什么是布隆过滤器?
不同的数据结构有不同的适用场景和优缺点,你需要仔细权衡自己的需求之后妥善适用它们,布隆过滤器就是践行这句话的代表
本质上布隆过滤器(Bloom filter)是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器的实现原理
隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
布隆过滤器会通过 3 个操作完成标记:
- 使用 N 个哈希函数分别对数据做哈希计算,得到 N 个哈希值
- 将第一步得到的 N 个哈希值对位图数组的长度取模,得到每个哈希值在位图数组的对应位置
- 将每个哈希值在位图数组的对应位置的值设置为 1
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器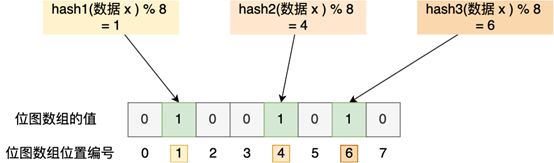
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时存在哈希冲突的可能性,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
支持删除么
传统的布隆过滤器并不支持删除操作。但是名为 Counting Bloom filter 的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除
布隆过滤器优点
- 空间效率和查询时间都远远超过一般的算法,布隆过滤器存储空间和插入 / 查询时间都是常数 O(k)
- 散列函数相互之间没有关系,方便由硬件并行实现
布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势
布隆过滤器缺点
误算率:随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣
-
布隆过滤器的应用场景
分布式数据库 Bigtable 以及 Hbase 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的 IO 次数。
- chrome 浏览器使用 bloom filter 识别恶意链接(能够用较少的存储空间表示较大的数据集合,简单的想就是把每一个 URL 都可以映射成为一个 bit)
- 文档存储检索系统也采用布隆过滤器来检测先前存储的数据
- 爬虫 URL 地址去重
- 解决缓存穿透问题

若有收获,就点个赞吧
0 人点赞
