Redis 是什么
Redis 是一个 key-value 存储系统,它适合放一些频繁使用,比较热的数据。,redis 存储在内存里,redis 既可以用来做持久存储,也可以做缓存,而目前大多数公司的存储都是 mysql + redis,mysql 作为主存储,redis 作为辅助存储被用作缓存,加快访问读取的速度,提高性能
Redis 的11大风险
一、大 key
定义:
- 某个 key 所存储的内容很大,比如一个 key 存了1M的内容
- hash、set、list 中存储过多的元素
风险:
- 单个 size 太大,并发高容易把 redis 带宽打满
- 写大key会导致超时严重,甚至阻塞服务
应对:
- 把缓存内容做行列拆分
- 可以对存储元素按一定规则进行分类,分散存储到多个redis实例中
redis是单线程,操作bigkey比较耗时,那么阻塞 redis的可能性增大
二、hot key
定义:在一段时间内,该 key 的访问量远远高于其他的 key,导致大部分的访问流量在经过 proxy 分片之后,都集中访问到某一个 redis 实例上
风险:会导致某个 redis 机器负载偏高,甚至倍被击垮
应对:
- 将应用服务加本地缓存,而且最好单机本地缓存要能存放完该 key 的所有业务数据
- 在 proxy 加功能,实现主动发现及识别热点 key,并主动缓存其值
- 利用分片算法的特性,对 key 进行打散处理
三、缓存击穿
定义:某个并发高的 key 失效瞬间大量请求回源到 DB (存在的key瞬间失效)
风险:有可能 DB 被拖垮,影响其它业务
应对:设置超长有效期,并通过互斥锁串行回源 db (要注意缓存失效时间)public String get(key) {String value = redis.get(key);if (value == null) { //代表缓存值过期//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load dbif (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功value = db.get(key);redis.set(key, value, expire_secs);redis.del(key_mutex);} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可sleep(100);get(key); //重试}} else {return value;}}
四、缓存雪崩
情况一
定义:某个时间节点,大量 key 失效,导致大量请求从缓存中获取不到数据,而回源到 DB
风险:有可能 DB 瞬间被拖垮,影响其它业务
应对:
- 回源逻辑加锁,串行回源,保证同一个 key 只能单个线程回到db去查询
- 缓存数据的过期时间增加设置随机因子,防止同一时间大量数据过期现象发生
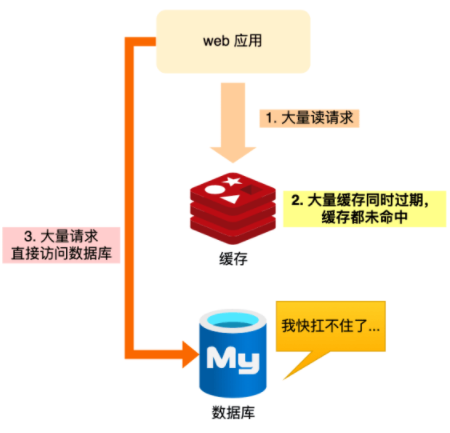
情况二
原因:redis 故障宕机
风险:有可能 DB 瞬间被拖垮,影响其它业务
应对:
- 服务熔断 或 请求限流机制(雪崩发生后)
- 构建 Redis 缓存高可靠集群(事前)

五、缓存穿透
概念:某个不存在的 key 一直被访问,不停回源 DB 查询
风险:增加 DB 负载,高并发可能搞挂 DB
应对:
- 缓存空值,将 null 变成一个值,但失效时间要短;
- 布隆过滤器(如果过滤器判断不存在,则一定不存在,不需要回源;如果判断存在,但不一定存在)
六、超时时间
key 的超时时间设置是否合理,功能测试时需要考虑七、冷数据
风险:大量冷数据读取时都需要先回到 DB 去查询,然后再写到 DB,响应时间长、DB 负载高
应对:缓存预热八、缓存故障
风险:当出现上述任何一种故障导致缓存及DB短时间无法恢复,如果没有兜底方案,则业务影响范围扩大
应对:制定明确的业务熔断降级策略九、LRU 策略
LRU
定义:从时间维度,把最近被访问到的 key 保留,把最近最少使用的 key 删除
(核心思想:数据最近被访问过,那么将来被访问几率也更高)
算法类型:
- allkeys-lru:所有key使用LRU算法淘汰
- allkeys-random:所有key使用随机淘汰
- volatile-random:随机回收设置过期时间的键
- volatile-ttl:设置了过期时间的key,根据过期时间淘汰,越早过期越早淘汰
- noeviction:默认策略,当内存达到设置的最大值时,所有申请内存的操作都会报错(如set、push等),只读操作如get命令可以正常执行
LFU
定义:从使用频率的维度去筛选,意味着最频繁被访问的数据将来最有可能被访问到,需要保留
(核心思想:过去数据被访问多,那么将来被访问的频率也更高)
算法类型:
- volatile-lfu:设置了过期时间的key使用LFU算法淘汰
- allkeys-lfu:所有key使用LFU算法
算法选择依据:
- volatile-lru、volatile-random 和 volatile-ttl 这三个淘汰策略使用的不是全量数据,有可能无法淘汰出足够的内存空间,在没有过期键或者没有设置超时属性的键情况下,这三种策略和 noeviction 差不多
- 使用 allkeys-lru 策略:当预期请求符合一个幂次请求(二八法则等),比如一部分的子集元素比其它元素被访问更多时,可以选择这个策略
- 使用 allkeys-random:循环连续的当问所有的键时,获取预期请求分布平均(所有元素被访问的概率都差不多)
- 使用 volatile-tll:要采取这个策略,缓存对象的TTL值最好有差异
相关配置项:
- maxmemory:配置 redis 存储数据时指定限制内存大小,比如100m。当缓存消耗的内存超过这个数值时,将触发数据淘汰。该数据配置为0时,表示缓存的数据量没有限制,即LRU功能不生效。64位的系统默认值时0,32位的系统默认内存限制为3GB
- mamemory_policy:触发系统淘汰后的淘汰策略
- maxmemory_samples:随机采样的精度,也就是随机取出key的数目,该数值配置越大,越接近于真实的LRU算法,但是数值越大,相应的消耗也大,对性能有一定影响,样本默认值为5
- lfu-log-factor:可以调整计数器counter的增长速度,lfu-log-factor 越大,counter 增长得越慢
- lfu-decay-time:是一个以分钟为单位得数值,可以调整counter得减少数量
十、持久化方
AOF:日志回放
RDB:内存快照十一、数据一致性
主要考虑内存值更新的入口考虑是否全面,要保证每个触发 DB 变更的入口都要更新缓存
DB 和缓存更新顺序的合理性

若有收获,就点个赞吧
0 人点赞
