因:S锁和X锁互斥,即保证了整个事务周期内没有其他事务能修改该行数据,所以保证每次读到的数据都是一样的。)+间隙锁(解决幻读的原因:主键索引和非主键索引都会形成gap区间,在gap区间加锁防止插入和删除),写加X锁(整个事务周期)。
- Serialized:表锁表,也分XS。并发最差。
- 三读问题:
- 数据库锁和索引有什么关系?
- 什么是聚簇索引?非聚簇索引?最左前缀是什么?B+树索引?联合索引?回表?
- 聚集索引:就是按照每张表的主键构造一个B+树,B+树的一个叶子几点中记录着表中一行记录的所有值。只要找到这个叶子节点也就得到了这条记录的所有值。
- 非聚集索引:也就是普通索引,B+树的叶子节点存储的是聚集索引,也就是主键。然后通过一次回表获取具体数据。
- 最左匹配:也叫头部匹配,在联合索引的场景下,只命中头部一个或多个索引,也能用到索引。
- 聚集索引就是按照每张表的主键构造一个B+树,B+树的一个叶子几点中记录着表中一行记录的所有值。只要找到这个叶子节点也就得到了这条记录的所有值。
- 分布式锁有了解吗?
- redis:利用setNX(set if not exsits)的原子特性(类似于单机下的compareAndSwap)实现多进程并发抢锁时只有一个进程能获取成功,并利用redis的key的可过期特性,保证进程因各种原因挂掉后也能释放锁。
- zookeeper:利用zk的临时有序节点特性:每当进程获取锁的时候,都会在相同锁下面创建一个临时有序节点,那么判断是否获取到锁就判断改节点是否是锁节点下最小的节点。如果节点删除或者断连一定时间,那么节点会删除,靠近最小的节点会晋升为最小节点,也就是获取到锁。
- 考虑网络故障、阻塞、单点、可重入。
- Redis怎么实现分布式锁?
RedisClient client = RedisClientFactory.init();public boolean tryLock(String key){try{if(client.setnx(key, 1){client.setExpire(key);return true;}} catch(Exception e){client.delKey(key);}return false;}public boolean unlock(String key){try{client.delKey(key);} catch(Exception e){client.delKey(key);}return false;}
- 为什么要用Redis?
- 存储数据、快速、特定数据结构(list、sorted set、booleanFilter)
- Redis和memcache区别是什么?
- 线程模型:单线程vs多线程
- 存储模型:
- 数据格式:多种数据格式vsKV
- 高可用:cluster vs 集群
- Zookeeper怎么实现分布式锁?
- 什么是Zookeeper?
- 什么是CAP?
- 什么是BASE?和CAP什么区别?
- CAP怎么推导?如何取舍?
- 分布式系统怎么保证数据一致性?
- 啥是分布式事务?分布式事务方案?
- 那么,最后了,来手写一个线程安全的单例吧?
public class Singleton<T>{private static volatile T instance;private Singleton(){}public Singleton getInstance(){if (instance == null){synchronized(String.class){if (instance == null){instance = new Singleton();}}}return instance;}}
- 不用synchronized和lock能实现线程安全的单例吗?
- 用枚举

若有收获,就点个赞吧
0 人点赞
