1、数据插入
关系型数据库中,数据插入的单位都是一行或者一条记录,可能插入一条记录,也可能插入若干条记录。
1.1 插入完整的记录
格式:
INSERT INTO 表名 [(列名集合)] VALUES (每一列对应的数据的集合);
举例:
INSERT INTO test_table (id, name) VALUES (20180101, 'JERRY');INSERT INTO test_table VALUES (20180102, 'CISSIE');
注意:
- 列名集合可以省略;
- 列名集合省略时,VALUES里的数据顺序必须和表中列的顺序保持一致;
- 列名集合没有省略时,VALUES里的数据顺序可以与表中列的顺序不一致,与列名集合里列的顺序保持一致即可;
1.2 插入部分的记录
在插入记录的时候,某些列的值可以被省略,但是这个列必须满足下边列出的某个条件之一:
- 该列允许存储NULL值
- 该列有DEFAULT属性,给出了默认值
举例:
INSERT INTO test_table(id) VALUES (20180103);INSERT INTO test_table(name) VALUES ('TOM');
结果: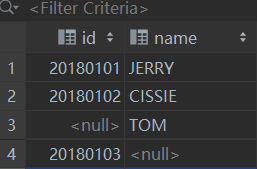
可以看到INSERT语句中省略的列的值自动用NULL进行了填充。
1.3 批量插入记录
格式:
INSERT INTO 表名 (列名集合,逗号分隔) VALUES (列1的值, 列2的值...), ((列1的值, 列2的值...), (列1的值, 列2的值...) ...;
举例:
INSERT INTO test_table (id, name) VALUES (20180105, 'LUCY'), (20180106, 'JACK'), (20180107, 'JIM');
1.4 插入查询结果集
就是将表1中查询的结果集批量或者单条插入到表2中。
格式:
INSERT INTO 表2 (表2的列名集合,逗号分隔) SELECT (表1的列名集合,逗号分隔) FROM 表1 WHERE 过滤条件;
举例:
INSERT INTO test_table2 (id, name) SELECT id, name FROM test_table WHERE id < 20180103;
注意:
- INSERT语句指定的列要和查询列表中的表达式要一一对应。
1.5 INSERT IGNORE
存在这样的场景:表中某些列是UNIQUE属性,或者主键列,这些列不允许重复元素的记录插入,在插入记录时,我们想达到的效果是:插入重复元素的记录则忽略,插入不重复元素的记录则执行,此时仅需要在INSERT后面加上**IGNORE**即可,举例:INSERT IGNORE INTO first_table(first_column, second_column) VALUES(1, '哇哈哈'), (9, 'iii');
1.6 INSERT ON DUPLICATE KEY UPDATE
对于主键或者有唯一性约束的列或列组合来说,新插入的记录如果和表中已存在的记录重复,我们可以选择的策略不仅仅是忽略该条记录的插入,也可以选择更新这条重复的旧记录。比如我们想在first_table表中插入一条记录,内容是(1, '哇哈哈'),我们想要的效果是:对于那些是主键或者具有UNIQUE约束的列或者列组合来说,如果表中已存在的记录中没有与待插入记录在这些列或者列组合上重复的值,那么就把待插入记录插到表中,否则按照规定去更新那条重复的记录中某些列的值。设计MySQL的大叔给我们提供了INSERT ... ON DUPLICATE KEY UPDATE ...的语法来实现这个功能:
这个语句的意思就是,对于要插入的数据INSERT INTO first_table (first_column, second_column) VALUES(1, '哇哈哈') ON DUPLICATE KEY UPDATE second_column = '雪碧';
(1, '哇哈哈')来说,如果first_table表中已经存在first_column的列值为1的记录(因为first_column列具有UNIQUE约束),那么就把该记录的second_column列更新为'雪碧'。2、数据删除
格式:
举例:DELETE FROM 表名 [WHERE 表达式];
另外,我们也可以使用DELETE FROM test_table WHERE id > 20180102;
LIMIT子句来限制想要删除掉的记录数量,使用ORDER BY子句来指定符合条件的记录的删除顺序,举例:DELETE FROM first_table ORDER BY first_column DESC LIMIT 1;
3、数据更新
3.1 UPDATE
格式:
说明:UPDATE 表名 SET 列1=值1, 列2=值2, ..., 列n=值n [WHERE 布尔表达式];
UPDATE单词后边指定要更新的表,SET单词后边指定要更新的列的名称和该列更新后的值,如果想更新多个列的话,它们之间用逗号,分隔开。如果我们不指定WHERE子句,那么表中所有的记录都会被更新,否则的话只有符合WHERE子句中的条件的记录才可以被更新。
举例:# 对test_table表进行更新,对id值为NULL的记录,将该记录的id列的值置为11111,name列的值置为"ANYONE"UPDATE test_table SET id=11111, name='ANYONE' WHERE id IS NULL;
3.2 REPLACE
除了用UPDATE更新表中记录之外,也可以用REPLACE INTO更新,相关的mysql函数有两个:REPLACE和REPLACE INTO,具体用法如下: ```sqlreplace函数,将字符串str中的ordinary_str替换成dest_str
REPLACE(str, ordinary_str, dest_str);
replace into函数,使用replace into插入的数据的唯一索引或者主键索引与之前的数据有重复的情况,将会删除原先的数据,然后再进行添加
REPLACE INTO 表名 (列名1,列名2…) VALUES (列1值,列2值…); ```

若有收获,就点个赞吧
0 人点赞
