(1)回顾:
首先我们往表里添加数据,都会基于主键自动建立聚簇索引,随着不停的添加数据,就会不停的在数据页里插入数据,一个数据页放满了就会分裂多个数据页,这个时候就需要索引页去指向各个数据页,如果数据页实在太多,索引页里的数据页指针也会太多,索引页必然会放满,此时索引页也会分裂成多个,再形成更上层的索引页。
默认情况下,MySQL建立的聚簇索引都是基于主键的值来组织索引的,聚簇索引的叶子节点都是数据页,里面放的就是插入的一行行的完整的数据。
在索引B+树中有一些特性,那就是数据页/索引页里面的记录都是组成一个单项链表的,而且数据大小有序排列;数据页/索引页之间互相之间组成双向链表,而且也都是按照数据大小排列的,所以B+树索引是一个完全有序的数据结构,无论是页内还是页之间。正因为B+树索引结构有序,查数据时候,直接从根节点开始按照数值大小一层层往下找,这个效率非常高。
如果是针对主键之外的字段建立索引的话,实质上本质就是那个字段的值重新建立另外一颗B+树索引,这个B+树索引的叶子节点存放的都是数据页,里面放的都是字段的值和主键值,然后每一层索引页里存放的是下层页的引用,包括页内的排序规则,页之间的排序规则,B+树索引的搜索规则都是一样的。
唯一要记住的是,假设我们根据其他字段的索引搜索,那么只能基于其他字段的索引B+树快速查找到那个值对应的主键,接着再次做回表查询,基于主键在聚簇索引的B+树里,重新从根节点开始查找那个主键值,找到主键值对应的完整数据。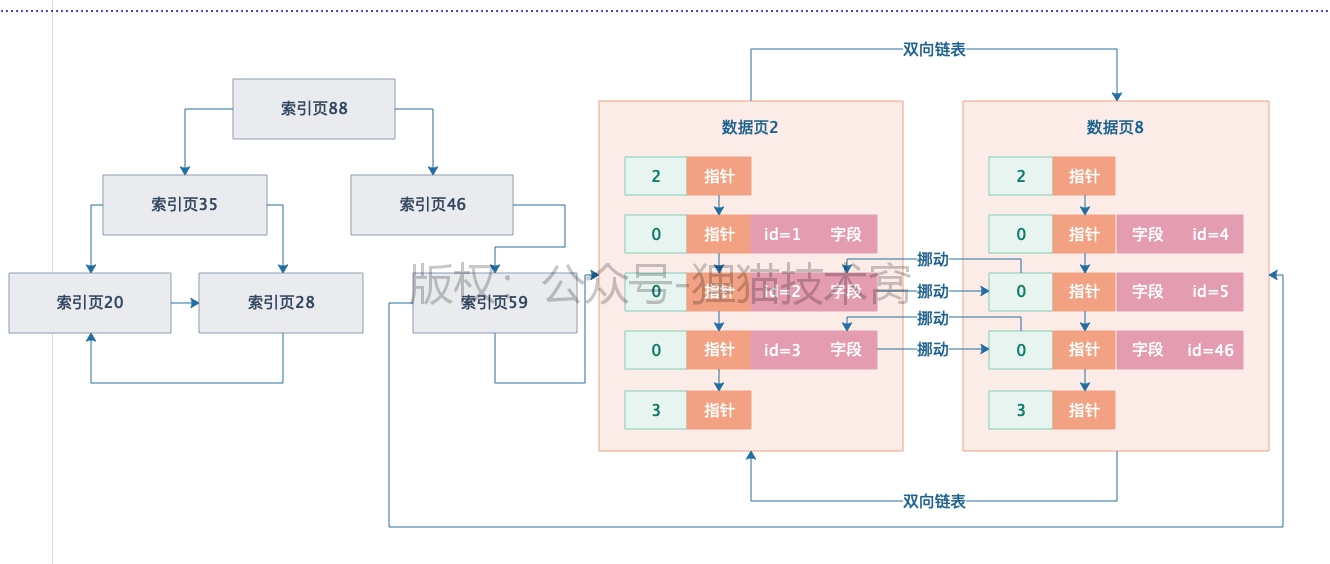
(2)建立索引的好处与坏处: 索引都建在磁盘文件上的,只有根索引放在内存中,查询时根据根索引查询然后到磁盘文件里经历两次IO查询到。
好处:建立一些字段的索引,可以直接根据某个字段的索引B+树来查找数据,不需要全表搜索,性能提升很高
坏处:主要有两个缺点,一个是空间上的,一个是时间上的;
空间上:要是给很多字段建立索引,那必然会有很多B+树,每一颗B+树都会占用很多的磁盘空间,索引建立的太多,很耗费磁盘空间
时间上:
建立很多索引,在进行增删改的时候,每次都需要维护各个索引的数据有序性,因为每个索引B+树都要求页内是按值大小排序的,页之间也是有序的,下一个页的所有值必须大于上一个页的所有值,所以不停的增删改数据,必然导致各个数据页之间的值大小没有顺序,此时只能进行数据页的移动,维护页之间的顺序,或者不停的插入数据,各个索引的数据页就要不停的分裂,不停的增加新的索引页,这个过程都是耗费时间的。所以表里的索引太多,很可能导致增删改的速度就变慢了。也许查询速度能提高,但是增删改会受到影响。因此通常来说,不建议一个表里建太多索引。
知识点:自增主键的方式插入数据减少索引页的分裂
UUID作为表主键无法确保UUID得值是单项递增的,UUID还会导致普通索引的叶子节点的数据页内容过大。
索引页的非叶子节点会存储下一层索引页的页号和最小主键id,数据页上页目录会存储最小主键值和槽位。
知识点:业务场景中建议优先使用多个字段建立联合索引,目的为了减少维护更多的索引树,因为索引树也是很占空间的,执行增删改时还要对索引页做分裂排序操作,维护好数据行的顺序,这个过程很耗费时间。但是联合索引字段过多索引页维护成本较高。非叶子节点维护的是索引页和主键的关系。

若有收获,就点个赞吧
0 人点赞
