(1)原因:
之所以讲联合索引,是因为平时设计系统的时候一般都是设计联合索引,很少用单个字段做索引,因为需要尽可能的让索引数量少一些,避免磁盘占用太多,增删改性能太差。
(2)举例:
假设有一个表是存储学生成绩的,这个表的id是一个自增主键,默认会基于主键建立一个聚簇索引,然后字段包含 学生班级,学生姓名,科目名称,成绩分数四个字段,平时查询较多的是查询某个班的某个学生的某科目的成绩。
所以可以针对学生班级,学生姓名和科目名称建立一个联合索引。假设有两个数据页,第一个数据页里有三条数据,每条数据包含了联合索引的三个字段值和主键值,数据页内部是按顺序排序的,首先按照班级字段的值排序,如果一样则按照学生姓名字段来排序,如果一样,按照科目来排序,所以数据页内部都是按照班级名称,姓名和科目名称依次排序,数据页之间组成双向链表。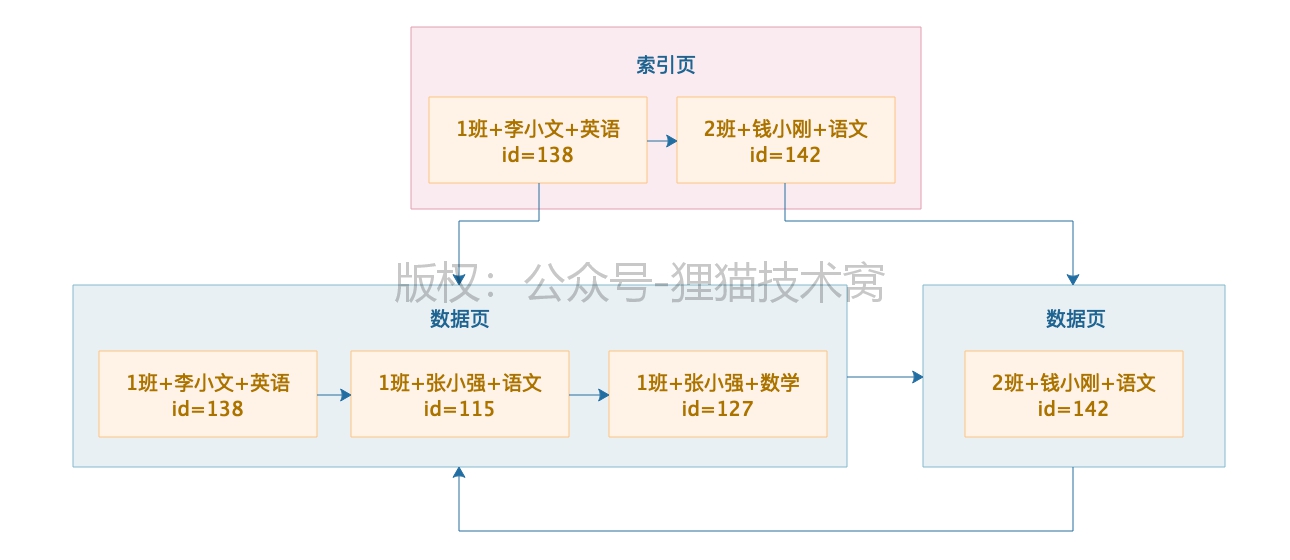
使用了联合索引,索引是 班级+名字+科目 ===> 那么数据页及索引页存放的是 三个字段组成的索引按照ascii码排序 和 页号。
索引页有两条数据,分别指向两个数据页,索引存放的是每个数据页里最小的那个数据值,索引页里指向两个数据页的索引项里都是存放了那个数据页里最小的值。索引页内部的数据页组成的单向链表是有序的,如果有多个索引页那么索引页之间也是有序的,组成了双向链表。
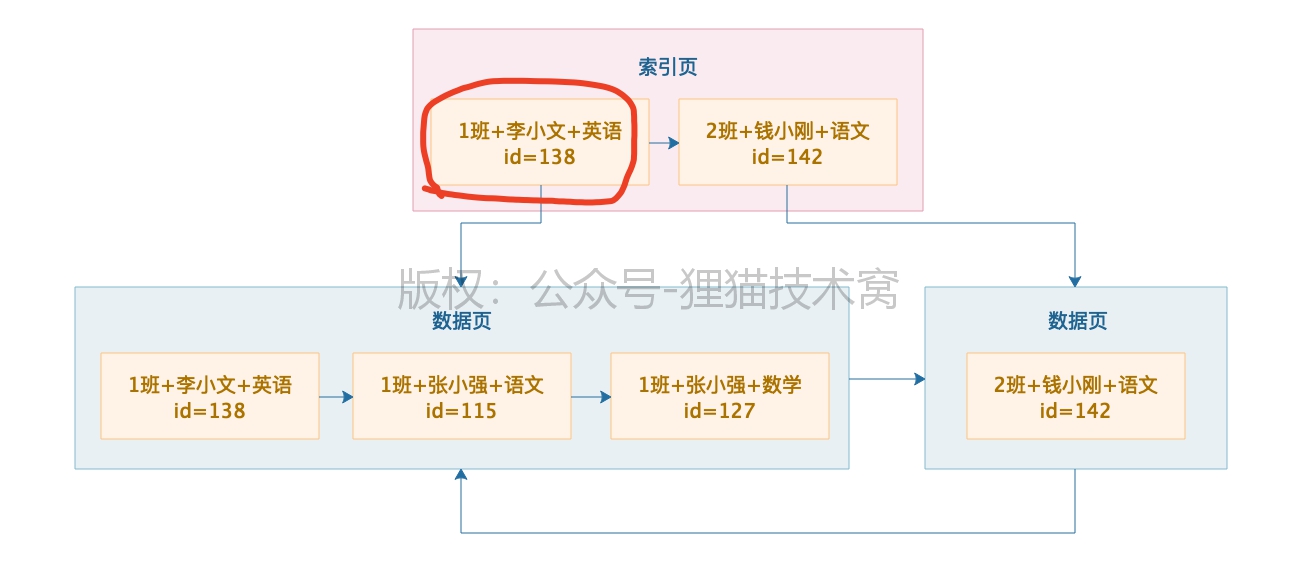
假设我们搜索 1班+张晓强+数学成绩,此时写个SQL select * from student_score where class=’1班’ and student_name=’张晓强’ and subject_name=’数学’,此时就涉及到索引的使用原则,就是发起的SQL语句里,where 条件里的几个字段都是基于值 来查询的,都是等于号,而且where 条件里的几个字段的名称和顺序也和设计的联合索引一样,此时就是 等值匹配规则,上面的SQL肯定使用联合索引来查询。
那么查询过程就很简单了,首先到索引页里找,索引页里有多个数据页的最小值记录,此时直接在索引页里基于二分查找就可以了,先是根据班级名称 1班 这个值对应的数据页,直接可以定位到他所在的数据页,然后直接在索引指向的数据页里找就可以了,在数据页内部的单向链表,直接做二分查找就可以了,先按1班这个值来找,然后发现几条都是1班,此时按照张晓强这个姓名来二分查找,此时发现多条数据是张晓强,接着按照数学进行二分查找,这样就定位到对应的数据的id是127,然后根据主键id=127到聚簇索引里按照一样的思路,从索引根节点开始二分查找定位到下个层级的页,然后再定位到id=127那条数据,然后从里面提取所有字段,包括分数就可以了。
(3)总结:
上面整个过程就是联合索引的查询过程,及全值匹配规则,假设你的SQL语句的where条件里用的几个字段的名称和顺序,跟索引里的字段一样,同时还是用 等号在做等值匹配,那么就直接按照上述过程来找。
对于联合索引而言,就是依次按照各个字段来进行二分查找,先定位到第一个字段对应的值在哪个页里,然后如果第一个字段有多条数据值都一样,就根据第二个字段来找,以此类推,定位到某条或某几条数据。

若有收获,就点个赞吧
0 人点赞
