1、binlog
1.1 binlog是什么?有什么用?
binlog是binary log的缩写,即二进制日志。binlog中记载了数据库发生的变化,比方说新建了一个数据库或者表、表结构发生改变、表中的数据发生了变化时都会记录相应的binlog日志。
binlog主要用在下边两个方面:
- 主从数据库间的复制;
- 用于恢复。
关于binlog,需要做以下几点说明:
- binlog是MySQL的Server层实现的,意味着所有存储引擎都可以使用;
- binlog是逻辑日志,记录的是这个语句的原始逻辑,比如 “给 id = 1 这一行的 age 字段加 1”;
- binlog是追加写入的,写满一个binlog文件后会切换到下一个,并不会覆盖之前的binlog。
1.1.1 主从数据库间的复制
为了提高并发处理请求的能力,一般将MySQL服务部署在多台物理机器中,这些服务器中维护相同的数据副本。
其中一个典型的部署方案就是一主多从,即一台主服务器(Master)和多台从服务器(Slave)。对于改变数据库状态的请求(DDL、DML等),就将它们发送给主服务器,对于单纯的查询(如SELECT语句)请求,就将它们发送给从服务器。为了让各个从服务器中存储的数据和主服务器中存储的数据一致,每当我们改变了主服务器中的数据后,就需要将改变的信息同步给各个从服务器。binlog日志中正好记录了数据库发生的各种改变的信息,从服务器读取主服务器产生的binlog日志,然后执行这些binlog日志中所记录的数据库变化语句,从而达到主从服务器数据一致的效果。1.1.2 binlog用于恢复
工作中我们可能有意无意的就将数据库里的数据给“毁”了,比方说写DELETE语句不加WHERE子句,那一整个表的数据都就没了!为了数据的安全性,我们需要定时备份数据库(mysqldump命令),不过这种全量备份我们不可能每秒都做一遍,而是每天或者每个月做一次全量备份。那如果在两次全量备份中间手贱写了不加WHERE条件的DELETE语句该怎么办呢?只能将数据库恢复到前一次全量备份时的样子吗?还好我们有binlog日志,我们可以从上一次全量备份开始,执行自上一次备份后产生的binlog日志,直到我们写DELETE语句之前的binlog日志为止。这样就可以完成数据库恢复的功能。1.2 如何配置binlog?
MySQL服务器并不一定会生成binlog日志,我们可以通过查看log_bin系统变量来判断当前MySQL服务器是否生成binlog日志: ```sql
mysql> show variables like ‘log_bin’; +———————-+———-+ | Variable_name | Value | +———————-+———-+ | log_bin | ON | +———————-+———-+ 1 row in set, 1 warning (0.02 sec)
上例中bin_log系统变量的值为ON,表明当前服务器生成binlog,若为OFF表明当前服务器不生成binlog。<br />如果当前服务器不生成binlog,我们想开启binlog,那么就需要重启服务器,设置log-bin启动选项:```sql--log-bin[=base_name]
binlog日志并不是仅写到一个文件中,而是写入一组文件中,这组文件的命名是这样的:
basename.000001basename.000002basename.000003basename.000004...
也就是这组日志文件名称都包含一个basename,然后以一个数字结尾。启动选项log-bin[=base_name]中的base_name就是这组binlog日志文件名称都包含的部分。如果我们不指定base_name(即单纯的使用—log-bin),那MySQL服务器会默认将主机名-bin作为binlog日志文件的basename。
2、Redo日志
关于redo log,有以下几点说明:
- redo log是InnoDB存储引擎特有的;
- redo log是物理日志,记录的是数据页中数据的变化,即一条sql语句在哪几个数据页中做了修改;
redo log是循环写入,redo log记录的日志空间有限,redo log只会记录未刷入磁盘中的日志,已经刷入磁盘中的数据都会从redo log这个有限大小的日志文件里删除。
2.1 redo log 是什么?有什么用?
redo日志是为了保障数据库的持久性的,是一种物理日志。事务要对数据库中的数据进行修改,会先将数据从磁盘读取到内存(Buffer Pool)中,此时修改后的结果在内存中没有持久化之前,数据库节点突然下电会使内存中的数据全部丢失,那么这个已经提交了的事务对数据库中所做的更改也就跟着丢失了,这就违背了持久性。
解决方案就是在事务提交时,将事务对数据库做的更改记录到redo日志中,并将redo日志持久化到磁盘,这样即使之后系统崩溃了,重启之后只要按照redo日志中所记录的步骤重新更新一下数据页,那么该事务对数据库中所做的修改又可以被恢复出来,也就意味着满足持久性的要求。2.2 redo log 和binlog的区别?
从三个维度:适用的对象、写入的内容、写入的方式比较:
使用的对象不同:
- binlog是MySQL的Server层实现的,所有的存储引擎都可以使用;
- redo log是InnoDB存储引擎特有的。
- 写入的内容不同:
- binlog是逻辑日志,记录的是这个语句的原始逻辑,比如 “给 id = 1 这一行的 age 字段加 1”;
- redo log是物理日志,记录的是数据页中数据的变化,比如一条sql语句在哪几个数据页中做了修改。
写入的方式不同:
- binlog是追加写,写满一个binlog后再切换到下一个binlog里写;
- redo log是循环写,redo log只会记录未刷入磁盘中的日志,已经刷入磁盘中的数据都会从redo log这个有限的日志文件中移除。
2.3 redo log的两阶段提交
所谓的redo log的两阶段提交,是指redo log的写入拆分成了两个步骤:prepare和commit,这样做的目的是在MySQL宕机恢复时,可以结合binlog一起,做到主库和从库数据一致的恢复结果。2.3.1 redo log两阶段提交过程
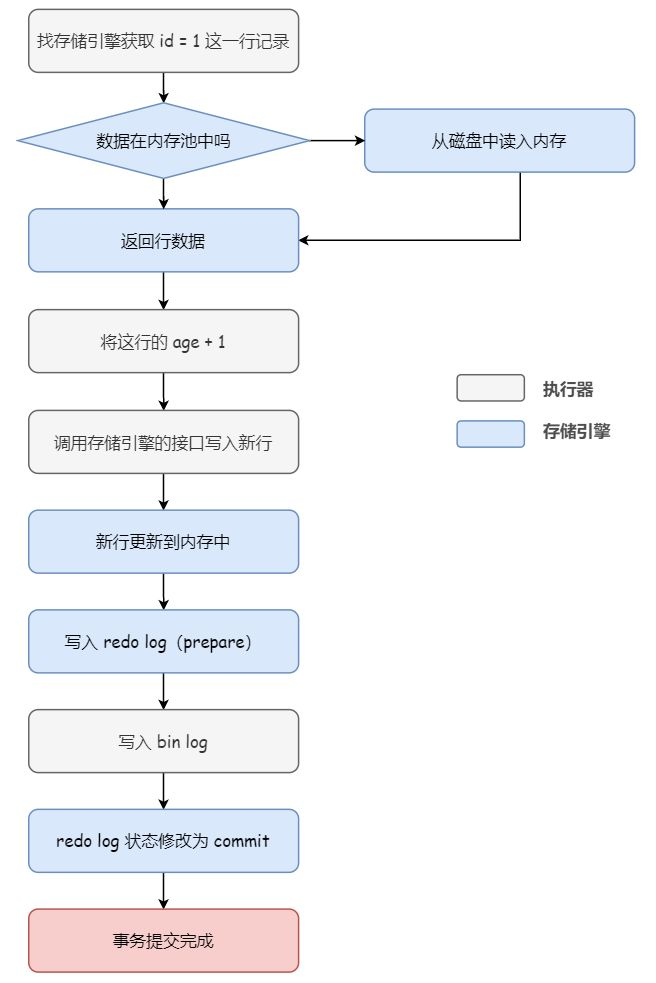
对于更新语句,更新流程涉及到两个重要的日志:binlog和redo log,以下面这条sql语句为例,说明一下在更新语句中存储引擎和执行器都做了哪些事情,涉及到的两个日志的情况:UPDATE table SET age=age+1 WHERE id=1;
执行器:找存储引擎取到 id = 1 这一行记录;
- 存储引擎:根据主键索引树找到这一行,如果 id = 1 这一行所在的数据页本来就在内存池(Buffer Pool)中,就直接返回给执行器;否则,需要先从磁盘读入内存池,然后再返回;
- 执行器:拿到存储引擎返回的行记录,把 age 字段加上 1,得到一行新的记录,然后再调用存储引擎的接口写入这行新记录;
- 存储引擎:将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务;
(注意不要把这里的提交事务和我们 sql 语句中的提交事务 commit 命令搞混了哈,我们这里说的提交事务,指的是事务提交过程中的一个小步骤,也是最后一步。当这个步骤执行完成后,commit 命令就执行成功了。) - 执行器:生成这个更新操作的 bin log,并把 bin log 写入磁盘;
- 执行器:调用存储引擎的提交事务接口;
- 存储引擎:把刚刚写入的 redo log 状态改成提交(commit)状态,更新完成。
2.3.2 MySQL崩溃时如何恢复
根据redo log两阶段提交,崩溃恢复时的判断规则是这样的:
- 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
- 如果 redo log 里面的事务处于 prepare 状态,则判断对应的事务 binlog 是否存在并完整:
- 如果 binlog 存在并完整,则提交事务;
- 否则,回滚事务。
关于MySQL崩溃的具体时间点,需要注意以下两个场景:
- redo log处于prepare状态,在写入binlog之前,发生宕机;
写入了binlog之后,redo log状态修改成commit之前,发生宕机。
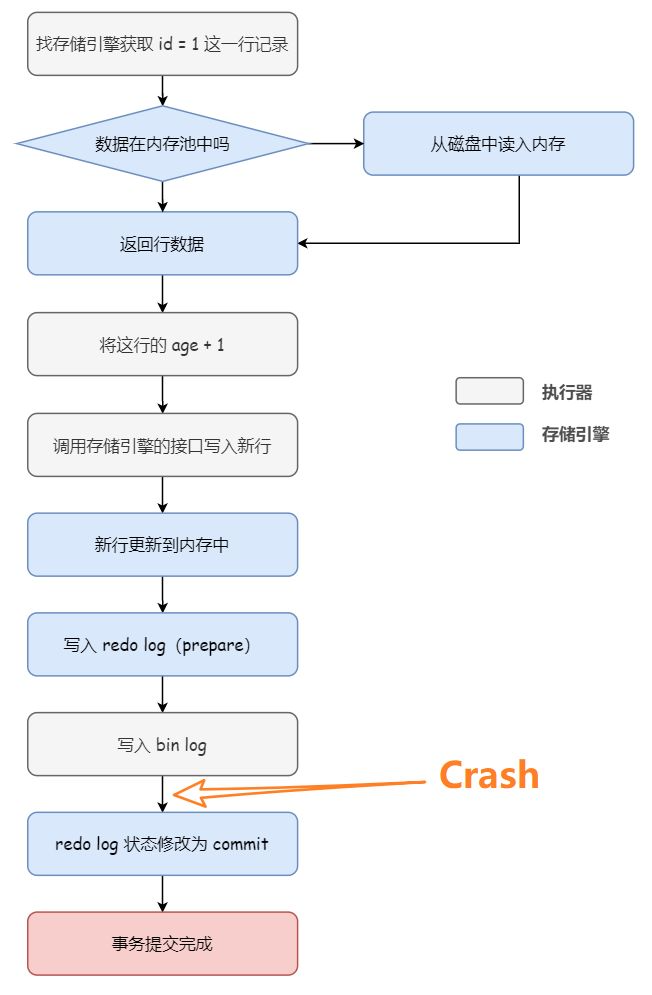
2.3.2.1 redo log处于prepare状态,在写入binlog之前,发生宕机
该场景对应上图中的这一阶段:
(图中crash的时间点好像有问题)
假设数据库在写入 redo log(prepare) 阶段之后、写入 binlog 之前,发生了崩溃,此时 redo log 里面的事务处于 prepare 状态,binlog 还没写入磁盘文件。由于binlog还没有写入,数据库恢复之后从库进行同步时,不会执行这个更新操作,所以为了主备一致,需要在主库上对这个更新事务进行回滚。2.3.2.2 写入了binlog之后,redo log状态修改成commit之前,发生宕机
该场景对应上图中的这一阶段:
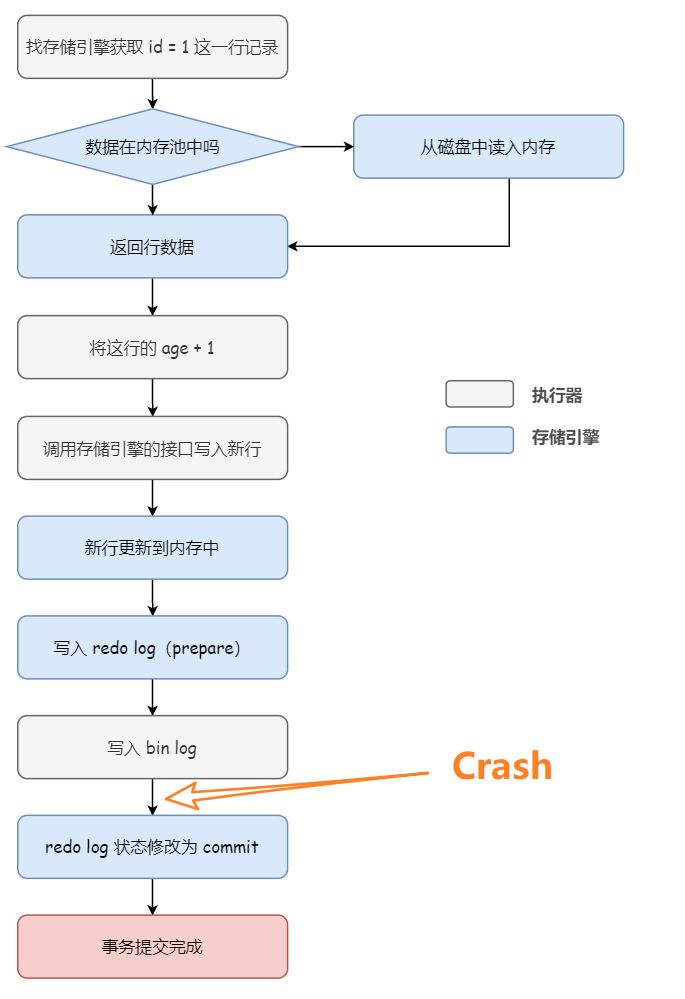
如果数据库在写入 binlog 之后,redo log 状态修改为 commit 前发生崩溃,此时 redo log 里面的事务仍然是 prepare 状态,bin log已经写入磁盘文件,而主库并没有提交这个事务。且此时binlog已经成功写入,这样当数据库恢复时binlog被从库同步过去,从库完成了更新操作,而主库并没有更新操作的事务提交,为了主备一致,主库需要提交这个更新操作的事务。2.3.3 如何判断binlog是否完整写入
2.3.2小节介绍的两种MySQL崩溃宕机的场景,都是发生在binlog写入前和binlog写入后,那如何判断binlog是否已经完整写入了呢?分以下两种情况:
statement 格式的 bin log,最后会有 COMMIT;
- row 格式的 bin log,最后会有 XID event。
而对于 bin log 可能会在中间出错的情况,MySQL 5.6.2 版本以后引入了 binlog-checksum 参数,用来验证 bin log 内容的正确性。
2.3.4 总结
所谓两阶段提交,其实就是把 redo log 的写入拆分成了两个步骤:prepare 和 commit。首先,存储引擎将执行更新好的新数据存到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。然后执行器生成这个操作的 bin log,并把 bin log 写入磁盘。最后执行器调用存储引擎的提交事务接口,存储引擎把刚刚写入的 redo log 状态改成提交(commit)状态,更新完成。
如果数据库在写入 redo log(prepare) 阶段之后、写入 binlog 之前,发生了崩溃,此时 redo log 里面的事务处于 prepare 状态,binlog 还没写,之后从库进行同步的时候,无法执行这个操作,所以为了主备一致,MySQL 崩溃时会在主库上回滚这个事务;而如果数据库在写入 binlog 之后,redo log 状态修改为 commit 前发生崩溃,此时 redo log 里面的事务仍然是 prepare 状态,binlog 存在并完整,这样binlog就会被从库同步过去,但是实际上主库并没有完成这个操作,所以为了主备一致,数据库恢复后,主库上事务仍然会被正常提交。
3、Undo日志
undo日志是为了保障数据库的原子性和一致性,是一种逻辑日志。undo log主要记录的是数据改变前的历史版本,为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。
undo日志有两个作用:
- 用于事务的回滚;
- 用于MVCC机制避免脏读、不可重复读和幻读。
undo日志保证的是事务的一致性,redo日志保证的是事务的持久性,这是undo和redo日志本质的区别。
参考

若有收获,就点个赞吧
0 人点赞
