数据仓库的实施和落地需要团队中不同成员的参与和配合,因此也需要各种各样的规范,其中最典型的就是表命名规范,规范的表命名能让使用者轻而易举地明白该表的作用和含义
设计表名要关注几点
1、数据分层
表命名规范的设计,本身其实是一件很简单的事情,但是它却依赖于不少其它外部信息,其中,数据分层是最为重要的地方。但是,一旦数据粉刺有了清晰的边界,表规范的设计就很会容易很多。关于数据分层可以了解 数据仓库的分层方法。
2、一定要有明确的界限
规范设计,表面上很简单,但是背后需要思考的地方却很多。比如说数据分层,dwd 层和 dwm 的明确界限是否能列举出来,直接决定了大家新建一张表时能否将它放在正确的位置的。同样,dwm 和 dws 好的明确界限是什么,dws 和 app 层的明确界限又是什么。
当这些设计和规范都存在模糊的时候,大家首先就会不明白该把表放在哪个分层里面,更不用说来确定命名了。
3、其它关注点
在数据分层之外,也有很多其它需要关注的点,比如:
- BG和部门的划分
- 业务线的划分
- 数据的更新日期
-
举个例子
如下图,以流程图的方式来展示,更加直观和易懂,图片侧重 dwm 层表的命名规范,其余命名是类似的道理:
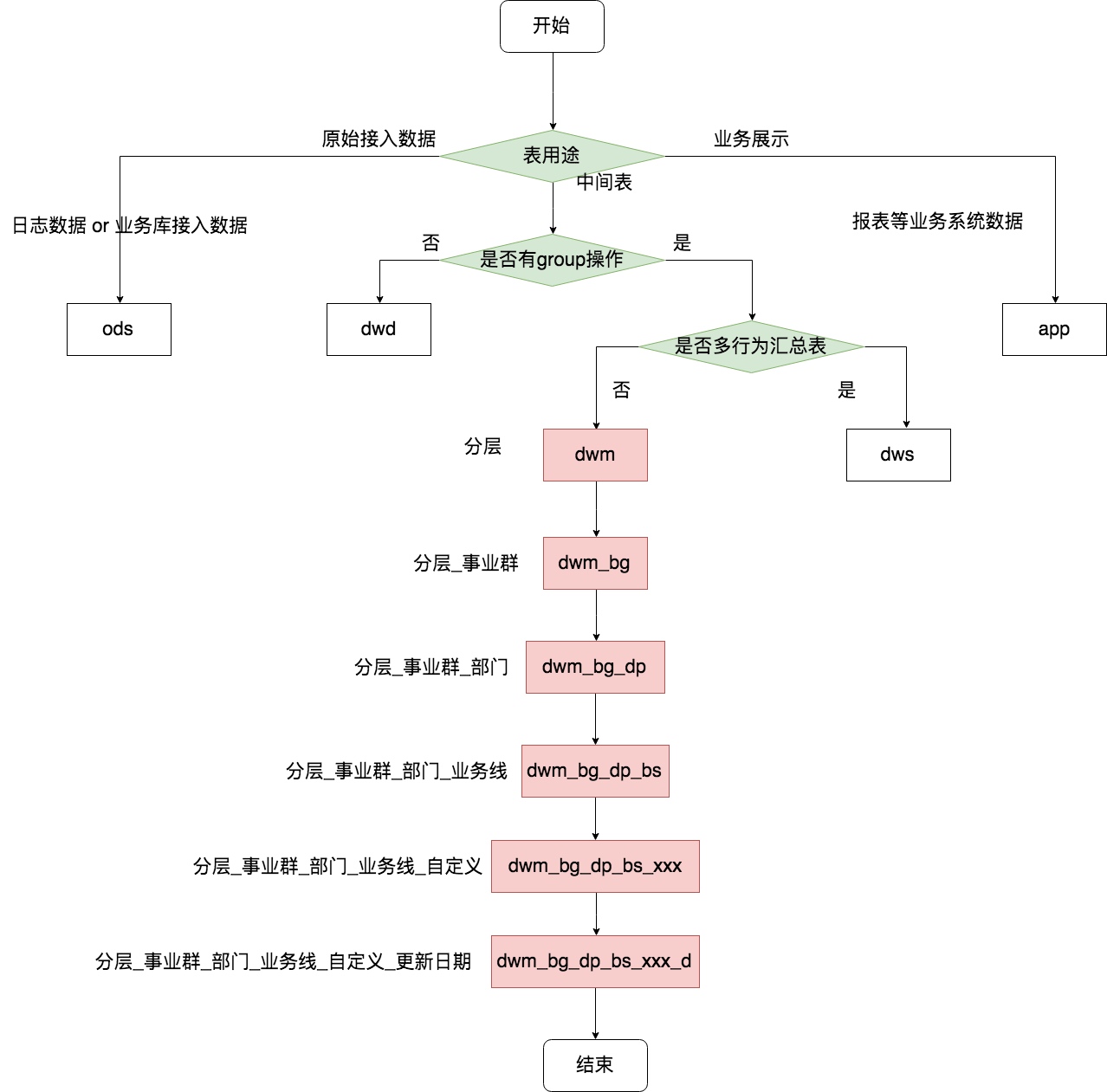
第一个判断条件是该表的用途,是中间表、原始日志还是业务展示用的表
- 如果该表被判断为中间表,就会走入下一个判断条件:表是否有 group 操作
- 通过是否有 group 操作来判断该表该划分在 dwd 层还是 dwm 和 dws 层
- 如果不是 dwd 层,则需要判断该表是否是多个行为的汇总表(即宽表)
- 最后再分别填上 事业群、部门、业务线、自定义名称 和 更新频率等信息即可
表命名,其实在很大程度上是对元数据描述的一种体现,表命名规范越完善,我们能从表名获取到的信息就越多。以上图为例,我们单纯从表中就能获得如下信息:

若有收获,就点个赞吧
0 人点赞
