(1)前序:
数据页分裂的过程,在不停的往表里添加数据时候,会形成一个个的数据页,如果主键不是自增的,可能会有一个数据行的移动过程,保证下一个数据页的主键值都大于上一个数据页的主键值。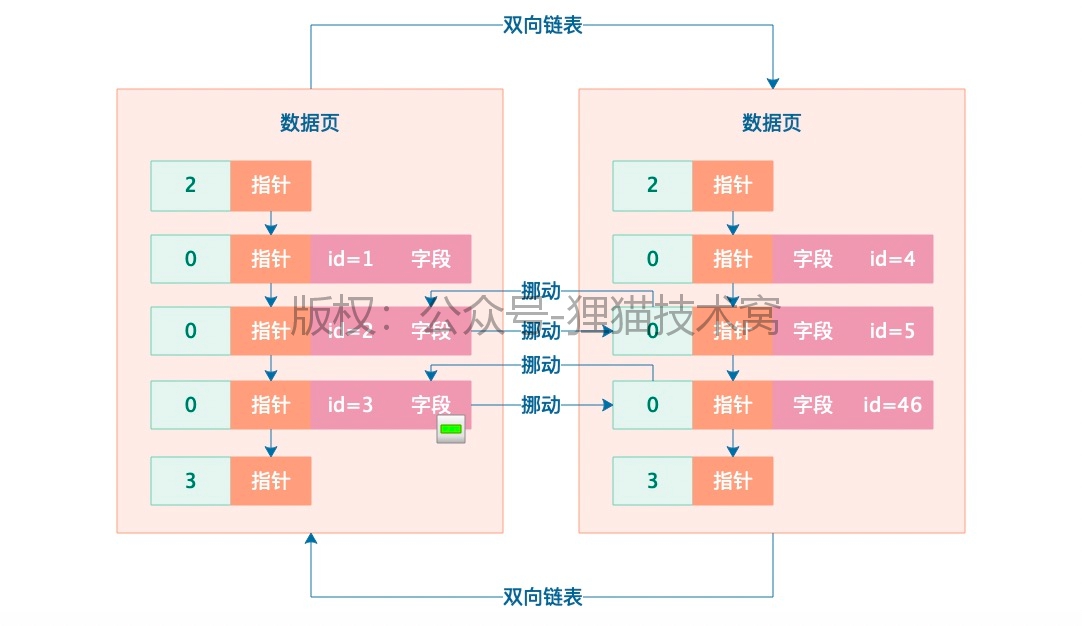
(2)主键索引:使用页目录查询数据不能避免全表扫描,这里使用索引目录进行查询
假设我们多个数据页,然后我们想要根据主键来查询数据,那么直接查询是不行的,因为不知道主键到底在哪里,假设要搜索id=4的数据,但是怎么知道在那个数据页?没有任何证据可以知道是在哪个数据页,所以假设是这样的话,只能全表扫描了,从第一个数据页开始,每个数据页都会进入页目录里查找主键,最坏的情况,所有数据页都得扫描一遍。效率很低。
所以就需要针对主键设计一个索引,针对主键的索引实际上就是主键目录,就是把每个数据页的页号,还有数据页里最小的主键值放在一起,组成一个索引目录。 有了主键目录就方便了,直接可以到主键目录里去搜索,比如要找id=3的数据,此时就会跟每个数据页的最小主键来比,首先id=3大于数据页2里的最小主键值1,接着小于数据页8里的最小主键值4,所以既然如此,直接可以定位到id=3的数据一定是在数据页2里的。
假设有很多的数据页,在主键目录里就会有很多的数据页和最小主键值,此时你完全可以根据二分查找的方式来找你要找的id到底在哪个数据页里。所以效率很高,类似上面的主键目录,可以认为是主键索引。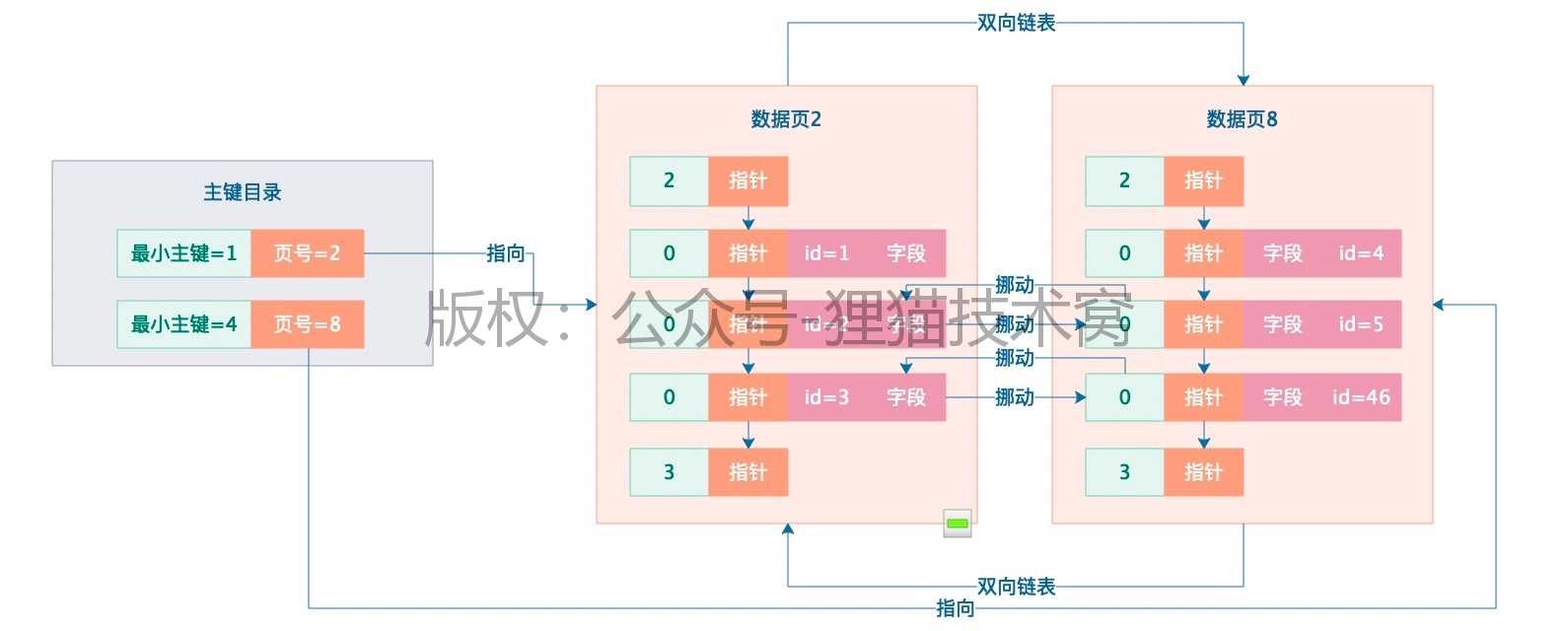
(3)总结:
数据页都是连续数据放在很多磁盘文件里的,所以只要能够根据主键索引定位到数据所在的数据页,假设我们有别的方式存储数据页跟磁盘文件的对应关系,这样就可以找到一个磁盘文件,而且我们假设知道数据页在磁盘文件里的offset偏移量,此时就可以直接通过随机读的方式定位到磁盘文件的某个offset偏移量的位置,然后读取连续的数据页。
索引页存放的是数据页号和数据页中最小主键id,在多个数据页 根据主键id查询数据的情况下,会使用二分查找在索引页中 定位到主键id对应的数据页,然后二分查找数据页内的主键id对应的行数据,这是在有主键id索引的情况下。
知识点:
通过二分定位到索引页,然后在索引页对应的数据页继续二分查找,索引页存放的是数据页页号 和 数据页对应的最小索引值,且数据页都是按照顺序排放的,下一页的数据一定都比上一页的数据值大。
关键===>索引页在内存中是有缓存的,先根据索引页定位索引页b+树的叶子节点的数据页,在数据页的主键目录定位槽位后进行二分查找行数据。索引页和页目录的关系;
首先每个数据页都有一个页目录,每个页目录里是数据行的主键与槽位的映射关系,每个槽位放一组主键,如果没有主键就没法根据槽位进行二分查找定位到数据行,只能遍历一一获取,然后索引页是根据数据页页号与数据页最小主键id组成的映射关系,根据主键可以知道数据在哪个数据页,知道哪个数据页才能根据页目录找到数据行。
索引页是用于管理数据页的,而页目录是用于管理数据页里的数据行的。
B+树的中间节点只记录它下一个节点的索引页的页号和对应的最小主键id,叶子节点的索引页记录了数据页的页号和对应最小主键值。
通过主键查询,先二分查找找到叶子节点的索引页,然后二分查找这个索引页得到所在的数据页,然后找到数据页,通过页目录,二分查找找到对应槽位,然后遍历
槽位中的数据得到数据行。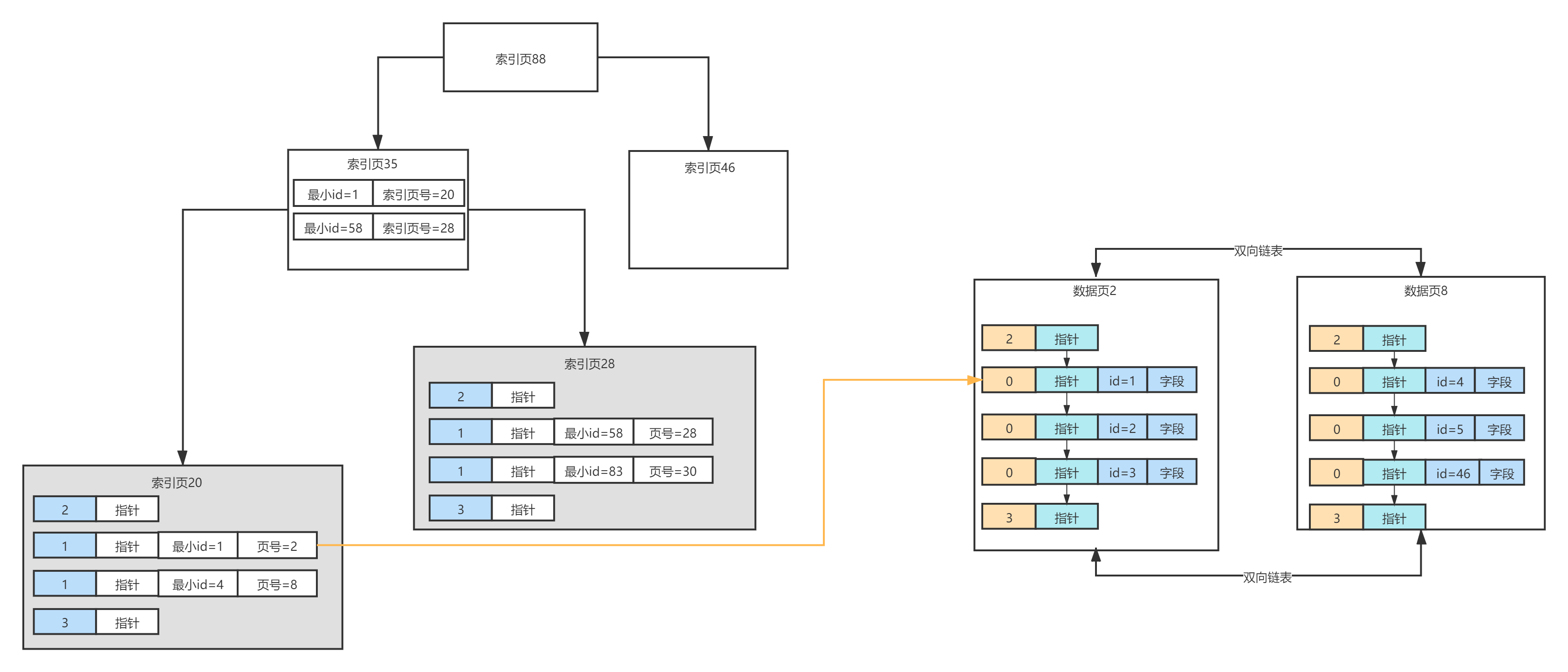
复习总结下-1:首先磁盘文件里存放了一个个的数据页,数据页在磁盘文件中是一段数据,这段数据有两个指针,一个指向上一个数据页的行起始位置,一个指向下一个数据页的行起始位置,是一个双向链表的数据结构,这是数据页;为什么称为数据页?因为页里面还有内容,这个里面的东西就是数据行,数据行也是有结构的,数据页里面的每个行组成了单向链表,即每个行都有指针指向了下一个行的位置,这是数据行; 然后是页目录,页目录的由来,目录肯定是用来定位的,根据目录查询具体内容,这个页目录需要你建表指定了主键,这时MySQL会为你维护这个页目录,即每添加一行数据,相应的在页目录里也会体现出来,然后页目录也是有数据结构的,页目录里有槽位的概念,就是添加一行数据时,相应的在槽位里也会保存一个主键id,值得注意的是每个槽位里是一组行数据,这就是页目录; 当查询数据时数据时如果就一个数据页,并且建立主键了,那直接通过二分查找页目录的,在页目录里的槽位里找到id,根据id就能找到完整的那行数据,当没有建立主键那就麻烦了,只能遍历这个数据页的每个行才能找到对应的数据,所以建立主键很重要。这是一个数据页,当是多个数据页呢,查询数据该怎么查呢?比如1000个数据页,总不能像一个数据页时到页目录的槽位里找主键id吧?1000个数据页就有1000个页目录的,所以这是不行的,由此引出一个主键目录的概念,也就是索引目录的概念,这个是干嘛的?是为了解决数据页数据行太多的问题,这个索引目录里的数据结构是什么样的呢? 这个目录用来管理数据页的,对每个数据页进行编号,所以索引目录里存放了一个个的数据页的页号,当然只有页号也是不行的,因为只有页号也无法定位我们要查询的那行数据,所以还得有主键id,当然不可能放行完整数据,这样太占空间,直接放id就可以了,当查询数据时知道了id,就可以拿着id及数据页号定位在那个槽位然后在槽位里走一遍页目录查询方式,找到完整数据了,所以索引目录的数据结构就是数据页号+主键id,但是存放数据页里很多行数据所有的主键id也不好,就存每个页的最小主键id,根据最小主键和上一个数据页的最小主键就能定位查询的数据在那个数据页号了。
复习总结-2:随着数据越来越多,一个索引目录显然不够用了,那怎么办呢?只能同样的方式在建立索引目录,那当索引目录也达到了1000个,这么多索引目录怎么管理?我们可以借鉴上面的思路,将索引目录组成索引页,当然数据还是在无限增加,索引页也太多了,达到了1000个索引页,当要查询数据时,遍历1000个索引页,查看每个索引页里的数据页有没有这个主键id,这显然是接受不了的,因为太慢。 那怎么办?肯定需要有个概念能管理这么多的索引页,MySQL是这样做的,在索引页的基础上再抽取一层索引页,我们为了方便先叫上层索引页,这个上层索引页如何管理这么多索引页呢?实际上他是将一个个的索引页再次抽象提取了,比如1000个索引页,那0-500索引页合并成一个上层索引页,这个上层索引页叫01,501-1000索引页合并成一个上层索引页,叫上层索引页索引页02,当然上层索引页如果只存索引页页号也是不行的,因为这没法定位数据,所以上层索引页除了存放索引页的页号还要存放索引页里最小的主键id,这样就能定位数据了,当查询数据时,比如找id=11这个, 先从上层索引页开始查,查这个数据在哪个上层索引页,比如在上层索引页01里,那就在上层索引页01里继续查在哪个索引页,找到在那个索引页就能找到哪个数据页,找到数据页,根据页目录查找具体完整行数据,这样就能查到了,上面的查询逻辑都是基于二分查找,如果上层索引页的数量太多怎么办?借鉴上面的方式在抽取上上层索引页管理,通常这个层面在MySQL里不会超出4层。 再次想下数据页和索引页还有上层索引页什么关系?他们之间其实是组成了B+树,这个B+树的叶子节点是数据页号+最小主键id,中间节点是索引页号+最小主键id,根节点是上层索引页,也可能是上上层索引页,取决于B+树的深度,上层索引页是没有这个概念的,只是为了方面描述。

若有收获,就点个赞吧
0 人点赞
