1、什么是分库分表
先介绍一下分库分表的产生背景。随着公司业务的发展,数据库中存储的数据量也猛增,由于数据库单机存储的容量、数据库支持的连接数(一般单实例2000连接数以上就有挂掉的风险)等因素的限制,数据库很容易成为整个系统里的性能瓶颈。当单表数据量达到500W(业界经验值,只供参考,不是绝对的)以上时,对数据库的增删改查操作的响应时间都会较长,此时可以从硬件层面和软件层面两个大方向进行优化:
- 硬件层面:通过提升服务器硬件能力来提高数据的处理能力,比如增加CPU核数、增加内存和硬盘空间、网络带宽等,具体落实到对数据库的提升:比如增大内存空间,使得分配给MySQL的Buffer Pool的内存容量更多,可以加载到Buffer Pool缓存中页的数量也会更多,增大缓存命中率;增大网络带宽使得数据库返回给客户端的数据量不会因为网络带宽的大小而限制(网络带宽很贵的…)。但是这样做的问题很明显:提升硬件设备能力的成本太高(相比软件成本),而且当硬件水平达到一定规模后,提升硬件能力所带来的系统整体性能的提高的收益比很低,不划算。
- 软件层面:
- 数据库层面优化:即针对单个数据库实例的优化,比如做主从复制集群、读写分离、优化索引、优化sql语句等操作;
- 分库分表:如果做了上述操作还性能还是下降很严重,且数据库单标数据达到一定量级时,就需要做分库分表了,具体数据库设计时的一些tips可以参考我这篇文章:https://www.yuque.com/docs/share/08cdfa31-54d1-4358-9d7a-f0bc8d81f086?# 《MySQL中的设计准则》。
分库分表的定义:分库分表是为了解决由于数据量过大而导致的数据库性能下降的问题,将原来独立的数据库拆分成若干数据库,将单个数据库中的大表拆分为若干小表,目的是使单个数据库、单张表的数据量变小,从而达到提升数据库性能的目的。常见的分库分表的方式有垂直分库、垂直分表、水平分库、水平分表。
2、分库分表的方式
2.1 垂直分库
项目开始时规模不大,可能还用的是单体架构,此时所有模块的表统一存放在底层一个数据库中,此时会有两个问题:
- 所有模块的请求均会打到同一个数据库实例,数据库连接池的数目是一定的,且数据库向本地内存申请的Buffer Pool缓存大小也是一定的,且单个服务器的网络带宽流量也是一定的,受服务器物理机器硬件性能的限制,请求数过多时可能会打挂数据库实例;
- 即使硬件性能不是瓶颈,单表中存储的数据量达百万级别时,增删改查性能会降低。
此时可以先进行垂直分库,对于单体架构,一般会先拆分成微服务架构,每个微服务对应一个或者多个数据库。基于此,垂直分库的定义:垂直分库是指按照业务将表和库进行分类,不同业务的微服务对应到不同的数据库上,每个库可以放在不同的服务器上(避免都放在一台服务器上使硬件资源成为系统性能瓶颈),它的核心理念是专库专用。
以电商系统为例,抽象出1个数据库商品库,商品库里包含3张表,分别是商品信息表、地理区域表和店铺信息表,表结构的简化图如下: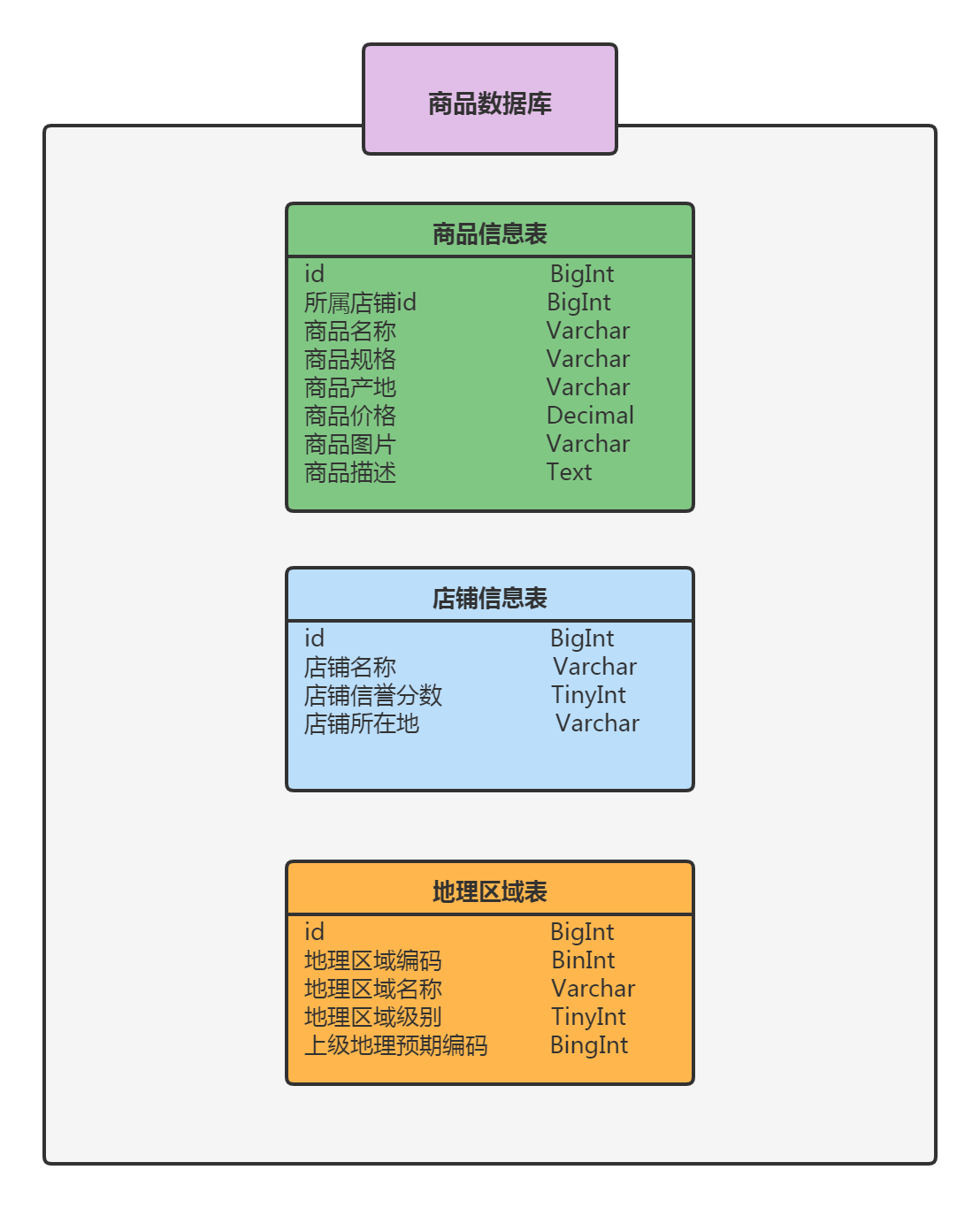
对上面的商品数据库进行垂直分库时,商品信息表和店铺信息表由于业务属性不同,可以将其分别存入到商品库和店铺库,并分别对应不同的微服务:产品中心和店铺中心。此外,由于地理区域表在查询商品信息和店铺信息时都会用到(连接查询),且跨数据库的连表查询数据库中间件不支持,因此对地理区域表做了冗余处理,即在商品库和店铺库里都存放一张地理区域表。对上面单体架构的数据库做垂直分库后的示意图如下图所示: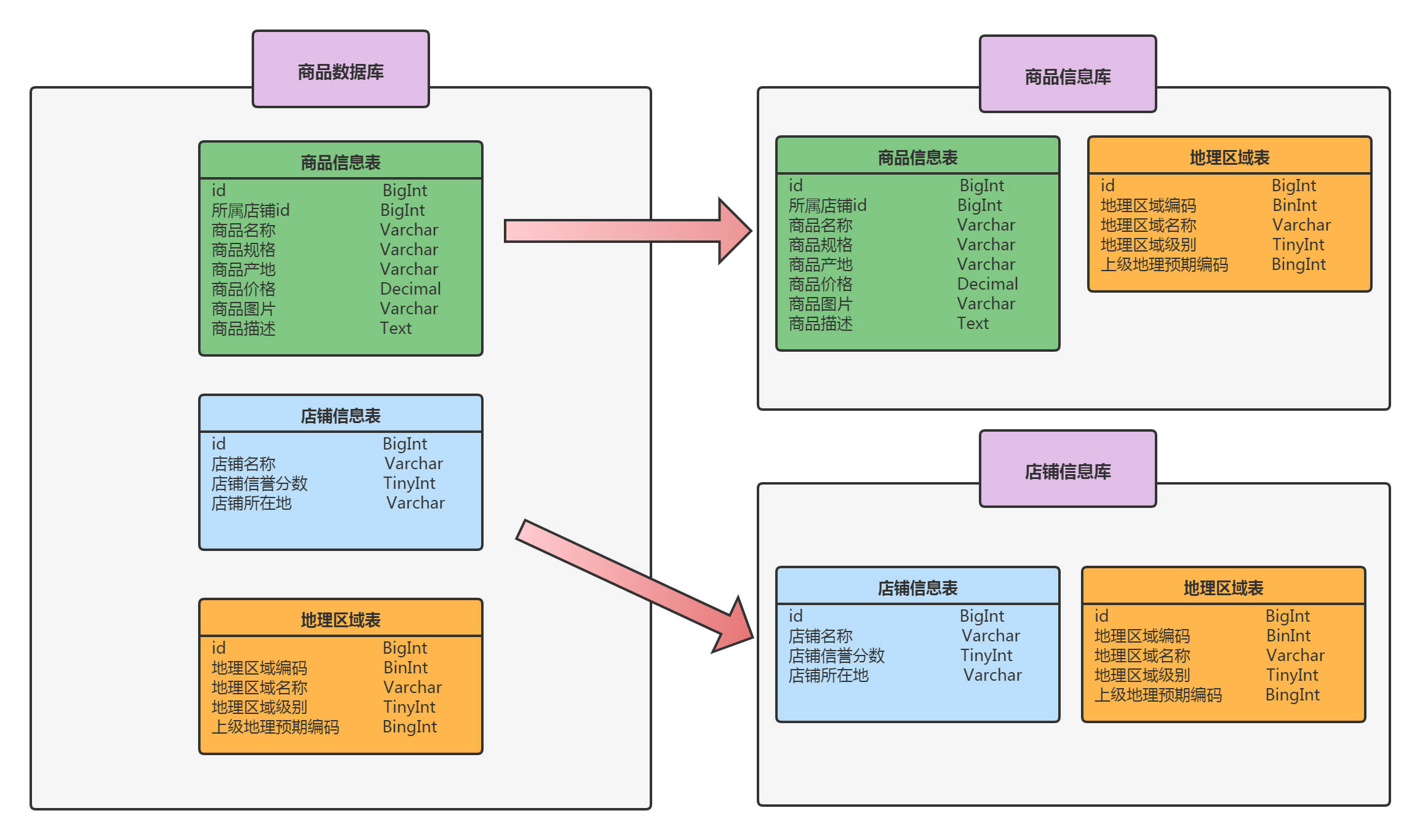
垂直分库带来的提升是:
- 解决数据库业务层面的耦合,垂直拆分后业务更清晰;
- 可以对不同业务的数据分别进行分级管理、维护、监控和扩展;
- 高并发场景下,垂直分库将拆分出来的数据库部署在不同的机器上,降低了单机硬件资源成为系统性能瓶颈的风险。
2.2 垂直分表
先介绍以下垂直分表对应的业务场景,即什么时候考虑垂直分表。还是举电商的例子:用户在浏览商品列表时,只有对某商品感兴趣时才会查看该商品的详细描述。因此,商品详情中商品描述字段访问频次较低,且该字段存储占用空间较大,访问单个数据IO时间较长;商品列表中商品名称、商品图片、商品价格等其他字段数据访问频次较高。由于这两种数据的冷热特性,可以对上面垂直分库后的表进一步做垂直分表:将访问频率较低的商品信息描述字段单独放在商品描述表中;将访问频率较高的商品基本信息放在商品信息表中,垂直拆分后的数据库表如下: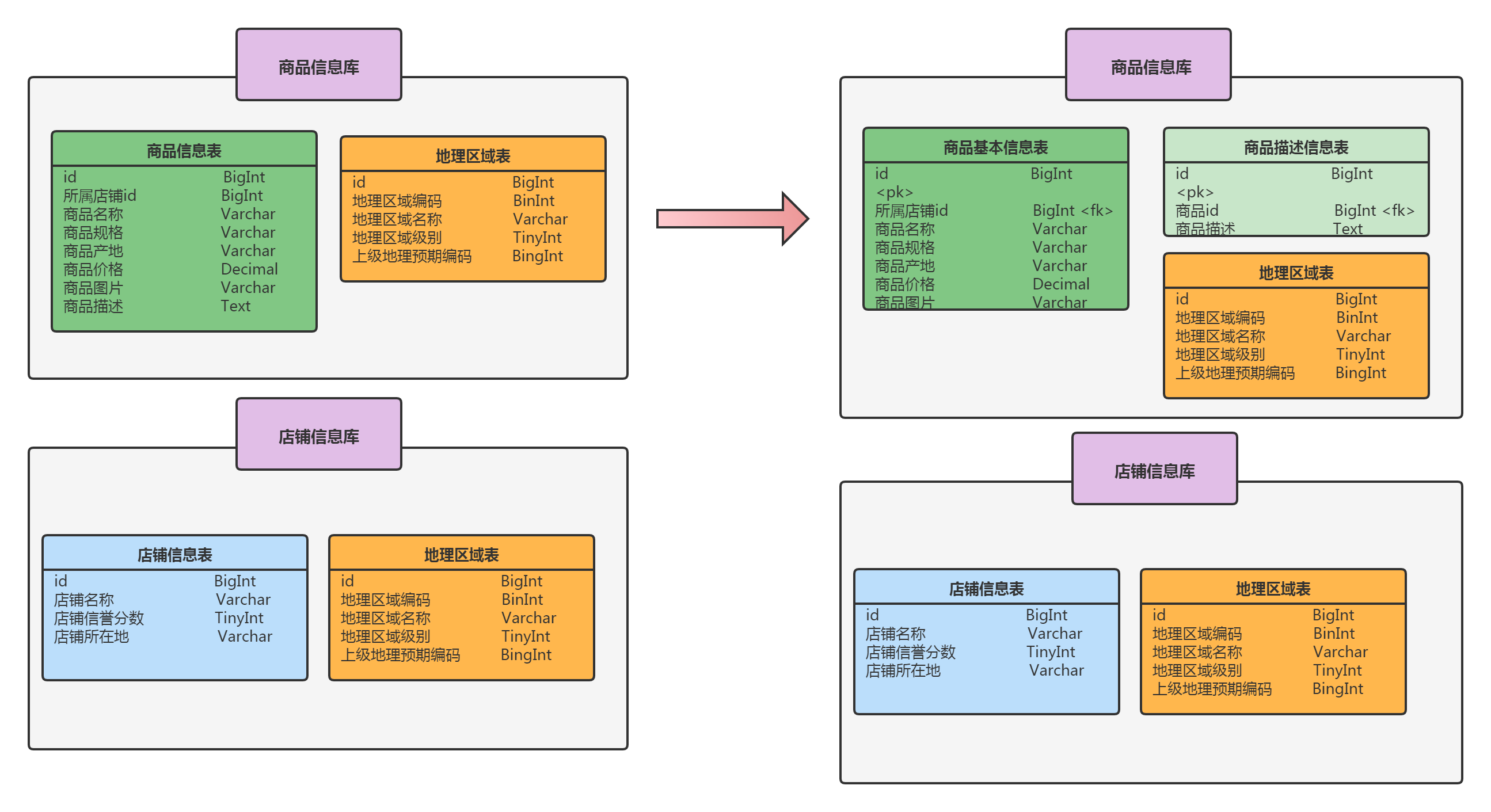
垂直分表的定义:将一张宽表(列的数目较多的表)按照字段特性(冷热、数据类型)拆分成若干小表(列数目较少的表),每个小表存放大表中部分字段。垂直分表相比水平分表一个很大的不同就是垂直分表是改变了表结构,而水平分表没有。
垂直分表带来的提升(垂直分表带来的性能提升主要集中在热门数据的操作效率):
- 操作商品详情的线程和操作商品列表的线程互不影响,避免了加锁冲突(修改某一行数据时其他线程对该行数据的锁定读操作会阻塞),尤其是对热门数据的增删改查操作性能提升明显;
- 将大字段的列单独放在一张表,避免查询大字段IO效率低下。
大字段IO效率低的原因:
- 数据量本身较大,需要更多的读取时间;
- 大字段占用的数据页存储空间大,而数据页存储空间一般是固定的64KB,这样单页内存储的数据数目就少了,Buffer Pool缓存中能存储的数据数目也就少了,缓存命中就降低了。
2.3 水平分库
经过垂直分库和垂直分表,数据库性能问题得到一定程度的解决,但是一个核心的问题并没有解决:随着业务规模的扩展,商品基本信息表和商品描述信息表的数据会不断新增,单表数据规模超过500W时,可能优化索引优化查询方式带来的数据库性能提升也不大了,更不要说昂贵的硬件资源提升。在这个背景下,可以考虑水平分库。
结合上面的例子,提供一种水平分库的策略:将商品基本信息表里,店铺id为单数和双数的商品基本信息分别放在两个商品信息库中,如下: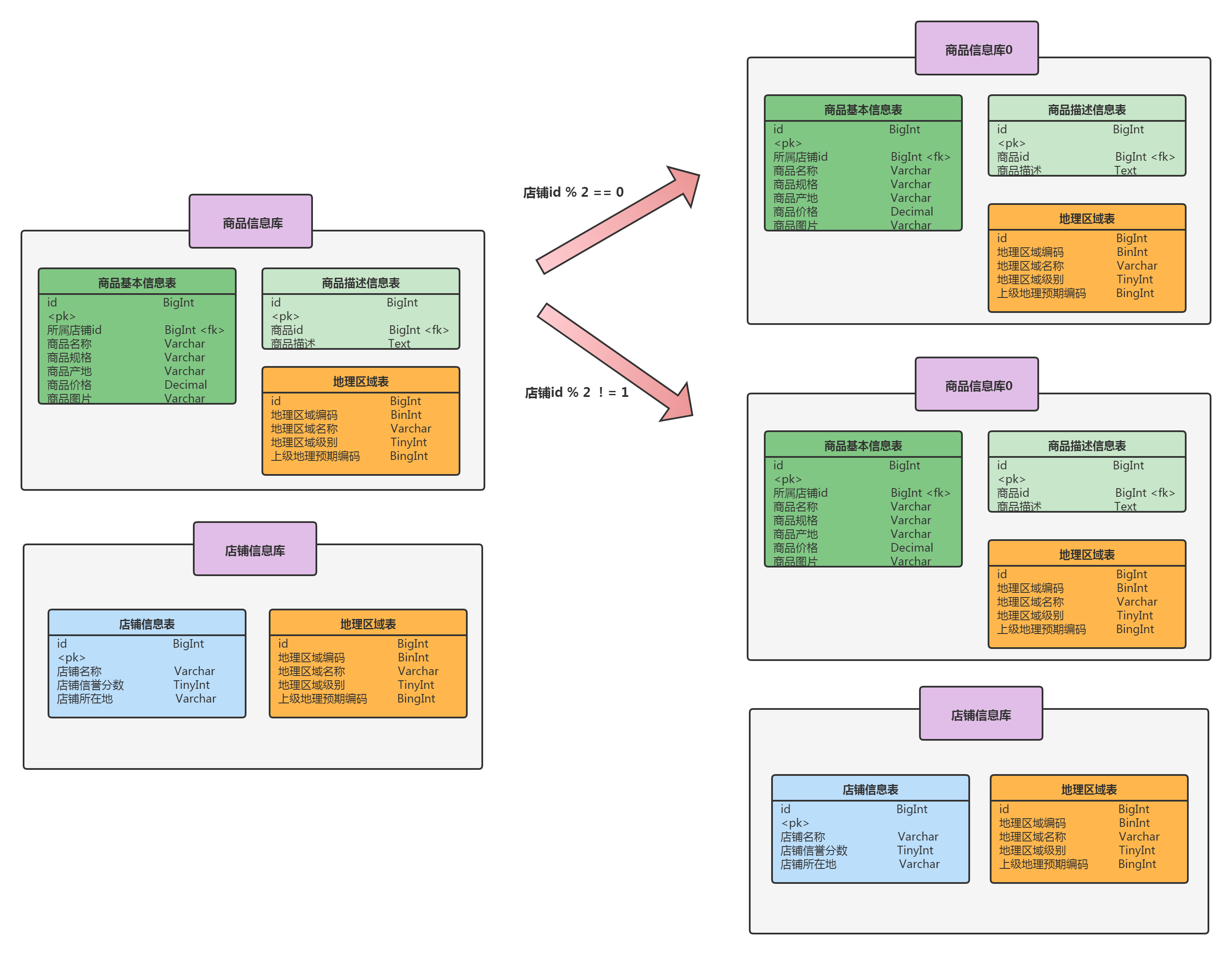
水平分库的定义:水平分库是把同一个表的数据库按照一定的规则拆分到不同的数据库中,每个数据库实例可以部署在不同的环境上。垂直分库不会改变表结构,只是对表内的数据行进行拆分。
水平分库带来的提升:
- 高并发场景下,水平分库将拆分出来的数据库部署在不同的机器上,降低了单机硬件资源成为系统性能瓶颈的风险;
- 减轻了单库单表的数据量大导致对单表增删改查响应速度慢的问题;
- 高并发场景下,减少了锁冲突(MyISAM存储引擎仅支持表锁,InnoDB存储引擎支持行锁,不会有这个提升)
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了。经过水平切分的优化,往往能解决单库存储量及性能瓶颈,但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
2.4 水平分表
水平分表和水平分库的思路一致,即不改变表的结果,只是将单表内的数据再拆分到同一个数据库中的不同表里,其目的跟水平分库一样,也是解决单表数据量过大的问题,项目中一般水平分库和水平分表是同时进行的。
在上面水平分库的基础上,再对商品信息表做拆分,水平分表策略是:商品id为奇数拆分到商品信息表0中,商品id为偶数拆分到商品信息表1中,如下: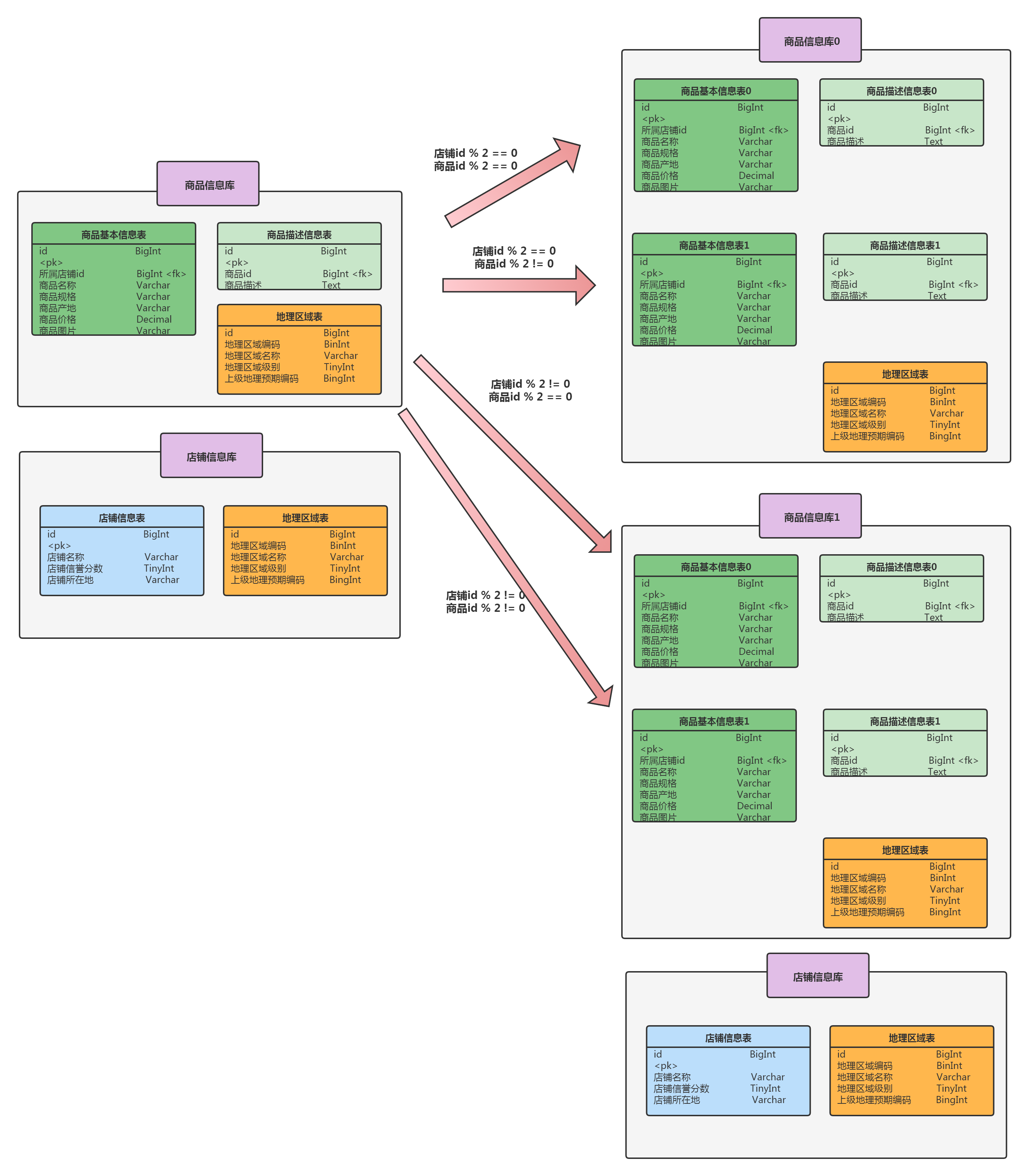
水平分表的定义:水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
水平分表带来的提升是:
- 优化单一表数据量过大而产生的性能问题;
高并发场景下,减少了锁冲突(MyISAM存储引擎仅支持表锁,InnoDB存储引擎支持行锁,不会有这个提升)
2.5 四种分库分表方式总结
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
- 垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
- 水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(由数据库中间接解决)。
- 水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
3、分库分表带来的问题
(1)跨库连接查询
在单库未拆分表之前,我们可以很方便使用join操作关联多张表进行连接查询,但是经过分库分表后两张表可能都不在一个数据库中,如何进行连接查询呢?
有以下几种解决方案:
- 字段冗余:将需要关联查询的字段放在主表中,避免进行连表查询。但这样做有个问题:如果更新了该字段,需要同时维护多张表的该字段,因此字段冗余策略适合针对那些不经常改变的字段,比如性别等;
- 表冗余:跟字段冗余的思路一样,将一些基础表(很多连接查询都会join的表)在每一个数据库中都放一份,上面例子里的地理区域表就是做的表冗余,但表冗余同样适合那些不经常做增删改操作的表;
- 上层业务代码做多次查询,即将多表连接查询改为对多张表的单表查询,将上一次单表查询的结果作为下一次单表查询的条件查询,最后将多次查询的结果在业务代码(比如Java层)处拼装成BO。
(2)分布式事务
单数据库可以用本地事务搞定,使用多数据库就只能通过分布式事务解决了。数据库中间件比如Sharding-JDBC不能提供分布式事务的功能,需要专门的分布式事务中间件比如Seata或者基于消息队列的柔性事务来解决。
(3)排序、分页、函数计算问题
在使用SQL时order by,limit等关键字需要特殊处理,一般来说采用分片的思路:先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终得到结果。
(4)分布式id
如果使用Mysql数据库在单库单表可以使用自增id作为主键,分库分表之后就不行了,分库分表后虽然单库单表不会出现主键id重复,但是站在整体的数据库或者说逻辑表来看,会出现id重复。
常用的分布式 ID 解决方案有:
- UUID;
- 雪花算法(Snowflake);
- 百度uid-generator;
- 美团Leaf;
- 滴滴Tinyid。
Sharding-JDBC里提供了UUID和SNOWFLAKE两种分布式Id的实现方式,可以在SpringBoot项目中的application.yml配置文件中指定。
本文仅是介绍分库分表的理论知识,具体通过数据库中间件Sharding-JDBC实现分库分表可以参考我这篇文章:https://www.yuque.com/docs/share/c1a37ca0-ccd7-4c4a-aa04-ea3dea1f1699?# 《Sharding JDBC学习笔记》
参考
【攀博课堂】Sharding JDBC数据库分库分表入门到项目实战传智燕青授课
在面试时被问到,为什么MySQL数据库数据量大了要进行分库分表?
彻底搞清分库分表(垂直分库,垂直分表,水平分库,水平分表)

若有收获,就点个赞吧
0 人点赞
