我没想出来实际业务场景中,分页查询哪里会用到比如1000这么大OFFSET,有点强行构造一个场景进行优化的意思……
1、分页查询概述
分页查询在业务场景中并不陌生,常见于列表展示时,比如用户列表每页展示10条记录,一共可以展示5页。使用分页查询避免了一次从数据库中全量读取符合查询条件的数据,而是根据前端或者业务需求分页展示,即减少了数据对象在内存中堆区的占用空间,又能减少网络传输中数据包的大小。
1.1 limit用法
实现分页查询,我们可以在SELECT语句中使用LIMIT实现,也可以在业务侧中引入PageHelper插件自动为我们分页(底层实现还是sql语句拼接limit参数)。这一节主要回顾一下Mysql中LIMIT的使用。
SELECT * FROM table LIMIT [offset], rows | rows OFFSET offset
说明:
- 如果指定两个参数,第一个参数指定第一个返回记录行的偏移量(从哪条记录开始查),第二个参数指定返回记录行的数目;
- 如果仅指定一个参数,表示偏移量从0开始,返回指定参数数目的记录;
- 如果第一个参数指定为偏移量,第二个参数为-1,表示查询从偏移量到结果集的结束的所有记录行;
- 如果指定的偏移量大于结果集中的行数,则查询结果为空;
- 如果查询到的结果条数不超过限制条数,则可以全部返回。 ```sql — 查询偏移量为5,一共返回10条记录(如果符合查询条件的记录数目>=10) SELECT * FROM table LIMIT 5, 10;
— 查询偏移量为0,一共返回10条记录 SELECT * FROM table LIMIT 10;
— 查询偏移量为5,到查询结束的所有记录 SELECT * FROM table LIMIT 5, -1;
<a name="ZCcZz"></a>## 1.2 分页查询的问题分页查询中,翻页比较少,即偏移量比较小的情况下,LIMIT子句并不会出现性能问题,即使此时表中数据已经很多了(百万量级)。实际业务场景中翻页比较少的场景还是占大多数的,比如淘宝商品前端页面,一般用户只会浏览前面几页的长篇,一般翻页超过10页很多人就开始不耐烦了。<br />但还有少数场景(我也没想到实际业务场景中哪里需要用到这么大的起始页)的OFFSET会很大(1000, 10000以上),比如这种分页查询语句:```sqlselect * from orders_history where type=8 limit 1000000,100;
这时会发现:随着OFFSET的数量级的增加,查询时间会越来越大,同样的分页查询语句,OFFSET为10000和OFFSET为100比查询时间会高几个数量级。
1.2.1 试验准备
为了验证分页查询在OFFSET很大的情况下查询时间会很慢的现象,我们通过存储过程向数据库表中插入200万行数据来复现。
建表语句:
CREATE TABLE `limit_optimize_tbl` (`id` int(11) NOT NULL AUTO_INCREMENT,`account` varchar(50) NOT NULL,`order_id` varchar(100) NOT NULL,PRIMARY KEY (`id`),INDEX idx_account(account),INDEX idx_order_id(order_id)) ENGINE=InnoDB AUTO_INCREMENT=2000002 DEFAULT CHARSET=utf8
存储过程:
DELIMITER //CREATE PROCEDURE limit_optimize_test()BEGINDECLARE i INT;SET i=1000000;WHILE i<=3000000 DOINSERT INTO limit_optimize_tbl(account,order_id) VALUES('test_123',concat('order', i));SET i=i+1;END WHILE;END//DELIMITER ;
执行存储过程:
call limit_optimize_test();
1.2.2 试验过程
(1)查询数目一定,OFFSET变大
执行如下SQL语句,记录查询时间:
SELECT * FROM limit_optimize_tbl LIMIT 10, 100;SELECT * FROM limit_optimize_tbl LIMIT 1000, 100;SELECT * FROM limit_optimize_tbl LIMIT 1000, 100;SELECT * FROM limit_optimize_tbl LIMIT 10000, 100;SELECT * FROM limit_optimize_tbl LIMIT 100000, 100;SELECT * FROM limit_optimize_tbl LIMIT 1000000, 100;
结果:
- 查询10偏移量:0.022s;
- 查询100偏移量:0.023s;
- 查询1000偏移量:0.024s;
- 查询10000偏移量:0.025s;
- 查询100000偏移量:0.042s;
- 查询1000000偏移量:0.735s。
可以看出,当OFFSET在万以下量级时查询时间都相同,只有当百万量级时才出现了查询时间数量级上的提升。
(2)OFFSET一定,查询数目变大
执行如下SQL语句,记录查询时间:
SELECT * FROM limit_optimize_tbl LIMIT 1000, 1;SELECT * FROM limit_optimize_tbl LIMIT 1000, 10;SELECT * FROM limit_optimize_tbl LIMIT 1000, 100;SELECT * FROM limit_optimize_tbl LIMIT 1000, 1000;SELECT * FROM limit_optimize_tbl LIMIT 1000, 1000;SELECT * FROM limit_optimize_tbl LIMIT 1000, 10000;SELECT * FROM limit_optimize_tbl LIMIT 1000, 100000;SELECT * FROM limit_optimize_tbl LIMIT 1000, 1000000;
结果:
- 查询1条记录:0.038s;
- 查询10条记录:0.025s;
- 查询100条记录:0.022;
- 查询1000条记录:0.025s;
- 查询10000条记录:0.035s;
- 查询10000条记录:0.113s;
- 查询10000条记录:0.855s。
可以看出,当查询记录条数在万以下量级时查询时间基本相同,超过万量级时查询时间才会明显提升。
1.2.3 分页查询慢的原因
创建如下表:
CREATE TABLE account (id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id',name varchar(255) DEFAULT NULL COMMENT '账户名',balance int(11) DEFAULT NULL COMMENT '余额',create_time datetime NOT NULL COMMENT '创建时间',update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (id), // 主键索引KEY idx_name (name), // 二级索引KEY idx_update_time (update_time) // 二级索引) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
执行如下分页查询语句:
select id,name,balance from account where update_time> '2020-09-19' limit 100000,10;
上述sql的语句的执行流程是:
- 通过二级索引树idx_update_time,根据update_time的查询条件,过滤出满足条件的记录,获取记录对应的主键id;
- 第1步中满足查询条件的每一条记录,通过主键id查询主键索引树,然后找到对应的完整列的记录,返回(回表);
- 扫描2中返回的记录的钱100010行,然后舍弃前100000行,返回后面的10行记录,作为最终的查询结果集。
分页查询慢的原因有三个:
- limit offset n语句会先扫描offset + n行,,然后再丢弃掉前offset行,返回后n行记录。当offset值很大时会扫描很多无用的行;
- 如果查询条件不是主键,或者没有走索引覆盖,会有回表的动作,当OFFSET很大时,需要回表的记录太多,也会耗时;
- 即使查询条件的列建立了索引,但是OFFSET很大时会扫描太多的记录,当这些记录占总记录数目的比值超过一定阈值时,优化器会放弃使用索引而使用全表扫描(跟第一点可以合为一点)。
2、分页查询优化
2.1 SQL层面优化
例如优化下面的sql语句:
耗时时间:2.638s。SELECT * FROM limit_optimize_tbl ORDER BY order_id LIMIT 1000000, 10;
执行计划: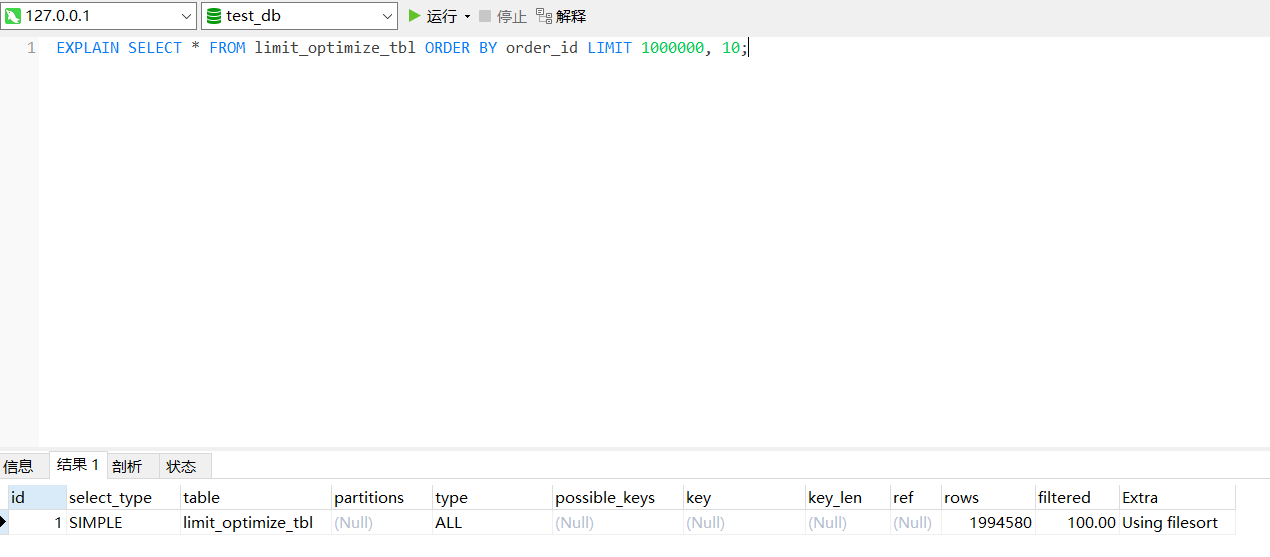
2.2.1 索引覆盖
索引覆盖的概念这里就不介绍了,下面的sql语句就是走了索引覆盖:
而下面语句就没有走索引覆盖:SELECT order_id FROM limit_optimize_tbl ORDER BY order_id LIMIT 1000000, 10;
两条语句的执行计划,从Extra列可以看到,走了索引覆盖的sql语句的执行计划,Extra列为Using index,而没走索引覆盖的sql语句的执行计划,Extra列为Using filesort。SELECT * FROM limit_optimize_tbl ORDER BY order_id LIMIT 1000000, 10;
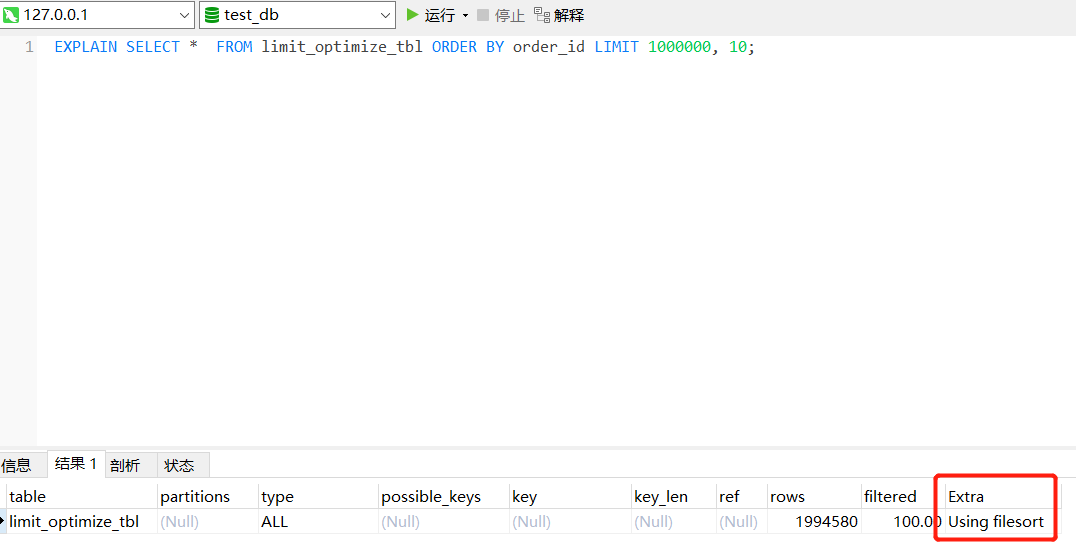
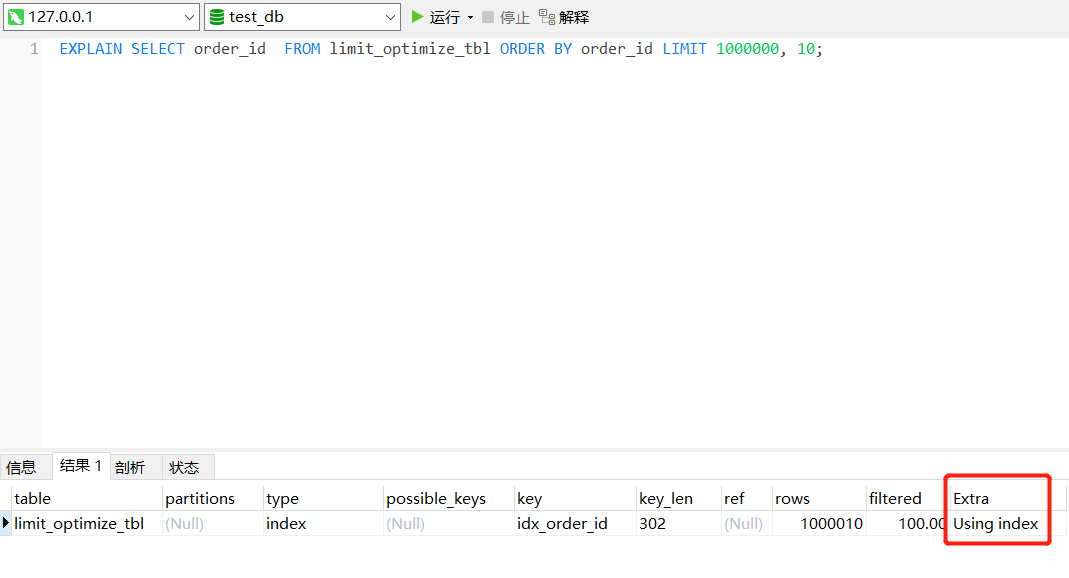
执行时间比较,没走索引覆盖的sql语句耗时2.638s,走了索引覆盖的sql语句耗时0.322s,查询时间缩短87%,效果显著。2.2.2 子查询优化
下面就是用子查询优化后的sql语句:
执行时间跟2.2.1中索引覆盖的时间基本一致,0.325s。SELECT * FROM limit_optimize_tbl WHERE id>=(SELECT id FROM limit_optimize_tbl ORDER BY order_id LIMIT 10000, 1) LIMIT 10;
执行计划如下: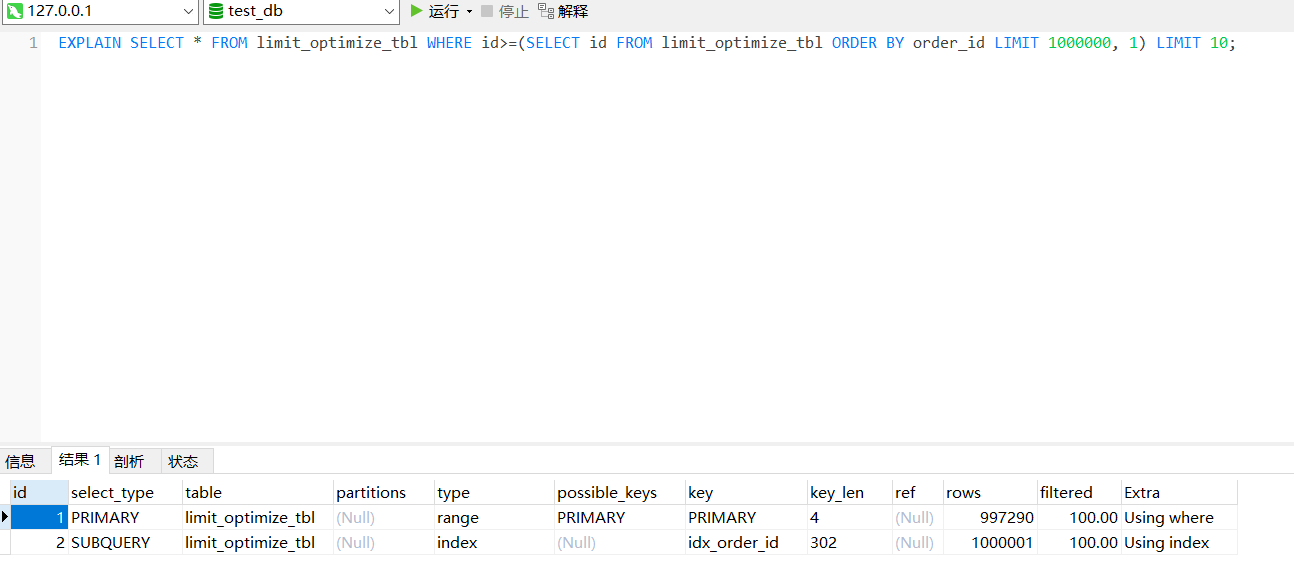
子查询的优化思想是尽量使用主键索引树,而非二级索引树或者联合索引树,避免回表太多次,结合上面的例子说明:
- 子查询:子查询的目的是获取主查询中的起始主键id。order by 条件跟的是order_id,列上有二级索引,查询的列是主键id,也有主键索引,由于二级索引的叶子节点里也会存放主键id,因此子查询仅查询的是二级索引树(无需回表),LIMIT的OFFSET在子查询里做,因此子查询还是要扫描1000000条记录,执行计划中子查询对应的type也是index(扫描索引树);
- 主查询:主查询的目的是查询主键索引树,返回所有列的记录。LIMIT中限制的记录数目在主查询中设置,因此主查询的执行计划的type是range(扫描一定范围的索引记录),这一阶段也同样不需要回表。
相比待优化的分页查询语句,子查询优化的分页查询语句整个过程不需要回表,充分利用了主键索引和二级索引,因此效率较高。但子查询优化有一个限制:主键id至少满足单调递增。
2.2.3 延迟关联
就是通过子查询转换为连接查询,先在索引
SELECT a.* FROM limit_optimize_tbl a INNER JOIN (SELECT id FROM limit_optimize_tbl ORDER BY order_id LIMIT 1000, 10) b ON a.id=b.id;
执行时间跟子查询和索引覆盖的时间接近,0.364s。
执行计划如下: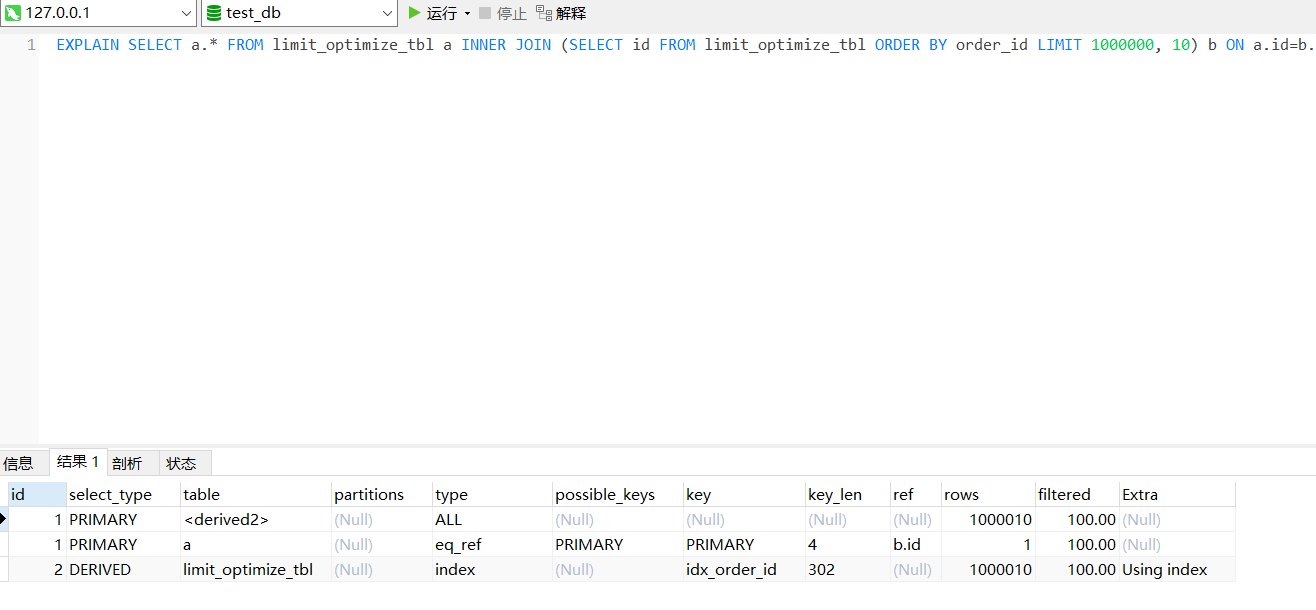
延迟关联和子查询优化的思想是一样的,不同点在于延迟关联可以不要求主键id是单调递增的,且LIMIT参数均在被驱动表的查询里设置,因为连表查询只要驱动表的记录在被驱动表里有就OK。
2.2.4 逆向查询
即如果想查询最后一页或者倒数几页的记录,可以改变顺序查询(之前是ASC,现在是DESC),如下:
SELECT * FROM limit_optimize_tbl ORDER BY order_id DESC LIMIT 0,10;
但是这种场景使用很有限,因为你需要提前知道一共有多少分页才能推算出倒叙排序的OFFSET,建议仅在调到尾页的场景下使用这种方法,因为此时OFFSET肯定为0。
2.2 业务角度优化
也可以从业务角度对分页查询优化,这种方式往往粗暴又有效,就是对用户可以翻页的数目进行限制,以淘宝网为例,使用比较热门的 “连衣裙” 的关键词进行搜索,网站仅仅提供了 100 个数据页,即用户仅能搜索到最多100页的连衣裙商品,如下:
3、PageHelper简述
PageHelper作为业务层的分页查询插件,可以使我们不用编写分页查询的SQL语句,直接在业务层(比如Java代码中)指定分页查询的参数即可实现分页查询。但PageHelper并没有向2.1中那样对LIMIT分页查询语句进行优化,而仅仅是根据分页查询的参数拼接包含LIMIT的sql语句。因此PageHelper中没有对分页查询优化,实际项目中如果需要做2.1节中sql层面的优化,不能使用PageHelper,而需自己在Mapper.xml中编写优化后的LIMIT语句。
参考
数据量很大,分页查询很慢,怎么优化?
如何优化超大的分页查询?
实战!如何解决MySQL深分页问题
PageHelper 分页查询一直有性能问题你知道吗?

若有收获,就点个赞吧
0 人点赞
