java 中常见的数据结构:数组、栈、队列、链表、图、哈希表、树、堆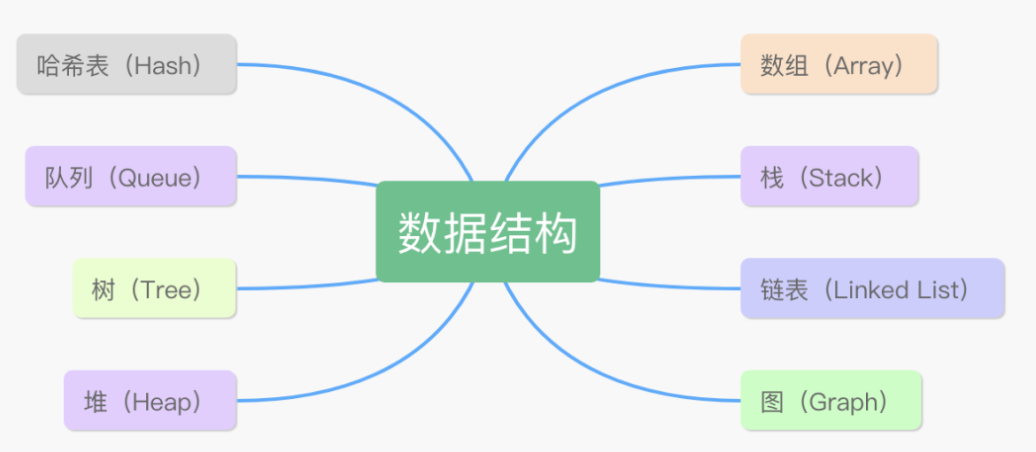
数组
特点:数据是连续的;随机访问速度快
缺点:数组的大小在创建后就确定了,无法扩容;数组只能存储一种类型的数据
数组中复杂一点的是多维数组和动态数组。Java 的 Collection 集合中提供了 ArrayList 和 Vector 来实现动态数组。
数组的下标寻址十分迅速,但计算机的内存是有限的,故数组的长度也是有限的,实际应用当中的数据往往十分庞大;而且无序数组的查找最坏情况需要遍历整个数组;后来人们提出了二分查找,二分查找要求数组的构造一定有序,二分法查找解决了普通数组查找复杂度过高的问题。任何一种数组无法解决的问题就是插入、删除操作比较复杂,因此,在一个增删查改比较频繁的数据结构中,数组不会被优先考虑。
链表
链表是一种递归的数据结构,它或者为空(null),或者是指向一个结点(node) 的引用,该节点还有一个元素和一个指向另一条链表的引用
单向链表
单向链表是链表的一种,它由节点组成,每个节点都包含下一个节点的指针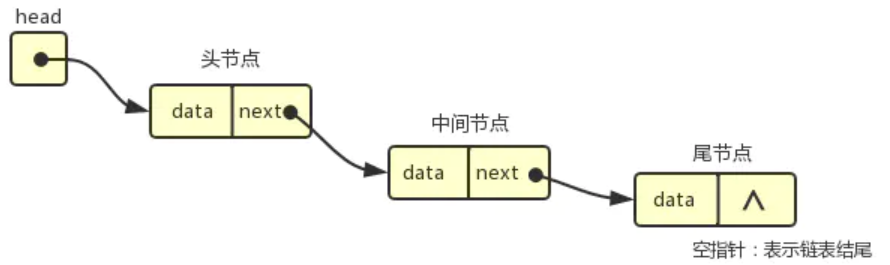
单链表的特点:节点的链接方向是单向的;相对于数组来说,单链表的的随机访问速度较慢,但是单链表删除/添加数据的效率很高。
双向链表
双向链表是链表的一种。双链表也是由节点组成,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
链表的优缺点
由于不必按照顺序的方式存储,链表在插入、删除的时候可以达到 O(1) 的时间复杂度(只需要重新指向引用即可,不需要像数组那样移动其他元素)。除此之外,链表还克服了数组必须预先知道数据大小的缺点,从而可以实现灵活的内存动态管理
优点
/**
- Java 实现的双向链表。
注:java自带的集合包中有实现双向链表,路径是:java.util.LinkedList */ public class DoubleLink
{ // 表头 private DNode
mHead; // 节点个数 private int mCount; // 双向链表“节点”对应的结构体 private class DNode
{ public DNode prev;public DNode next;public T value;public DNode(T value, DNode prev, DNode next) {this.value = value;this.prev = prev;this.next = next;}
}
// 构造函数 public DoubleLink() {
// 创建“表头”。注意:表头没有存储数据!mHead = new DNode<T>(null, null, null);mHead.prev = mHead.next = mHead;// 初始化“节点个数”为0mCount = 0;
}
// 返回节点数目 public int size() {
return mCount;
}
// 返回链表是否为空 public boolean isEmpty() {
return mCount==0;
}
// 获取第index位置的节点 private DNode
getNode(int index) { if (index<0 || index>=mCount)throw new IndexOutOfBoundsException();// 正向查找if (index <= mCount/2) {DNode<T> node = mHead.next;for (int i=0; i<index; i++)node = node.next;return node;}// 反向查找DNode<T> rnode = mHead.prev;int rindex = mCount - index -1;for (int j=0; j<rindex; j++)rnode = rnode.prev;return rnode;
}
// 获取第index位置的节点的值 public T get(int index) {
return getNode(index).value;
}
// 获取第1个节点的值 public T getFirst() {
return getNode(0).value;
}
// 获取最后一个节点的值 public T getLast() {
return getNode(mCount-1).value;
}
// 将节点插入到第index位置之前 public void insert(int index, T t) {
if (index==0) {DNode<T> node = new DNode<T>(t, mHead, mHead.next);mHead.next.prev = node;mHead.next = node;mCount++;return ;}DNode<T> inode = getNode(index);DNode<T> tnode = new DNode<T>(t, inode.prev, inode);inode.prev.next = tnode;inode.next = tnode;mCount++;return ;
}
// 将节点插入第一个节点处。 public void insertFirst(T t) {
insert(0, t);
}
// 将节点追加到链表的末尾 public void appendLast(T t) {
DNode<T> node = new DNode<T>(t, mHead.prev, mHead);mHead.prev.next = node;mHead.prev = node;mCount++;
}
// 删除index位置的节点 public void del(int index) {
DNode<T> inode = getNode(index);inode.prev.next = inode.next;inode.next.prev = inode.prev;inode = null;mCount--;
}
// 删除第一个节点 public void deleteFirst() {
del(0);
}
// 删除最后一个节点 public void deleteLast() {
del(mCount-1);
栈
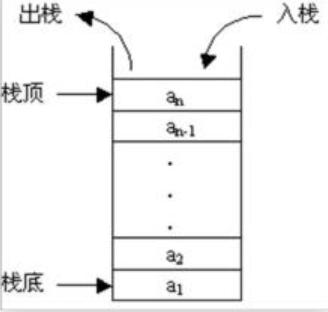
栈的介绍
栈是一种线性存储结构,它有以下几个特点:
- 栈中数据是按照”后进先出“(LIFO, Last In First Out)方式进出栈的
- 向栈中添加/删除数据时,只能从栈顶进行操作
栈通常包括的三种操作:push、peek、pop
- push — 向栈中添加元素
- peek — 返回栈顶元素
- pop — 返回并删除栈顶元素的操作
栈的 Java 实现
Java 中有两种方式可以实现栈
import java.lang.reflect.Array;
public class GeneralArrayStack
private static final int DEFAULT_SIZE = 12;private T[] mArray;private int count;public GeneralArrayStack(Class<T> type) {this(type, DEFAULT_SIZE);}public GeneralArrayStack(Class<T> type, int size) {// 不能直接使用mArray = new T[DEFAULT_SIZE];mArray = (T[]) Array.newInstance(type, size);count = 0;}// 将val添加到栈中public void push(T val) {mArray[count++] = val;}// 返回“栈顶元素值”public T peek() {return mArray[count-1];}// 返回“栈顶元素值”,并删除“栈顶元素”public T pop() {T ret = mArray[count-1];count--;return ret;}// 返回“栈”的大小public int size() {return count;}// 返回“栈”是否为空public boolean isEmpty() {return size()==0;}// 打印“栈”public void PrintArrayStack() {if (isEmpty()) {System.out.printf("stack is Empty\n");}System.out.printf("stack size()=%d\n", size());int i=size()-1;while (i>=0) {System.out.println(mArray[i]);i--;}}public static void main(String[] args) {String tmp;GeneralArrayStack<String> astack = new GeneralArrayStack<String>(String.class);// 将10, 20, 30 依次推入栈中astack.push("10");astack.push("20");astack.push("30");// 将“栈顶元素”赋值给tmp,并删除“栈顶元素”tmp = astack.pop();System.out.println("tmp="+tmp);// 只将“栈顶”赋值给tmp,不删除该元素.tmp = astack.peek();System.out.println("tmp="+tmp);astack.push("40");astack.PrintArrayStack(); // 打印栈}
}
<a name="aUayr"></a>#### Collection 集合自带的栈实现```javapackage structure;import java.util.Stack;public class StackTest {public static void main(String[] args) {int tmp=0;Stack<Integer> astack = new Stack<Integer>();// 将10, 20, 30 依次推入栈中astack.push(10);astack.push(20);astack.push(30);// 将“栈顶元素”赋值给tmp,并删除“栈顶元素”tmp = astack.pop();// 只将“栈顶”赋值给tmp,不删除该元素.tmp = (int)astack.peek();astack.push(40);while(!astack.empty()) {tmp = (int)astack.pop();System.out.printf("tmp=%d\n", tmp);}}}
队列
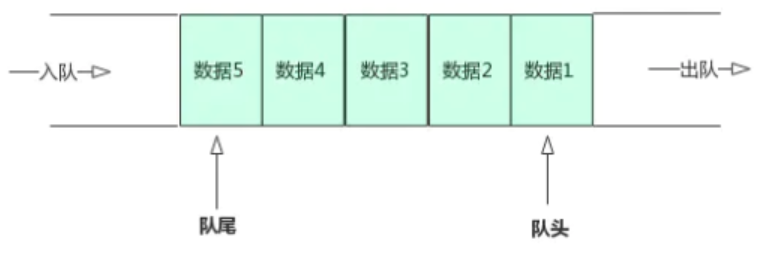
队列的介绍
队列是一种线性存储结构,它有以下几个特点:
- 队列中数据是按照”先进先出“(FIFO, First-In-First-Out)方式进出队列的
- 队列只允许在”队首”进行删除操作,而在”队尾”进行插入操作
队列的 Java 实现
Java 中有两种方式可以实现队列:
// java : 数组实现“队列”,只能存储int数据。 public class ArrayQueue { private int[] mArray; private int mCount;
public ArrayQueue(int sz){mArray = new int[sz];mCount = 0;}// 将val添加到队尾public void add(int val){mArray[mCount++] = val;}// 返回队首元素public int front(){return mArray[0];}// 返回队首元素的值,并且删除队首元素public int pop(){int ret = mArray[0];mCount--;for(int i = 1;i <= mCount;i++){mArray[i-1] = mArray[i];}return ret;}// 返回队列的大小public int size(){return mCount;}// 返回队列是否为空public boolean isEmpty(){return size() == 0;}public static void main(String[] args) {int tmp = 0;ArrayQueue astck = new ArrayQueue(12);// 将10、20、30依次入队列astck.add(10);astck.add(20);astck.add(30);// 打印队首元素并删除队首元素tmp = astck.pop();System.out.println(tmp);// 打印队首元素 但不删除tmp = astck.front();System.out.println(tmp);astck.add(40);while (!astck.isEmpty()) {System.out.printf("size()=%d\n", astck.pop());}}
}
<a name="G7tSN"></a>## 二叉查找树二叉查找树(Binary Search Tree),又被称为二叉搜索树<br />它是特殊的二叉树,具有以下特点:- 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值- 任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值- 任意节点的左、右子树也分别为二叉查找树- 没有键值相等的节点<a name="aib7a"></a>### 二叉查找树的 java 实现定义一个二叉查找树:```javapublic class BSTree<T extends Comparable<T>> {private BSTNode<T> mRoot; // 根结点public class BSTNode<T extends Comparable<T>> {T key; // 关键字(键值)BSTNode<T> left; // 左孩子BSTNode<T> right; // 右孩子BSTNode<T> parent; // 父结点public BSTNode(T key, BSTNode<T> parent, BSTNode<T> left, BSTNode<T> right) {this.key = key;this.parent = parent;this.left = left;this.right = right;}}......}
前序遍历
若二叉树非空,则执行以下操作:
- 访问根结点
- 先序遍历左子树
- 先序遍历右子树
```java
// 前序遍历
private void preOrder(BSTNode
tree) { if(tree != null) {
} }System.out.print(tree.key + " ");preOrder(tree.left);preOrder(tree.right);
public void preOrder() { preOrder(mRoot); }
<a name="QNjDb"></a>### 中序遍历若二叉树非空,则执行以下操作:1. 中序遍历左子树2. 访问根结点3. 中序遍历右子树```java// 中序遍历private void inOrder(BSTNode<T> tree) {if(tree != null) {inOrder(tree.left);System.out.print(tree.key+" ");inOrder(tree.right);}}public void inOrder() {inOrder(mRoot);}
后序遍历
若二叉树非空,则执行以下操作:
- 后序遍历左子树
- 后序遍历右子树
- 访问根结点
```java
// 后序遍历
private void postOrder(BSTNode
tree) { if(tree != null) {
} }postOrder(tree.left);postOrder(tree.right);System.out.print(tree.key+" ");
public void postOrder() { postOrder(mRoot); }
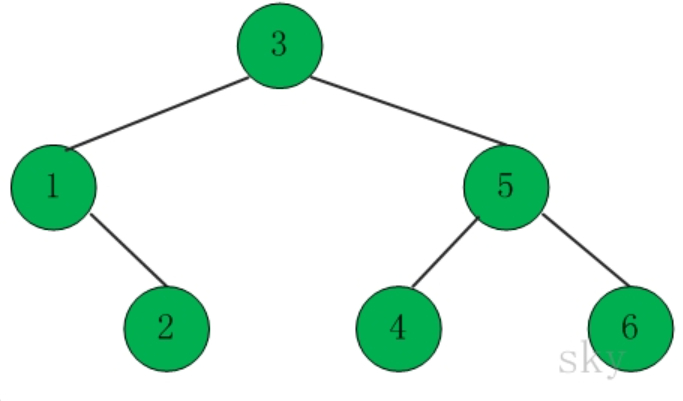<br />这颗树的前中后序的遍历结果:- 前序遍历结果:3 1 2 5 4 6- 中序遍历结果:1 2 3 4 5 6- 后序遍历结果:2 1 4 6 5 3<a name="d3SBT"></a>### 查找键值为 key 的节点递归实现:```java// 查找二叉树中键值为key的节点private BSTNode<T> search(BSTNode<T> x, T key) {if (x==null)return x;int cmp = key.compareTo(x.key);if (cmp < 0)return search(x.left, key);else if (cmp > 0)return search(x.right, key);elsereturn x;}public BSTNode<T> search(T key) {return search(mRoot, key);}
查找二叉树的最大节点
查找最大结点:返回 tree 为根结点的二叉树的最大结点
private BSTNode<T> maximum(BSTNode<T> tree) {if (tree == null)return null;while(tree.right != null)tree = tree.right;return tree;}public T maximum() {BSTNode<T> p = maximum(mRoot);if (p != null)return p.key;return null;}
查找二叉树的最小节点
查找最小结点:返回 tree 为根结点的二叉树的最小结点
private BSTNode<T> minimum(BSTNode<T> tree) {if (tree == null)return null;while(tree.left != null)tree = tree.left;return tree;}public T minimum() {BSTNode<T> p = minimum(mRoot);if (p != null)return p.key;return null;}
平衡二叉树(AVL 树)
AVL 树的特点:任何节点的两个子树的高度最大差别为1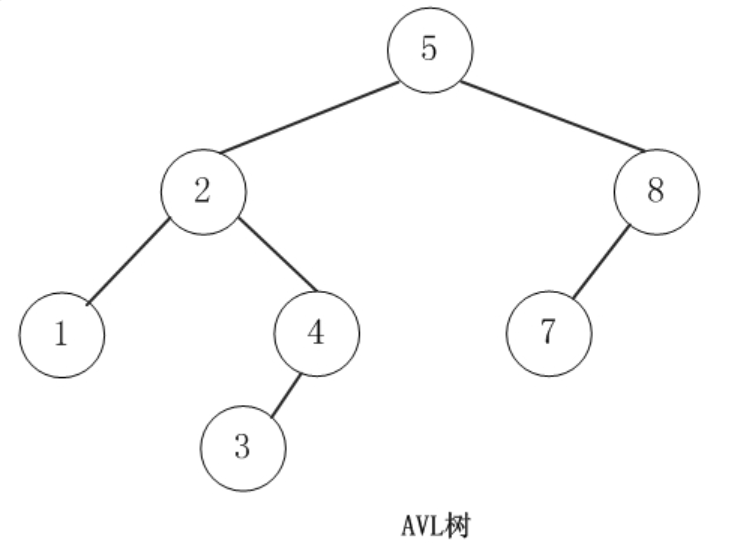
平衡二叉树的难点在于,当删除或者增加节点的情况下,如何通过左旋或者右旋的方式来保持左右平衡。
Java 中最常见的平衡二叉树就是红黑树,节点是红色或者黑色,通过颜色的约束来维持着二叉树的平衡:
- 每个节点都只能是红色或者黑色
- 根节点是黑色
- 每个叶节点(NIL 节点,空节点)是黑色的。
- 如果一个节点是红色的,则它两个子节点都是黑色的。也就是说在一条路径上不能出现相邻的两个红色节点。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
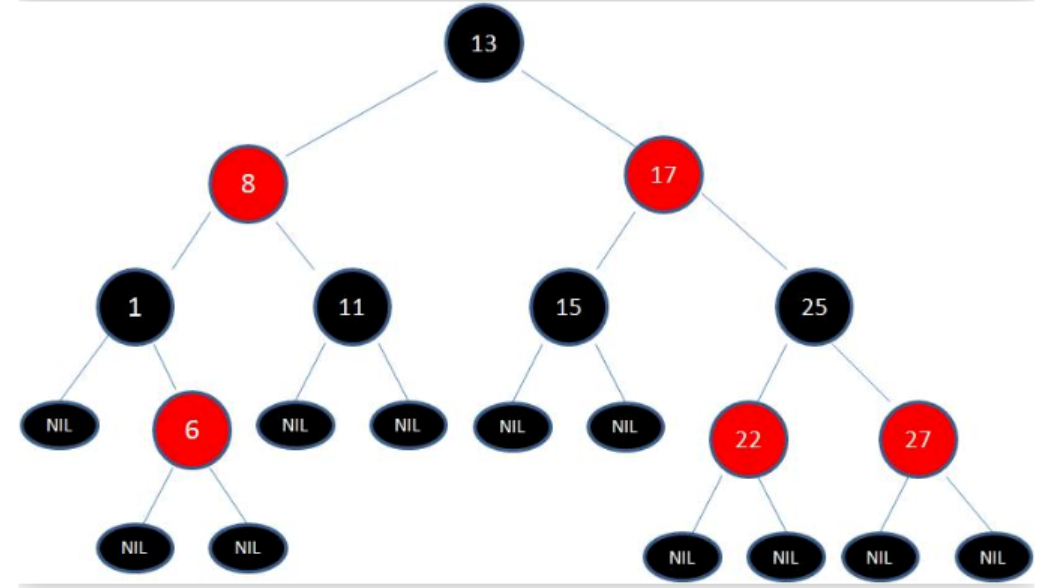
哈夫曼树
Huffman Tree,中文名是哈夫曼树或霍夫曼树,它是最优二叉树
定义:给定 n 个权值作为 n 个叶子结点,构造一棵二叉树,若树的带权路径长度达到最小,则这棵树被称为哈夫曼树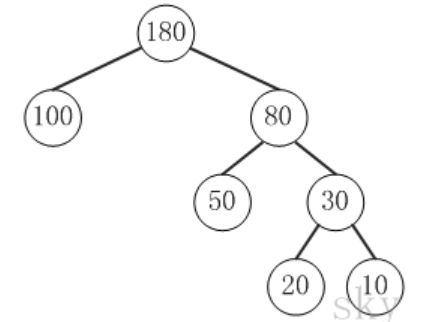
路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为 L-1
例子:100和80的路径长度是1,50 和 30 的路径长度是2,20 和 10 的路径长度是 3
结点的权及带权路径长度:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
例子:节点 20 的路径长度是 3,它的带权路径长度 = 路径长度 权 = 3 20 = 60
树的带权路径长度:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为 WPL
例子:示例中,树的 WPL= 1100 + 250 + 320 + 310 = 100 + 100 + 60 + 30 = 290
二叉堆
二叉堆是完全二元树或者是近似完全二元树,按照数据的排列方式可以分为两种:最大堆和最小堆
- 最大堆:父结点的键值总是大于或等于任何一个子节点的键值
- 最小堆:父结点的键值总是小于或等于任何一个子节点的键值
二叉堆一般都通过”数组”来实现,下面是数组实现的最大堆和最小堆的示意图:
二叉堆的添加
假设在最大堆 [90,80,70,60,40,30,20,10,50] 种添加 85,需要执行的步骤如下: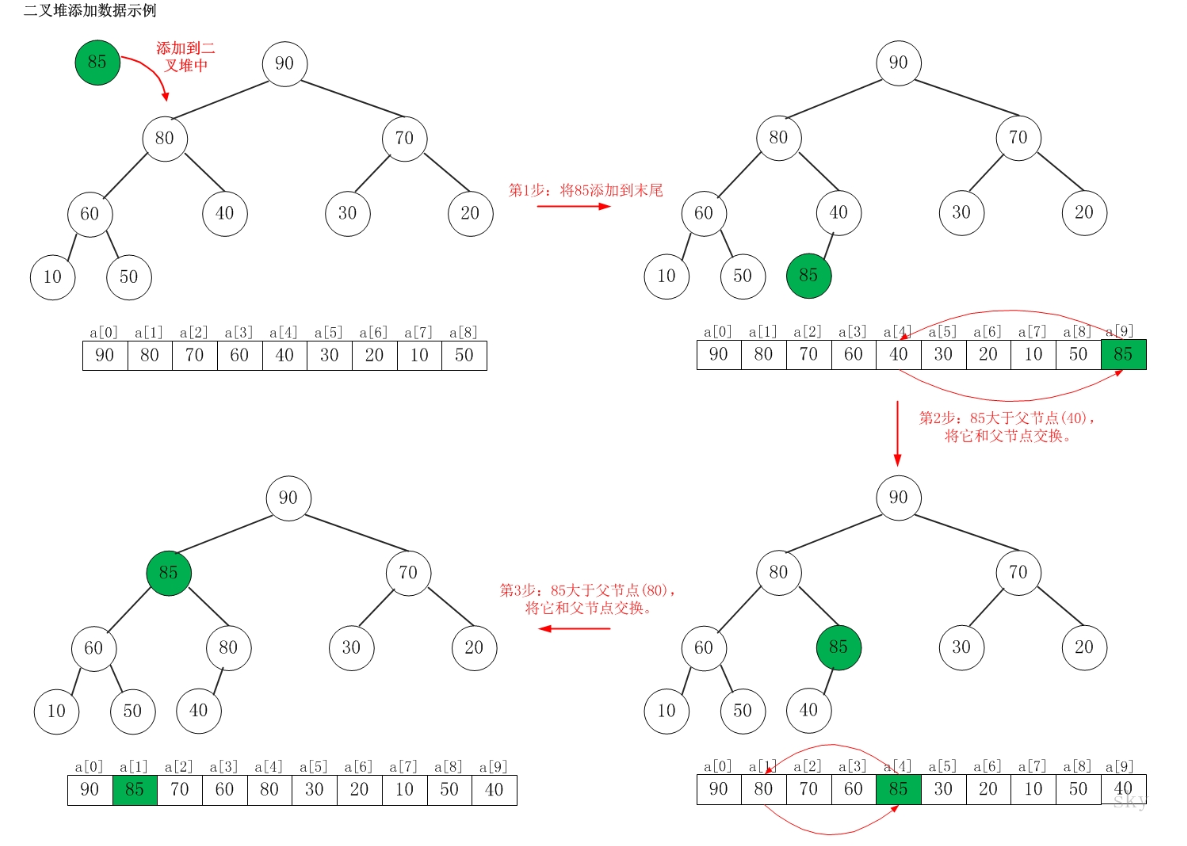
当向最大堆中添加数据时:
- 先将数据加入到最大堆的最后
- 然后尽可能把这个元素往上挪,直到挪不动为止
将 85 添加到 [90,80,70,60,40,30,20,10,50] 中后,最大堆变成了 [90,85,70,60,80,30,20,10,50,40]
二叉堆的删除
假设从最大堆 [90,85,70,60,80,30,20,10,50,40] 中删除 90,需要执行的步骤如下: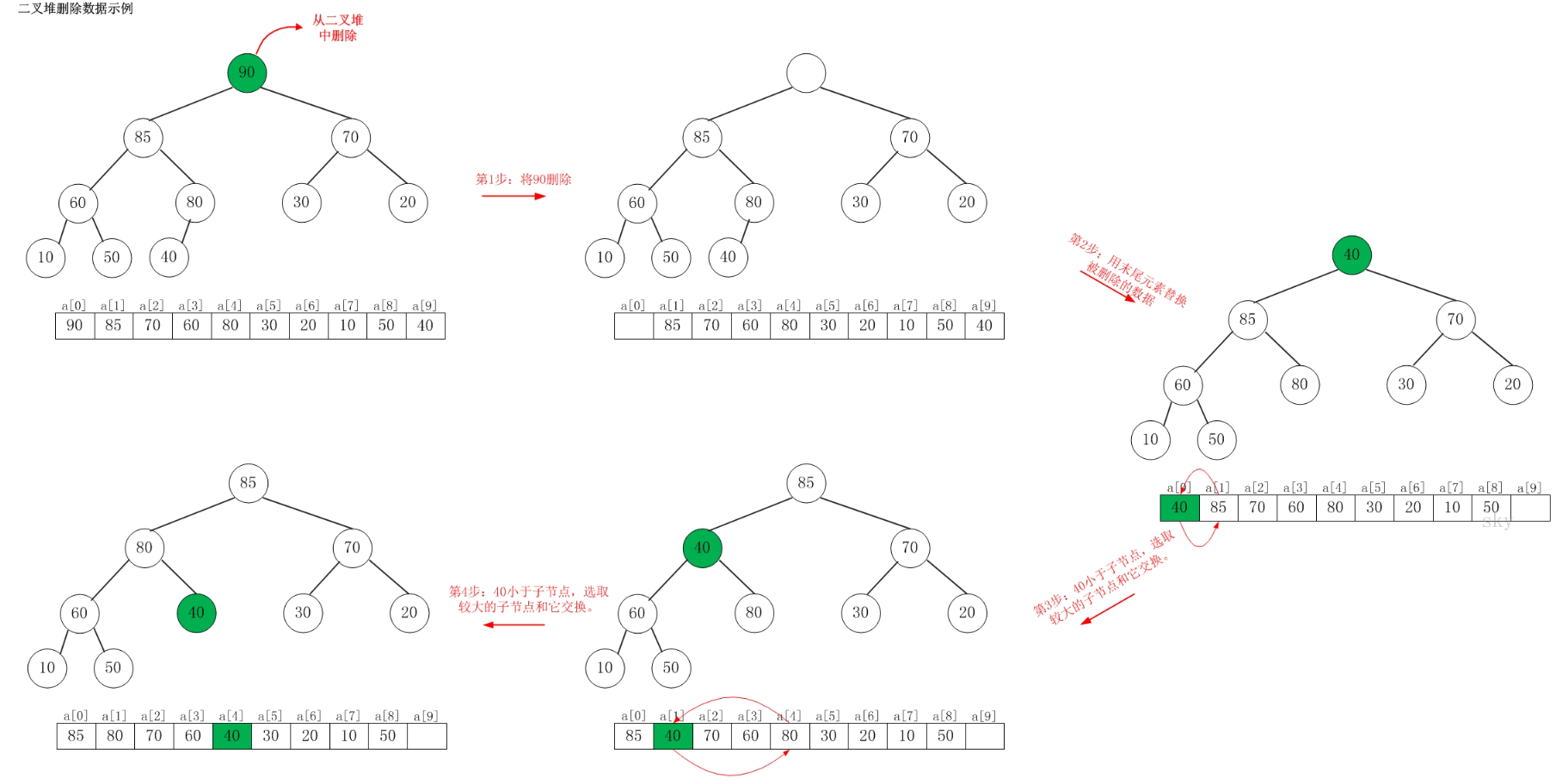
如上图所示,当从最大堆中删除数据时:先删除该数据,然后用最大堆中最后一个的元素插入这个空位;接着,把这个“空位”尽量往上挪,直到剩余的数据变成一个最大堆。
从 [90,85,70,60,80,30,20,10,50,40] 删除 90 之后,最大堆变成了 [85,80,70,60,40,30,20,10,50]
图
图(graph) 是由一些点(vertex) 和这些点之间的连线(edge) 所组成的;其中,点通常被成为”顶点(vertex)”,而点与点之间的连线则被成为”边或弧”(edege)。通常记为,G=(V,E)。
根据边是否有方向,将图可以划分为:无向图和有向图
邻接点和度
邻接点:一条边上的两个顶点叫做邻接点。在有向图中,除了邻接点之外;还有”入边”和”出边”的概念
度:在无向图中,某个顶点的度是邻接到该顶点的边(或弧)的数目。在有向图中,度还有”入度”和”出度”之分
路径和回路
路径:如果顶点(Vm) 到顶点(Vn) 之间存在一个顶点序列。则表示 Vm 到 Vn 是一条路径。
路径长度:路径中”边的数量”
简单路径:若一条路径上顶点不重复出现,则是简单路径
回路:若路径的第一个顶点和最后一个顶点相同,则是回路
简单回路:第一个顶点和最后一个顶点相同,其它各顶点都不重复的回路则是简单回路
连通图和连通分量
连通图:对无向图而言,任意两个顶点之间都存在一条无向路径,则称该无向图为连通图。 对有向图而言,若图中任意两个顶点之间都存在一条有向路径,则称该有向图为强连通图
连通分量:非连通图中的各个连通子图称为该图的连通分量
图的存储结构
邻接矩阵:是指用矩阵来表示图。它是采用矩阵来描述图中顶点之间的关系(及弧或边的权)
邻接表:邻接表是图的一种链式存储表示方法。它是改进后的”邻接矩阵”,它的缺点是不方便判断两个顶点之间是否有边,但是相对邻接矩阵来说更省空间
图的深度优先搜索
图的深度优先搜索(Depth First Search)思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点 v 出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和 v 有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
深度优先搜索是一个递归的过程
无向图的深度优先搜索
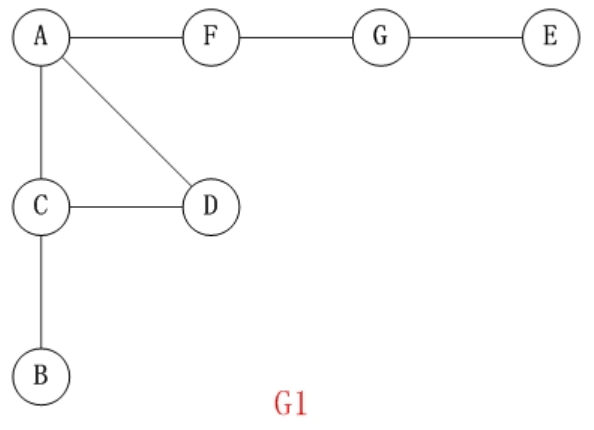
对上面的图 G1 进行深度优先遍历,从顶点 A 开始:
- 访问 A
- 访问 A 的邻接点 C (在第1步访问 A 之后,接下来应该访问的是 A 的邻接点,即 “C,D,F” 中的一个。但在本文的实现中,顶点 ABCDEFG 是按照顺序存储,C 在 “D和F” 的前面,因此,先访问 C)
- 访问 C 的邻接点 B
- 访问 C 的邻接点 D (在第3步访问了 C 的邻接点 B 之后,B 没有未被访问的邻接点;因此,返回到访问 C 的另一个邻接点 D)
- 访问 A 的邻接点 F
- 访问( F 的邻接点) G
- 访问 G 的邻接点 E
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
有向图的深度优先搜索

对上面的图 G2 进行深度优先遍历,从顶点 A 开始:
- 访问 A
- 访问 B (在访问了 A 之后,接下来应该访问的是 A 的出边的另一个顶点,即顶点 B)
- 访问 C
- 访问 E (接下来访问 C 的出边的另一个顶点,即顶点 E)
- 访问 D
- 访问 F (接下应该回溯”访问 A 的出边的另一个顶点 F”)
- 访问 G
因此访问顺序是:A -> B -> C -> E -> D -> F -> G
图的广度优先搜索
广度优先搜索算法(Breadth First Search),又称为”宽度优先搜索”或”横向优先搜索”,简称 BFS
思想:从图中某顶点v出发,在访问了 v 之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止
无向图的广度优先搜索
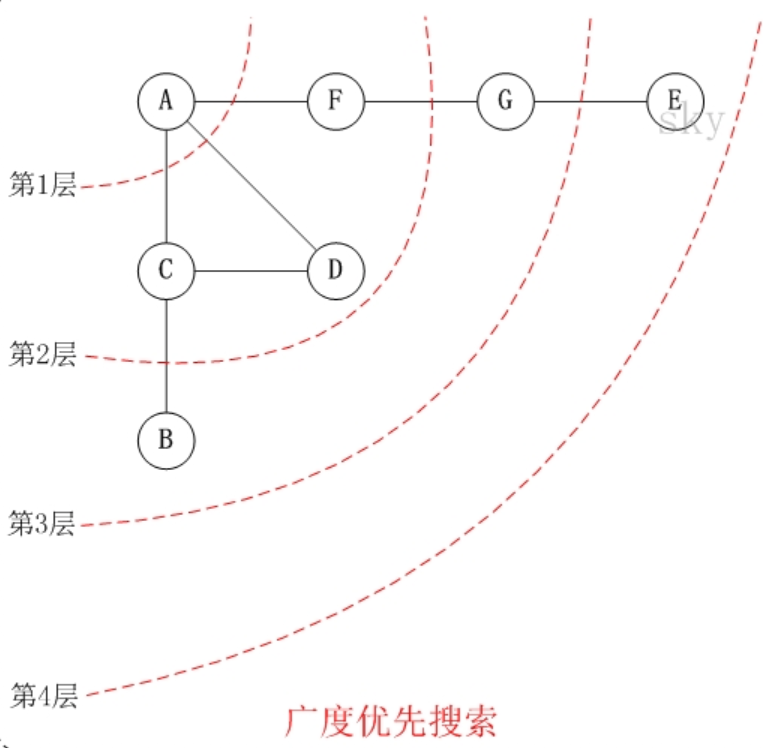
对上图进行广度优先遍历,从顶点 A 开始:
- 访问 A
- 依次访问 C,D,F
- 依次访问 B,G (在第2步访问完 C,D,F 之后,再依次访问它们的邻接点。首先访问 C 的邻接点 B,再访问 F 的邻接点 G)
- 访问 E
因此访问顺序是:A -> C -> D -> F -> B -> G -> E
有向图的广度优先搜索
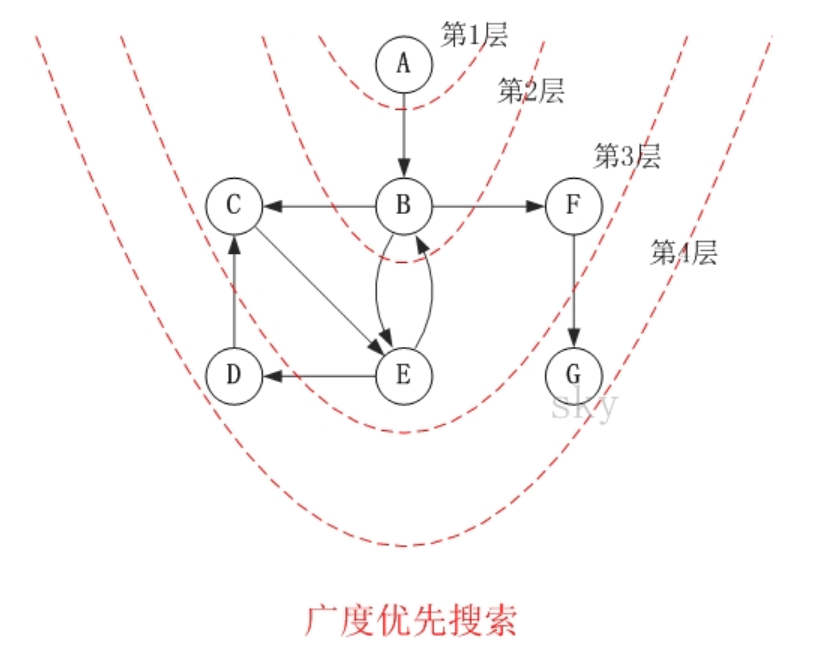
对上图进行广度优先遍历,从顶点 A 开始:
- 访问 A
- 访问 B
- 依次访问 C,E,F ( 在访问了 B 之后,接下来访问B的出边的另一个顶点,即 C,E,F)
- 依次访问 D,G
因此访问顺序是:A -> B -> C -> E -> F -> D -> G

若有收获,就点个赞吧
0 人点赞
