性能场景是一个非常核心的概念。因为它会包括压力发起策略、业务模型、监控模型、性能数据、软硬件环境、分析模型等
性能曲线
学习性能的人,一定看吐过一张图:
在这个图中,定义了三条曲线、三个区域、两个点以及三个状态描述:
- 三条曲线:吞吐量的曲线(紫色)、使用率 / 用户数曲线(绿色)、响应时间曲线(深蓝色)
- 三个区域:轻负载区(Light Load)、重负载区(Heavy Load)、塌陷区(Buckle Zone)
- 两个点:最优并发用户数(The Optimum Number of Concurrent Users)、最大并发用户数(The Maximum Number of Concurrent Users)
- 三个状态描述:资源饱和(Resource Saturated)、吞吐下降(Throughput Falling)、用户受影响(End Users Effected)
这张图在很多地方都有被引用到,因为它真的很经典,这个图中有一些地方可能与实际存在误差
- 重负载区的资源饱和,和 TPS 达到最大值之间都不是在同样的并发用户数之下的
比如,当CPU资源使用率达到100%后,随着压力的增加,队列慢慢变长,但由于用户数增加的幅度会超过队列长度,所以TPS仍然会增加,即资源使用率达到饱和之后还有一段时间TPS才会达到上 - 吞吐量曲线不一定会出现下降的情况,在有些控制较好的系统中会维持水平
- 最优并发数这个点,通常只是一种感觉,并没有绝对的数据用来证明
- 最大并发数应该在更前面的位置,因为性能已经衰减了
在具体的项目实施中,一般会更关心服务端能处理的请求数即 TPS,而不是压力工具中的线程数
TPS和响应时间的关系
这里简化出另一个图形,以说明更直接一点的关系。如下所示: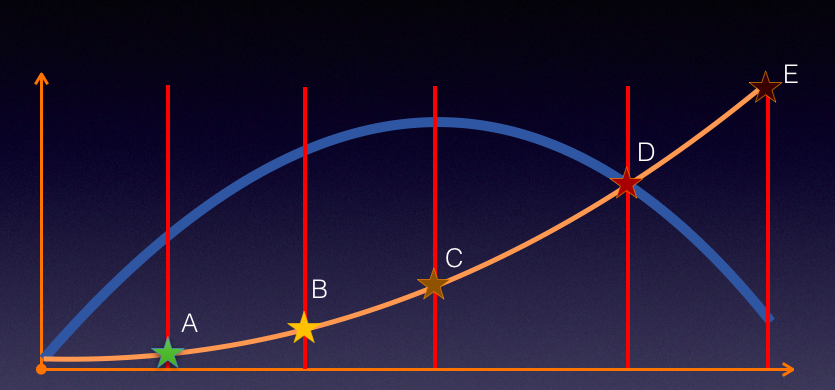
上图中蓝线表示 TPS,黄色表示响应时间
- 在 TPS 增加的过程中,响应时间一开始会处在较低的状态,也就是在 A 点之前
- 接着响应时间开始有些增加,直到业务可以承受的时间点 B,这时 TPS 仍然有增长的空间
- 再接着增加压力,达到 C 点时,达到最大 TPS
- 我们再接着增加压力,响应时间接着增加,但 TPS 会有下降(这里并不是必然的,有些系统在队列上处理得很好,会保持稳定的 TPS,然后多出来的请求都被友好拒绝)
- 最后,响应时间过长,达到了超时的程度
有些人将第一张图中的 Light load 对应为性能测试,Heavy Load 对应为负载测试,Buckle Zone 对应为压力测试……事实上,这是不合理的
用场景的定义来替换这些混乱的概念:
在具体场景的操作层面,只有场景中的配置才是具体可操作的。而通常大家认为的性能测试、负载测试、压力测试在操作的层面,只有压力工具中线程数的区别,其他的都在资源分析的层面,而分析在很多人的眼中,都不算测试
总之,在具体的性能项目中,性能场景是一个非常核心的概念。因为它会包括压力发起策略、业务模型、监控模型、性能数据(性能中的数据,一直都不把它称之为模型,因为在数据层面,测试并没有做过什么抽象的动作,只是使用)、软硬件环境、分析模型等。

若有收获,就点个赞吧
0 人点赞
